最近经常经常进行文本内容以及文件的搜索还有文件的批量修改等,日常简单的搜索已经满足不了自己的需求,于是花了一点时间了解了并操作了一些知识。大家对于学习正则表达式有什么吗?各种类型的正则表达式emacs风格的,perl, python, java,.net等都有自己的正则表达式,有时候感觉容易搞乱掉。
1 个赞
有本叫什么精通正则表达式的书看着不错,虽然名字听起来很水。
一本书《精通正则表达式》Yahoo工程师写的,非常不错。
学完以后,配合 re-builder 这个插件多练习,实践出真知。
4 个赞
1 个赞
自己写一个正则engine就会了
正则表达式一般有两种: POSIX和PCRE( Perl Compatible Regular Expressions),后者被广泛使用。虽然每个语言的正则写法有一点不一样,但是大致原理都差不多。我平时使用用 visual-regexp.el 来测试正则表达式,这个lib使用的是PCRE标准的,写完以后大多数都直接用于生产项目中。
而 rebuilder 一般用来写elisp的正则。
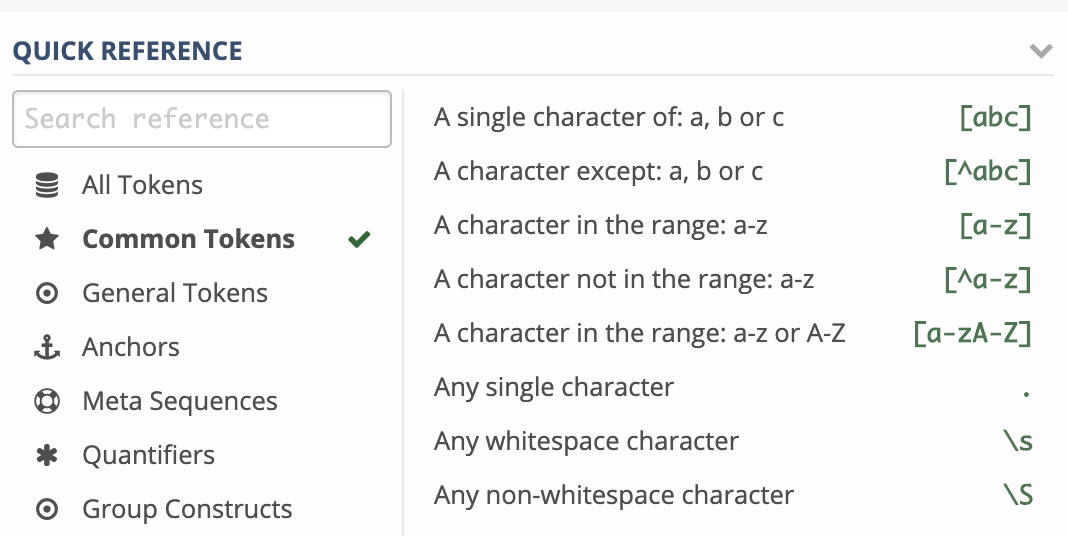
学会基本原理才是王道。 regex101.com 里面有一个表,学会这些基本就够用了,再复杂的可以上网查找,或者使用Emacs插件去辅助写正则(复杂的正则如果没有可视化方法编写会非常痛苦)。
11 个赞
只是用的话完全没必要。
使用手册: https://www.regular-expressions.info
可视化正则表达式: https://regexper.com
source code: Jeff Avallone / regexper-static · GitLab
1 个赞
你猜他在干嘛?
— My reply:
I am guessing you are try to find this string
lkjciidsofwopvqi-something
in this string long string
flkjciidsofwopvqi-something
But I got:
Debugger entered--Lisp error: (invalid-read-syntax ") or . in a vector")
read(#<buffer *scratch*>)
elisp--preceding-sexp()
elisp--eval-last-sexp(nil)
eval-last-sexp(nil)
funcall-interactively(eval-last-sexp nil)
call-interactively(eval-last-sexp nil nil)
command-execute(eval-last-sexp)
Looks like I am missing some context here.
This is my learning:
- matches two or more blank lines in sequence.
(re-search-forward "^\n\\{2,\\}")
- match TODO
(re-search-forward "\\[TODO\\](\\([^\\)]+\\))" nil t)
- match UUID
(re-search-forward "PDFNAME::\\([a-zA-Z0-9 \.\_\,\-]+\\)\.pdf - " nil t)
- match page number
(re-search-forward "PAGENUM::\\([0-9]+\\)::END" nil t)
- match secrete
(re-search-forward (concat arg "::\\(.*\\)"))
- match @dfn{xxx}
(re-search-forward "@dfn{\\([^}]+\\)}" nil t)
- match end sentence
(re-search-forward "[\.,;:!\?]" end t)
If you know python: and interested in nCoV:
overall_information = re.search(r'\{("id".*?)\]\}', str(soup.find('script', attrs={'id': 'getStatisticsService'})))
province_information = re.search(r'\[(.*?)\]', str(soup.find('script', attrs={'id': 'getListByCountryTypeService1'})))
area_information = re.search(r'\[(.*)\]', str(soup.find('script', attrs={'id': 'getAreaStat'})))
abroad_information = re.search(r'\[(.*)\]', str(soup.find('script', attrs={'id': 'getListByCountryTypeService2'})))
news = re.search(r'\[(.*?)\]', str(soup.find('script', attrs={'id': 'getTimelineService'})))
if you intersted in bash
find xxx from grep_xxx
$(grep -oP '(?<=aoa_)[0-9]+' tmp)
inspired by @manateelazycat
why github is unhappy with rep name regexp? Possible related to their reg engine?
