我写了个基于 sdcv 的词典 Use sdcv and crow-translate instead playwright. by manateelazycat · Pull Request #3 · ginqi7/dictionary-overlay · GitHub , 当 sdcv 查不到时, 用 crow-translate 来做一个保底单词查询。
3 个赞
大家快来更新新版本。猫哥改成 sdcv 以后无比丝滑。
EAF Browser + Popweb + eww + dictionary-overlay , 简直是英文文章学习的最佳流程:
- EAF Browser 查找资料, 在 EAF Browser 中执行命令
eaf-py-proxy-insert_or_render_by_eww转换成 eww 模式 - 在 eww 模式中执行
dictionary-overlay-render-buffer命令, 开启 dictionary-overlay - 遇到不懂的单词自动调用
popweb-dict-bing-pointer弹出翻译并同时做生词标记dictionary-overlay-mark-word-unknown, 具体参考我的小函数
dictionary-overlay 这个插件最好用的地方是, 一次弹出翻译, 以后不管看什么文章都可以自动显示生词的翻译, 不用一个一个的再次去查单词翻译, 节省了大量时间。
12 个赞
这个project非常有意思,也是能极大提升程序员工作效率的利器。
不过对于英文比较好的人(可以无障碍阅读英文文献)但是会遇到文本中出现不认识的单词(熟词僻义)以及常用词组合成了不认识的短语的情况,本插件目前遇到这种情况应该还是有所局限的。
针对这两种情况,我有如下的建议:
- 针对一个被翻译的单词,提供两个命令,跳转到本单词的上一个和下一个释意。
- 选中一个区域(主要是短语)后,调用翻译,如果词典里查不到就调用在线翻译(同时在线翻译也可以切换不同的释意)。
至于后续的工作流,如自动添加到生词本等,都是非常好的。
我目前遇到不认识的熟词和短语,都是先选中然后自动调用eww或者xwidget去谷歌搜索这个单词,然后明白释意以后调用org-capture来记录这个单词/短语和它的上下文句子写入。
如果能结合楼主的这个插件,我的工作流还有很大的优化空间。
删除了dictionary-overlay目录,重新下载回来是不是就更新了
默认是sdcv查词?也是需要快速修改释义的办法(个人对多释义跳转持保留意见,有的词词典里会有十几个释义,遇到这种情况似乎前面提的popweb是更好的方法,虽然我还没解决popweb弹出窗口空白的问题,所以更倾向自己查询后修改释义

由于设计偷懒,把用户数据文件都放在了项目目录下,导致可能代码更新用户数据丢失的问题。
新的提交把,用户数据的目录换位置了。可以通过变量 dictionary-overlay-user-data-directory 设置 默认值为:“~/.emacs.d/dictionary-overlay-data”
更新前记得备份一下原项目目录(dictionary-overlay)下的用户数据。
经过猫哥的重构。新的版本,不在需要复杂的playwright和Chromium了,大大优化了查询性能。
当前的逻辑是默认使用本地 sdcv,如果未找到,则会使用 crow-translate 或者 google-translate 进行在线查询。
mac用户估计只能使用 google-translate,可以去 README 查看如何安装。
2 个赞
反馈下google translater安装
正克隆到 '/tmp/install-google-translater8BCPV'...
正在获取对象: 4
正在获取对象: 131, 完成.
