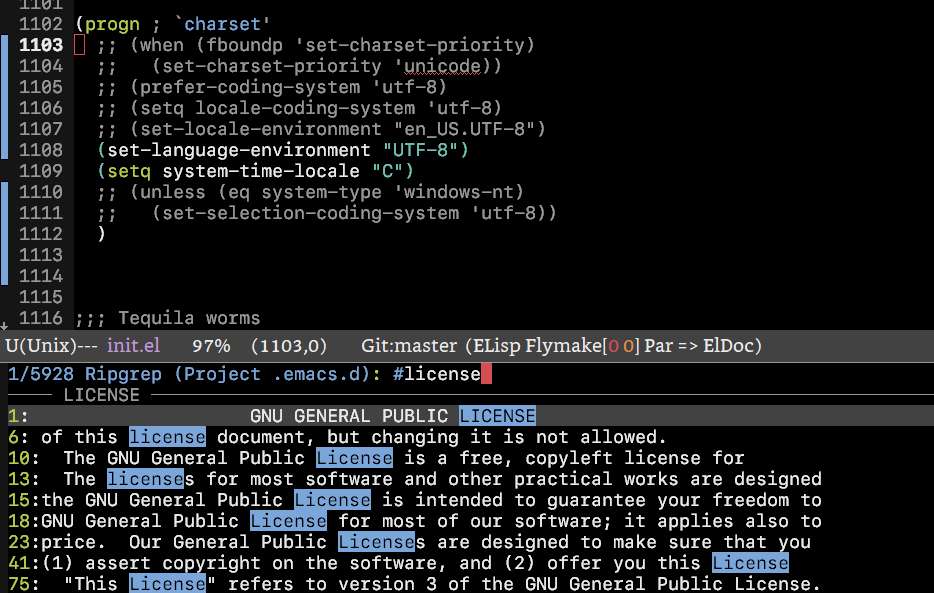
一直以来,在 Windows 系统下,如果不做任何的编码设置,emacs 经常会弹出对话框让你选项合适的编码系统。
之前一直使用的编码设置是这样的:
(when (fboundp 'set-charset-priority)
(set-charset-priority 'unicode))
(prefer-coding-system 'utf-8)
(setq locale-coding-system 'utf-8)
(setq system-time-locale "C")
(unless (eq system-type 'windows-nt)
(set-selection-coding-system 'utf-8))
最近看到 Reddit 上讨论这个问题,其实只需要下面这个设置就可以, 实测确实可行
(set-locale-environment "en_US.UTF-8")
(setq system-time-locale "C") ;; 这个是为了在 org mode 中用英文显示日期,默认是中文
但 doom 目前是这样配置
但是 Eli 并不推荐在 Windows 系统下设置 locale-environment 为 UTF-8, 大家怎么看?
(set-locale-environment "en_US.UTF-8") 和 (set-language-environment "UTF-8") 到底有什么区别?
