[2024-12-16 周一 11:53]
语言模型可以让造句更加符合习惯,参考V2EX的这个帖子,没有语言模型的情况下基本就是胡乱组词。
语言模型和输入方案是解耦的,可以使用自己习惯的rime-ice/rime-frost等方案,然后:
下载模型
在LMDG的发布页下载模型。
模型文件版本说明:v是版本号,n是模型级别,m是百兆尺寸
文件大小 2级模型 3级模型 100M v1n2m1 v1n3m1 200M v1n2m2 v1n3m2 300M v1n2m3 v1n3m3
这里的模型级别指训练时着重训练的几个字:
多级 n-gram 语言模型 在大规模数据的支持下,我们采用了 n-gram 模型进行多级语言建模。具体包括了 unigram(单字模型)、bigram(双字模型)、trigram(三字模型)以及更高级的四字模型。
个人使用可以用n3,如果电脑性能不佳感觉卡顿,可以切换到n2(在作者的另一个方案中,上传有v3n2的模型)。
更新配置文件
找到使用的方案
打开你的Rime配置文件路径/用户文件夹,将下载好的模型文件 amz-v*n*m*-**.gram 放到其中。这里我下载的模型是 amz-v2n3m1-zh-hans
Windows上可通过右键托盘小狼毫图标-用户文件夹打开(一般为 %AppData%\Roaming\Rime );MacOS上一般为 ~/Library/Rime 。
然后打开你使用的配置文件 default.custom.yaml (或 default.yaml ,当两个文件都存在时以 custom.yaml 为优先),寻找其中 schema_list: 下面的内容。
比如我的 default.custom.yaml 就是这部分:
patch:
schema_list:
- {schema: rime_frost_double_pinyin_flypy}
说明我只用了 rime_frost_double_pinyin_flypy 这一个方案。
以默认的 default.yaml 为例,它是这样的:
schema_list:
# 可以直接删除或注释不需要的方案,对应的 *.schema.yaml 方案文件也可以直接删除
- schema: rime_frost # 白霜拼音(全拼)
- schema: rime_frost_double_pinyin # 自然码双拼
- schema: rime_frost_double_pinyin_mspy # 微软双拼
- schema: rime_frost_double_pinyin_sogou # 搜狗双拼
- schema: rime_frost_double_pinyin_flypy # 小鹤双拼
说明它启用了这五个方案(不列举了)。
更新方案配置文件
总之找到你要用的方案名称,然后对该配置文件打补丁。以 rime_frost_double_pinyin_flypy 方案为例,打开或新建 rime_frost_double_pinyin_flypy.custom.yaml 文件,然后加上这几行:
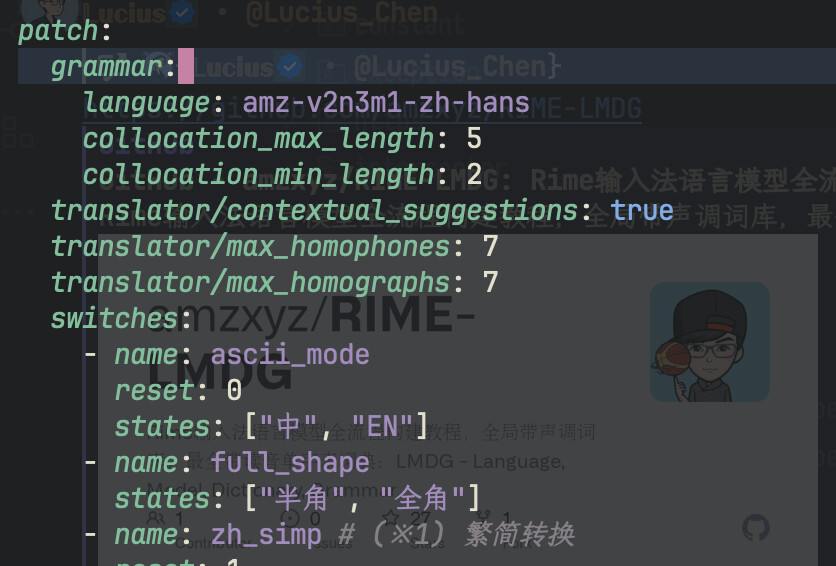
patch:
grammar:
language: amz-v2n3m1-zh-hans
collocation_max_length: 5
collocation_min_length: 2
translator/contextual_suggestions: true
translator/max_homophones: 7
translator/max_homographs: 7
其中 amz-v2n3m1-zh-hans 为下载好的模型文件名(无后缀名)。然后保存,重新部署,便能享受语言模型了。
效果展示
渐渐地就不在意了
使用前:

(「不/在意/了」被理解成了「不再/一乐」)
使用后:

以前就会这样
使用前:

(「以前/就会」被理解成了「一千九/会」)
使用后:

不管怎么使劲都不行
使用前:

(「不管怎么/使劲/都/不行」 => 「不管怎么/是/筋斗/不行」)
使用后:

无论如何你都不可能再离开这里了
使用前:

(「离开/这里/了」 => 「离开/这/离了」)
使用后:

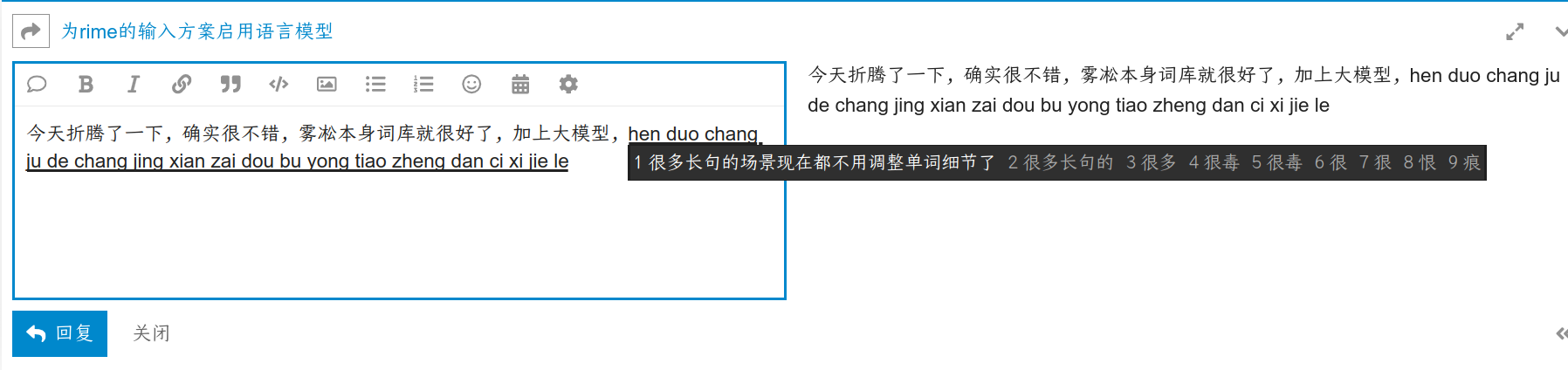
 总是打不出是的
总是打不出是的