python3 -m build
/usr/bin/python3: No module named build
make: *** [Makefile:8:dist/google_translate-1.0.0-py3-none-any.whl] 错误 1
哦哦。手动安装一下 build : pip install build,我忘了这个不是它自身附带的。
1 个赞
接下来可能会想要完成以下两个功能:
-
使用 nltk 来进行词形还原,这样单复数,动词的不同时态都可以展示出来。调研表明,nltk 词形还原可能不准确(例如无法区分是动词的ing 还是形容器)。不过在我们这个应用的场景,并不需要准确。通常一个词,如果不认识。通常名词,形容词,动词都不认识。因此可以通过 nltk 抽出词干。然后当前buffer中的单词只要词干和生词本中的单词一致,都可以翻译出来。
-
不同词义的选择和修改。默认情况下,自动翻译生词,如果对生词的词义不满意。可以提供一个命令,查出当前单词的所有词义,让用户自己选择。
1 个赞
词干提取 + 词形还原
在自然语言处理领域,对单词有两种处理方式:
- 词干提取 – Stemming
- 词形还原 – Lemmatisation
词干提取,通常会使用算法去掉或转换单词的后缀,提取单词中的主干部分。提出的过程不够精确,可能返回的不是一个有效的单词 例如 apple → appl 。但它的优点是,它可以把一个单词的动词、名词、形容词抽取出一个通用的词干
词形还原,会把一个单词还原到最基础的形态,例如 drove → drive ,但需要指定单词的词性才能准确转换。例如 drove 在词典里存在动词和名词,只有你指定它的词性为动词,才会还原成 drive
在我们这个应用当中,可以选择使用 “词干提取”,它可以把一个单词的动词、名词、形容词抽取出一个通用的词干。而通常,如果我们不认识一个单词,那么很可能它的动词,形容词都不认识。另外就是,它足够简单。不像词形还原,还需要先分析单词的词性。
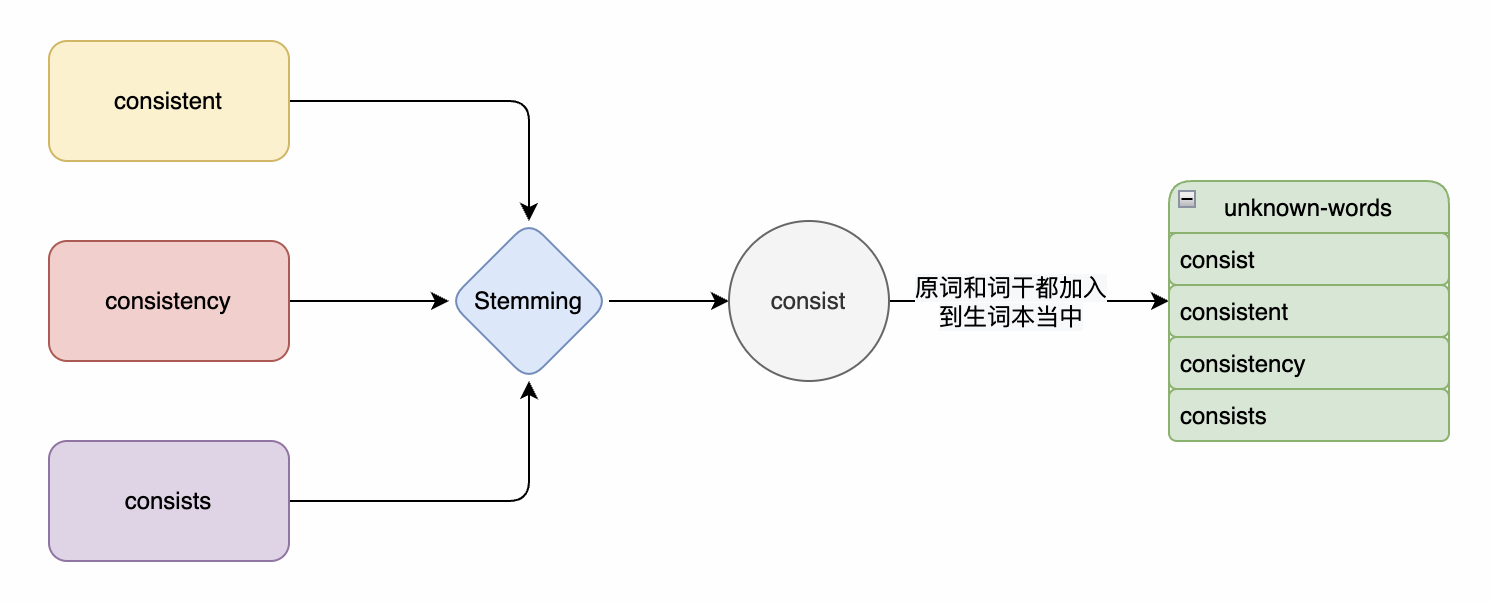
因此,我们可以每次添加生词时,把单词与它的词干都加入到生词本当中。 当需要渲染当前buffer 时,遇到单词或者单词词干在生词本中,就翻译它的结果。示例:

3 个赞
谢谢,找到用户数据啦,非常友好的txt,实在是太棒啦
行间翻译不好实现的话,有没有可能这样,标记生词后突出显示 同时待处理buffer右侧有一个能一键显隐的窄条buffer,用于显示生词和释义 类似
apple
苹果
pear
梨子
这样的,这样既可以解决显示释义的问题,同时也能在这个buffer里快速修改释义?