3 个赞
SPQR
2
大部分情况下这样设置应该没啥问题,但是很多原生windows程序不是用unicode编码,而是用系统的locale编码,比如ripgrep在中文locale下面返回的数据是gbk编码,emacs如果全部强制utf-8会导致返回结果中中文乱码,这时候就需要改process-coding-system-alist。。
我这边倒是暂时还没遇到过设置为 UTF-8 后 ripgrep 不能用的情况。
windows上我也没设置utf-8,default-process-coding-system显示(undecided-dos . undecided-unix)。
consult-ripgrep只需要设置:
(add-to-list 'process-coding-system-alist
'("[rR][gG]" . (utf-8 . gbk-dos)))
就可以了,不过如果启动进程通过cmdproxy的话就需要设置cmdproxy的编码,比如project-find-regexp配置用ripgrep搜索(setq xref-search-program 'ripgrep),就需要临时改变下编码:
(defadvice xref-matches-in-files (around my-xref-matches-in-files activate)
(let ((cmdproxy-old-encoding (cdr (assoc "[cC][mM][dD][pP][rR][oO][xX][yY]" process-coding-system-alist))))
;; 注意project search是xargs实现的,会向rg先发送文件列表,因此对输入编码有要求
(modify-coding-system-alist 'process "[cC][mM][dD][pP][rR][oO][xX][yY]" '(utf-8 . utf-8))
;; 检查是否含中文
(if (chinese-word-chinese-string-p (ad-get-arg 0))
(let ((xref-search-program-alist (list (cons 'ripgrep (concat (cdr (assoc 'ripgrep xref-search-program-alist)) " --pre rgpre")))))
ad-do-it
)
ad-do-it)
(modify-coding-system-alist 'process "[cC][mM][dD][pP][rR][oO][xX][yY]" cmdproxy-old-encoding)))
其它就主要进程通信有编码问题,其它我没遇到过,以前有.session的文件提示编码后来改为保存为utf-8就没问题了。
3 个赞
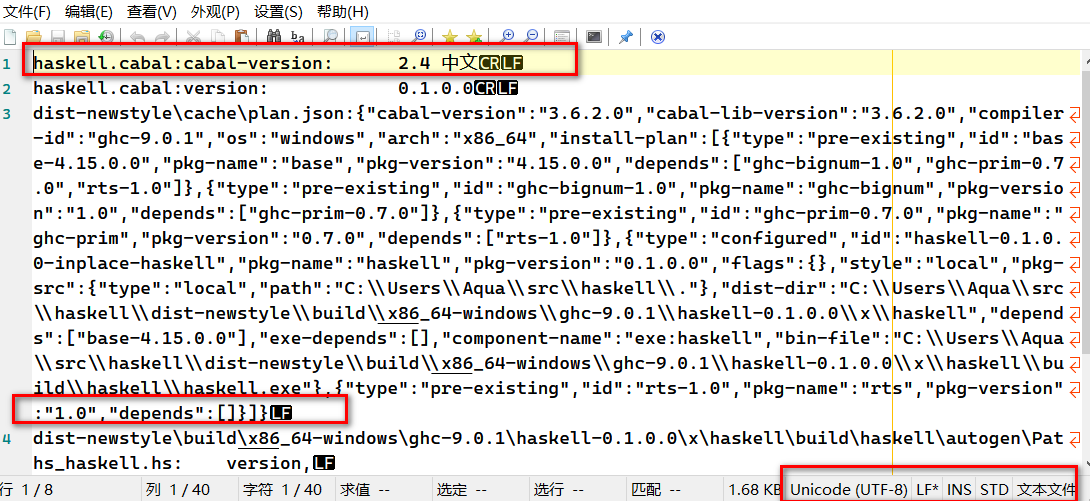
我这边 rg 倒是都正常的,在 haskell 的 REPL 下无法打印中文字符.
λ> print "hello"
"hello"
λ> print "中文字符"
"\20013\25991\23383\31526"
λ>
我按你的方法设置后,REPL 都没法启动, 请问有办法知道进行到底用了什么编码吗?
