我是一个勤快做笔记的人,也喜欢试用市面上的各种笔记工具,当前笔记 3 大件,obsidian、notion、logseq 我都试用过了。可以说他们都各有擅长,上个月我完整地看了几个有代表性的 workflow 视频,有一些特性令我心痒痒的:
1、notion 的 dashboard,可以方便地让人查看各类事项的进度,以及做好随时收集自己看过的书、电影,外出游玩,方便将人的生活拆分成不同的维度,看到会有一种丰满感; 2、obsidian 丰富的插件,将 obsidian 拓展成笔记版的 Emacs; 3、logseq 的 query,logseq 不提倡不停地分不同的文件进行记录,而是每天都在一个页面上记录,但通过内置的 query,或者用户写的 query,对特定内容进行自动化的整理;
但是,notion 数据不能本地存储,obsidian 里的高级玩法也需要用户写代码,如果这样我还不如用回自己熟悉的 emacs,logseq 这种直接进行自动化整理的方式,实际上是将笔记的反人类部分给磨平——但也去掉了笔记的意义,因为人必须得反思,才能进行有效的判断,结果把反人类部分磨平了之后,人容易变成笔记机器,更大概率的患上了笔记松鼠症,而非……会思考的动物了。
受到笔记 3 大件的启发,我开始寻找 emacs 上类似的替代方案,可以做到 notion 的 dashboard,又能实现 logseq 的 query。我也在社区发帖提问, TomoeMami 提到了 org-ql 这一工具。所以,我花了大概几天的业余时间对该工具进行了钻研,期间为了探明 org-mode 的 dynamic block 功能跑到开发者的 github 上提 issue,在社区里发帖,最后还到暗无天日的 github 上询问。我通过 org-ql 了解到 org-mode 的 columnview 功能,然后发现笔记里的 dashboard 完全可以交给 columnview 来完成。感谢在此探索期间,向我提供过帮助的朋友们。
写了这么多,也该分享我现在的笔记方法:
我的笔记分成 4 类:知识类、事实类、项目类、记录类。
- 知识类:以领域区分。比如行业,市场营销等。
- 事实类:影响到某些事情判断的事件、数据。比如,青年的咖啡消费比例,2022年获投案例数量等。
- 项目类:手中正在进行的项目,一般一个项目一个文件,进行长期的追踪和记录。
- 记录类:这主要是记录自己看过的书、电影,听过的音乐,旅游过的地方等。
我为以上 4 类笔记,搭配了不同的流程和形式。
- 知识类:
遇到新的概念,我直接用自己定义的 org-roam 的 capture 模板进行记录。只需要 org-roam-find-node 功能直接输入新名词,然后选择对应的模板,记录下来,同时再笔记内,用 org-roam-insert-node 来创建笔记与笔记之间的关联。
通常情况下,我很少用到 backlink,只有我专门进行回顾的时候,才会启用 backlink。
以下是我设计的 org-roam-capture 模板——因为我发现 org-roam-capture 与 org-capture 行为有区别,前者是在输入了笔记标题之后,才选择笔记模板;而后者则是先选择模板,在进行标题或笔记的记录。
以下是我使用的 org-roam-capture 模板,对应特定分类的笔记,会放在不同的文件夹里,会让人更清晰一些:
(setq org-roam-capture-templates '(
("d" "default" plain "%?"
:target (file+head "%<%Y%m%d%H>-${slug}.org"
"#+title: ${title}\n#+filetags: \n")
:unnarrowed t)
("b" "book notes" plain "%?"
:target (file+head "book/book%<%Y%m%d%H>-${slug}.org"
"#+title: ${title}\n#+filetags: :bookreading: \n\n")
:unnarrowed t)
("c" "company" plain "%?"
:target (file+head "company/company%<%Y%m%d%H>-${slug}.org"
"#+title: ${title}\n#filetags: :compnay: \n\n")
:unnarrowed t)
("i" "industry" plain "%?"
:target (file+head "industry/industry%<%Y%m%d%H>-${slug}.org"
"#+title:${slug}\n#+filetags: :industry: \n\n")
:unnarrowed t)
("m" "marketing" plain "%?"
:target (file+head "marketing/marketing%<%Y%m%d%H%M%S>-${slug}.org"
"#+title: ${title}\n#+filetags: :marketing: \n\n")
:unnarrowed t)
("p" "project" plain "%?"
:target (file+head "project/project%<%Y%m%d%H>-${slug}.org"
"#+title: ${title}\n#+filetags: :project: \n\n - tag ::")
:unnarrowed t)
("r" "reference" plain "%?"