-
oh my god, why regexp is everywhere…
-
proudly power by org-mode
根据我自己的理解:
一般日常使用的 “正则表达式” 实际上就是一种描述 “正则语言” 的表达式(或程序语言).
什么是正则语言呢:

(这幅图里面的 regular expression 实际上指的是 “正则语言”, 是满足一定要求的句子的集合)
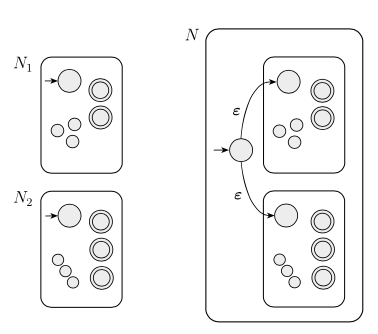
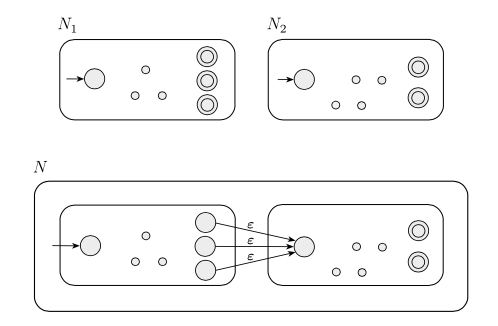
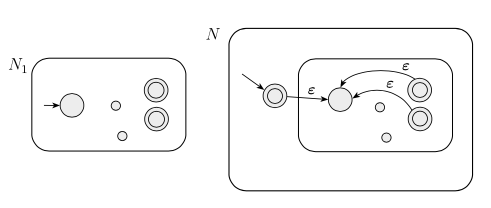
上面这幅图中用到的三个运算的定义如下:

(上图中的x, y都表示句子. xy不是乘法, 而是连接: 如果 x = “abcde”, y = “fgh”, 则xy = “abcdefgh”)
你看到的各种版本的正则表达式虽然各不相同, 但是他们实际上都在描述上面提到的正则语言. 由于正则语言的定义是十分简单的, 所以实际上, 只需要实现Union, Concatenation, Star三种基本的运算, 就相当于实现了正则表达式. 除了这三种运算之外的部分, 都相当于是语法糖(即使你不学也可以通过这三种运算构造出来等价的表达式).
我也比较赞同实现一个正则engine的说法, 知道原理之后, 大概花1-2天就能写出来. 正则engine一般通过模拟 非确定有限自动机 进而正确识别正则语言中的句子.
上面提到的三种运算都可以对应到对于有限自动机的操作:
Union N1 and N2
Cancatenation N1 and N2
Star of N1
如果你希望深入学习, 可以阅读Michael Sipser写的《Introduction to the Theory of Computation》这本书
上面这些概念可以帮你分清主次, 应该可以解决你的问题. 甚至进一步的, 可以让你认识到正则表达式的局限性, 帮你判断自己的需求是否能够使用正则表达式完成.
7 个赞
我找了个中文的
要注意看的是 实际世界当中的正则表达式
2 个赞
我靠,我只能说牛逼。。。。直接看不懂了
 我说怎么这么眼熟,上学期刚学完这节课。)像我前面说的,如果只是想用的话,简单易懂的新手教程更有用
我说怎么这么眼熟,上学期刚学完这节课。)像我前面说的,如果只是想用的话,简单易懂的新手教程更有用
楼主只是学正则去处理数据,没必要花时间看理论或者写一个什么engine
3 个赞
这是高手。。。
我记得我学这个的时候。。。
概要
I like.
thanks for this useful information
I will try my best
Thompson NFA is so fast!
we don’t know what he wants.
Would like to share what you learn? I want ask questions.
In case someone wnats to learn:
Do you know what this reg is searching for?
一个实时的调试环境对于书写正确的正则表达式会有帮助,这里有个 Python 的: https://pythex.org/ 。
当然, Emacs 中已经内置了这样的功能: M-x regex-builder ![]()
UPDATE: regex-builder 是 re-builder 的别名,如果没有试试 M-x re-builder 。
1 个赞
找不到这个哎
那试试 M-x re-builder ,刚注意到 regex-builder 是一个 alias ,旧版本中可能没定义。