(add-to-list 'process-coding-system-alist
'("[gG][hH][cC][iI]" . (utf-8 . gbk-dos)))
PS: haskell 中文乱码的问题不是 Emacs 设置问题,是 hasekll 本身的问题,因为它在外部终端就不能输出中文。
我在windows上的设置是这样的,试过其他的设置有些情况还是会出现中文乱码,比如 M-x shell打开cmd。
(prefer-coding-system 'utf-8)
(set-default-coding-systems 'utf-8)
(set-terminal-coding-system 'utf-8)
(set-keyboard-coding-system 'utf-8)
1 个赞
你这个设置确实可以解决 shell 下面乱码的问题。
可以先cmd里运行如rg 123 >> 123.txt,不过这样分不出来是utf-8还是ansi,在能匹配123的那行加上中文,输出就包含中文了,这样再看123.txt的编码就知道了。
用你的方法 在 CMD 里面试了下,我这边的 rg 搜索结果是 utf-8 编码
下面这个就是执行 rg version >> 123.txt 的结果
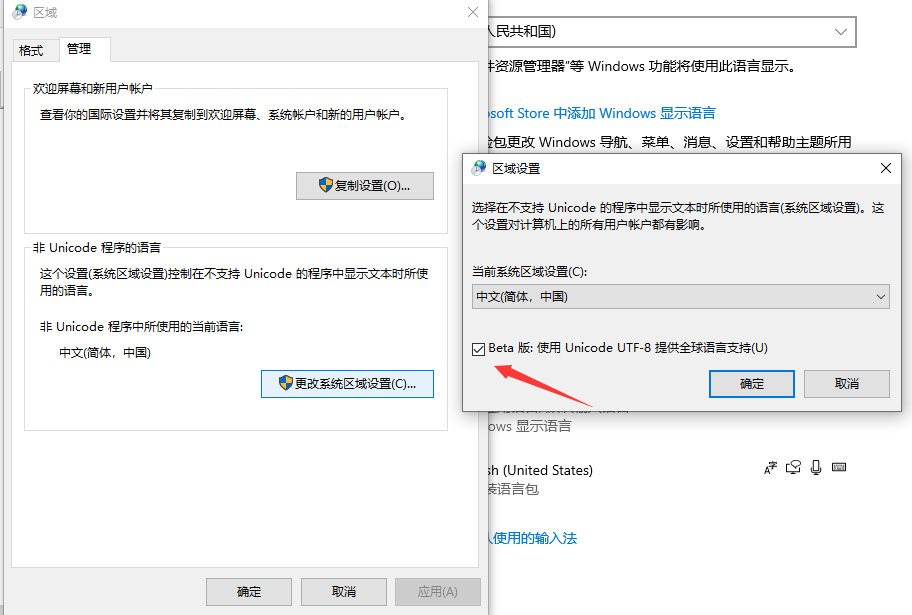
我直接把WIN的系统编码设成了UTF-8了, 其他貌似没有特别的配置就可以了, 但是有一些老的软件中文会乱码, 把软件改成英文语言就行了 
以前我也开这个 Beta 版 UTF-8.
现在不开了。
1 . 是因为有的老程序会乱码
2. 是因为有的文件我编辑过后,其他同时打开会乱码。因为他们没打开这个选项。
确实有些地方不便,比如别人传过来的压缩包,直接解压中文会乱码, 只能在WSL下用unzip -O gbk来解压。。。