建议不在原文显示释义的原因是
单词识记一般是在句子语境中反复出现记下的,每次遇到最好是先猜一下再看释义确定。
如果每次都直接显示出来结果就起不到加强认知的作用了
能够设置个阅读模式开关就好了,这样就不用处理 UI 问题了,只处理 buffer。
最好是只渲染当前 paragraph,避免每次都渲染整个buffer带来的性能问题。
楼主这个插件的目标是, 阅读英文材料的时候, 对那些记不住的单词快速提示, 达到快速阅读原文的意思, 目标是优先知道文章的意思。
这个插件不是专门学英文单词的, 也不能替代英文单词学习, 但是有时候先理解文章大意比彻底搞懂每个单词更重要。
而单词所谓的记忆无非就是见的多了, 记不住原因还是见得次数不够多, 见得多才是长久记忆的方法, 局部强化记忆, 短期有效果, 长久不用还是会忘记。
2 个赞
是的,该插件的主要目的是为了避免不认识的单词反复出现,反复调用词典查看。Emacs 当前调用词典本身是很方便的,只是很容易打断阅读思路。
该插件让一次翻译,多次提示成为可能。可以更流畅的阅读。并且有中文标记的单词,可以有意识的去注意两眼,加深记忆。
但它不是一个专业的记单词的工具。
关于记单词的流程,我个人推荐:当你查询单词时,直接获取上下文和释意,保存起来,然后同步到anki, 通过anki 的记忆曲线来记单词。之前我是这么干的,后来人懒了,也就没有专门记单词了。
当完成上述的,“词干提取”和”“翻译修改”两个功能之后,可能短期不会有什么大的新功能添加进来了。需要多的阅读,用起来才是关键。
当然欢迎大家pr 添加认为有意义的功能,以及给我的代码提意见让我学习学习。
1 个赞

我就是从蒙哥阅读器第一次接触的透析阅读。
不过现在我不用iPhone和iPad了,macOS虽然也能从 App Store 下载安装也懒得折腾了。
嗯我上学那会儿买过关于“透析法”的书,作者伍君仪和恶魔的奶爸,虽然有人恶评,但效果很好。观点同懒猫:多读多看。
同道中人,我还买过魏剑峰的没有单词是一座孤岛,不过现在都忘得一干二净了。 ![]()
仅仅是讨论哈
一键显隐(即LS说的阅读模式)、侧边显示也同样可快速提示
同意不是专门学习单词的,所以很希望它保持这样而不是成为查背单词的专门软件
但是,如果是快速弄懂文章内容,不应该直接翻译左右对比么 ![]()
EDIT:回复完了发现LS也回了,也适用,就不单独开楼了
我个人是用其他软件背的,因此发现LZ提供了单独的生熟词表非常高兴,因为可以单独导出,需要解释一下我说的是在阅读中加强认知,而非专门记忆单词,还是有区别的,当然我只是建议哈,目前功能已经满足了,开心撒花~~
1 个赞