:target (file+head "<%Y%m%d%H>-${slug}.org"
"#+title: {$title}\n%filetags: reference \n\n -tag ::")
:unarrowed t)))
- 事实类:
事实类笔记内容会比较零散,通常也不适合单独记录在单个文件里,而且事实类笔记往往容易打脸,但它也需要存在,以便我在做咨询 PPT 的时候,对其中内容进行引用。
针对这种比较零散的笔记,我的做法是,把它们一股脑的放进一个名为 readlog.org 的文件里,每一条信息是就是一条 heading,然后添加 tag 进行区分。
最后,我再用 org-ql-search 功能,加上它的 query 语法,把我关注的 tag 全部抓出来之后,再保存到 org-ql-view 视图里。这样,当我需要查阅时,只需要打开 org-ql-view,然后再唤出对应的视图就行——不过,其实也没那么麻烦,我相信大部分 emacs 用户打开了 buffer 之后是不关的,我也是,所以唤出一次之后,只需要进入 buffer-list 里搜索对应的标题即可。关于 org-ql 的 query 语法,我粗略的翻译了一下,也发到社区里了,org-ql 讨论帖。
针对我日记中的一些记录,我也是这么处理的,我这个人比较重视朋友,所以说,哪一天跟哪些朋友相聚,都进行记录,我现在的做法是,在对应的 heading 旁边添加「朋友」这个标签,这样子通过 org-ql 就可以一下子检索出来,直接保存成视图,就可以知道一段时间里,分别和哪些朋友相聚。
- 项目类:
我手中会并行多个项目,也面向不同的行业,各自有各自的进度。
一个项目对应专门一份 org 文件。在这里面我会以项目日志的方式记录项目进度,总结项目中可能出现的问题,草拟一些对应的方案。为了方便自己回顾不同的项目情况,我比较需要一个 dashboard 让我可以快速的统揽项目的状况,进入到对应的笔记。这时候如果有 dashboard 最为方便。
我用 org-mode 的 columnview 来完成这一工作。不采用 org-ql 的原因是,它在输出对应的表格时,无法识别 org-mode 的链接语法,另外,不像 columnview 可以添加 :file 语句,可以直接调用另外一个文件里的内容。
由于我是用单一文件来记录一个项目里发生的所有事情,因此就不适合用 org-roam 的双链来对不同节点的关联。
在此,我运用 org-super-links 来创造节点与节点之间的关联——
比如说,我的 项目.org 里,会分别日志(log),和下一步(任务),通常是写完日志之后,确定了下一步行动,因此可以用 org-super-links 来创建日志与任务之间的关联。
- 记录类:
我会记录自己阅读过的书,看过的电影,和听过的音乐,以及旅游。
我会混用 org-capture 和 org-roam-capture,来记录自己阅读过的书籍——
首先,我用 org-captuer 将我新阅读的书添加到我的书籍阅读记录的文件里,我设计了好几个 property,用来记录对应的状态。如果这本书有值得制作笔记的部分,我会用 org-roam-capture 来新建一个笔记。
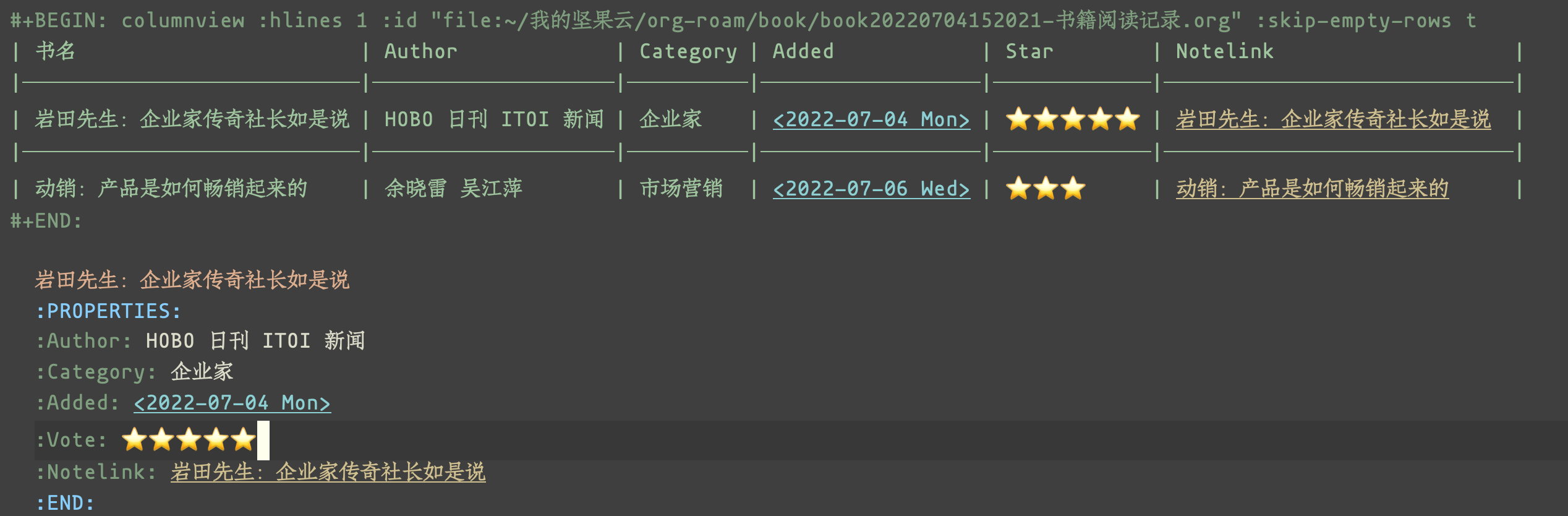
电影、音乐、旅游等记录,都采用类似的方法。
总结
哪些笔记应该零散记录,哪些笔记应该集中记录,一直是知识管理界,笔记界的讨论话题。
我认为,世界上的笔记类型很多,当它对个人而言只是一个个零散的点时,它就应该是一个个零散的点,之后有机会再把它们串起来。
目前这套笔记方法,我认为优点就是零散笔记,有了专门集中的地方,而且通过工具来检索和集中展示;而不是用 org-roam 原有的一个文件一条笔记的方式,后者会令文件过度破碎,反而在检索和检阅的层面增加了很大的难度。
在形成这个笔记方法的过程中, 我体会到 emacs 的自由度,emacs 把自己当做方法的工具,只要有想法,即便不懂 emacs-lisp 来调用高端复杂的功能,但通过搭积木和简单的语法,也能创造出适合自己的工具。