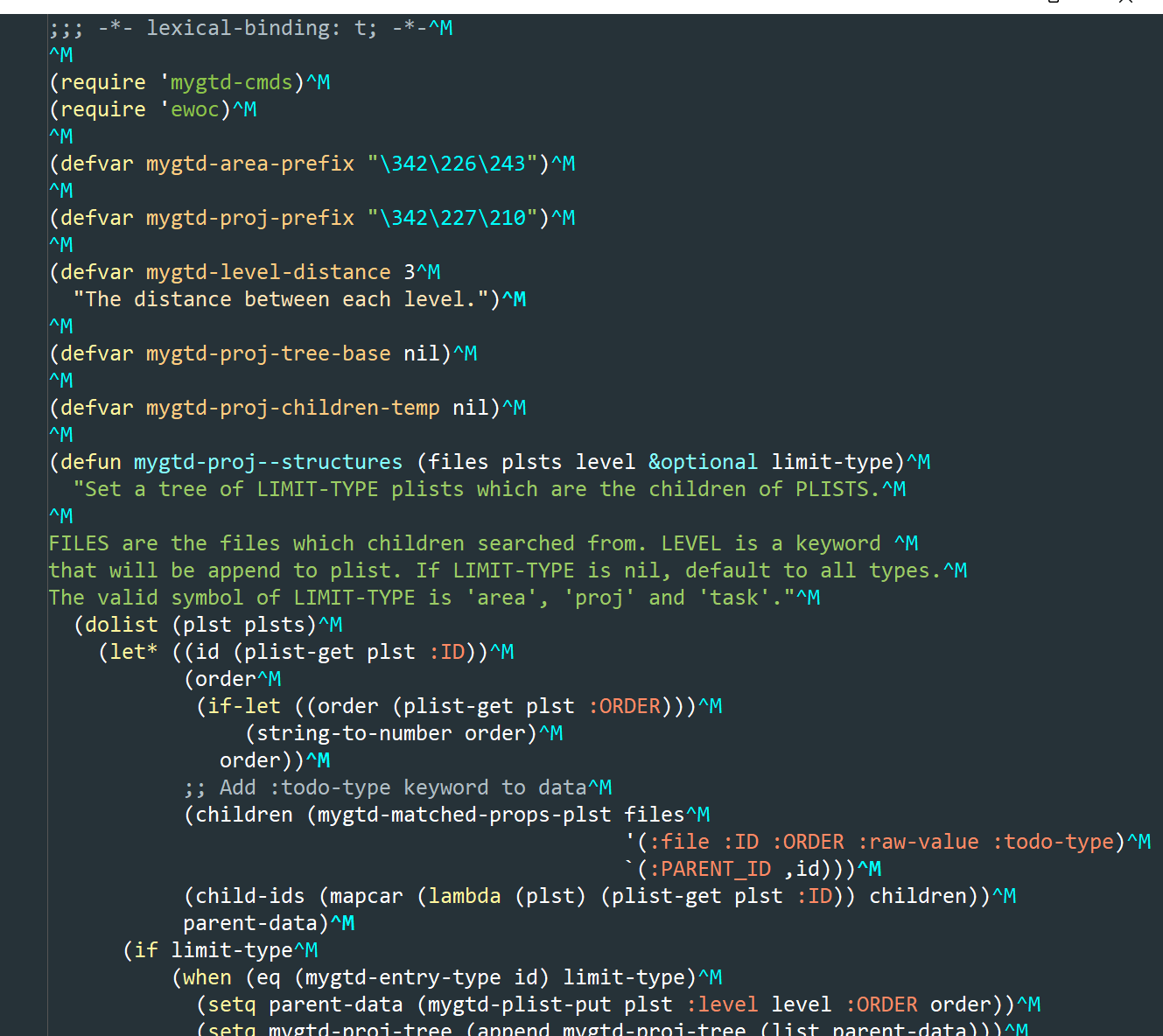
最近在 Windows 系统上使用 Borg 来安装第三方包的时候,也遇到了编码问题。添加包后 .gitmodules 文件的编码会由 dos 格式转为 unix 格式。结果就是出现一堆的 ^M 回车符。
Borg 作者认为这个可能是 Emacs 的 Bug,目前已经通过使用 with-temp-buffer 包裹局部绑定临时解决。
在 Windows 上用 Borg 的朋友,注意升级到最新版。
Kinney
14
用了lz的配置,变成这个样子了,原本是正常的 
删除配置,重启都不行,不知道怎么恢复了。能不能帮忙看看
是啥平台啊? 这个^M 是 Windows 系统的 CR 回车符,Windows 行尾为 CRLF,Unix 系统是 CR
Kinney
16
windows
我就执行了
(set-locale-environment "en_US.UTF-8")
(setq system-time-locale "C")
这两行配置。
Kinney
17
我自己原本关于编码的设置有这些:
(setq bookmark-file-coding-system 'utf-8)
(setq magit-git-output-coding-system 'utf-8)
(prefer-coding-system 'utf-8)
有 Git 版本控制的话,直接恢复就行。
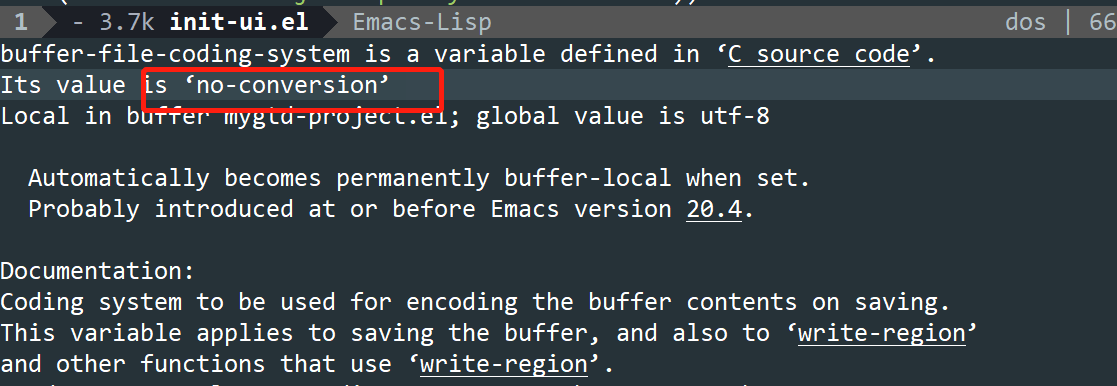
是因为你当前的 buffer 用了 unix编码,你C-h v 看看 buffer-file-coding-system 这个,当前是不是编码为 utf-8-unix?
C-x RET f 可以改编码,改为 带 dos 的就是 Windows。
但我首页的配置,不应该改变文件编码的。可能只是显式展示了而已。
我 Windows 下文件如果用 UTF-8 的话,是这个
buffer-file-coding-system is a variable defined in ‘C source code’.
Its value is ‘utf-8-dos’
Local in buffer init.el; global value is utf-8
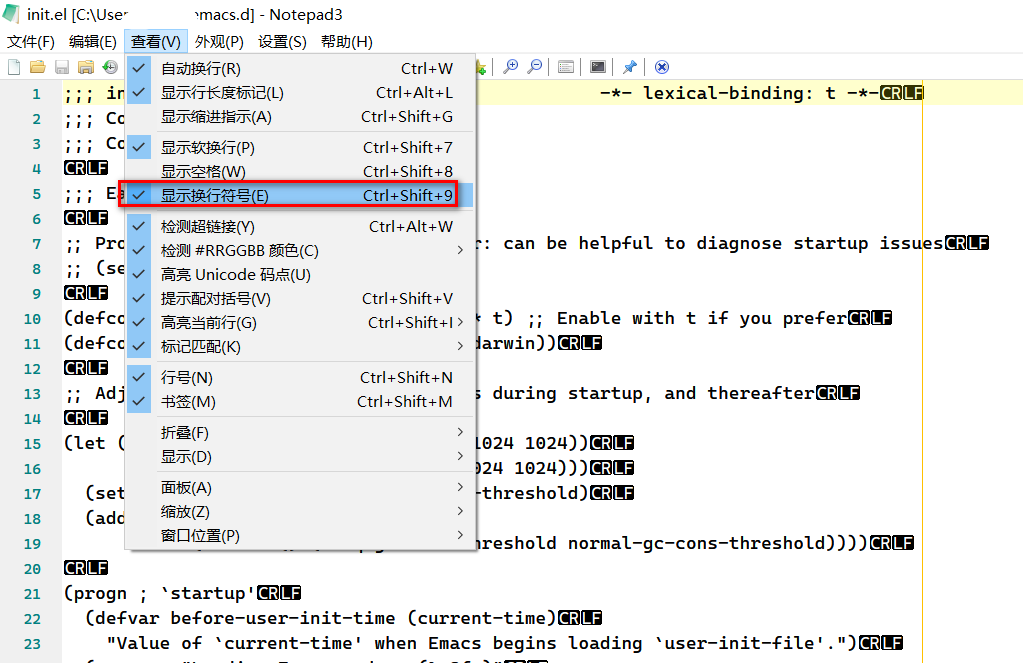
如果你安装了 notepad3 ,可以看到文件行尾:
Emacs 中我不知道怎么看到。
你把文件拷贝出来,执行 C-x RET f 选择 utf-8-dos 试试看。