参考佛振的示范,应该是不需要octagram的,实际上我Windows端和macOS都没用octagram字符片段,直接放的后面几行。
我的意思是标记没法分的更细 hhh,看了下 cand.type 只有 user_phrase 和 phrase
不过弄了这个,我原本用的这个好像失效了。
emoji_conversion:
opencc_config: emoji.json
option_name: show_emoji
tags: abc
另外词频好像不变化了?
我输入了多次「我们」,但是始终还是在第四位。
建议贴个全部的 custom.yaml 或者去 build 目录下确认最终的是否符合要求,那个配置很容易不小心就冲突了
# luna_pinyin.custom.yaml
#
# 補靪功能:將朙月拼音的詞庫修改爲朙月拼音擴充詞庫
#
# 作者:瑾昀 <[email protected]>
#
# 注意:本補靪適用於所有朙月拼音系列方案(「朙月拼音」、「朙月拼音·简化字」、「朙月拼音·臺灣正體」、「朙月拼音·語句流」)。
# 只須將本 custom.yaml 的前面名字改爲對應的輸入方案名字然後放入用戶文件夾重新部署即可。如 luna_pinyin_simp.custom.yaml。
# 雙拼用戶請使用 double_pinyin.custom.yaml。
#
# 附朙月拼音系列方案與其對應的 id 一覽表:
# 輸入方案 id
# 朙月拼音 luna_pinyin
# 朙月拼音·简化字 luna_pinyin_simp
# 朙月拼音·臺灣正體 luna_pinyin_tw
# 朙月拼音·語句流 luna_pinyin_fluency
patch:
switches:
- name: ascii_mode
reset: 0
states: ["中", "EN"]
- name: full_shape
states: ["半角", "全角"]
- name: zh_simp # (※1) 繁简转换
reset: 1
states: ["漢字", "汉字"]
- name: ascii_punct
states: ["。,", ".,"]
- options: ["utf8", "gbk", "gb2312"] # (※2)字符集选单
reset: 0 # 默认 UTF8
states:
- UTF-8
- GBK
- GB2312
- name: show_emoji
reset: 1
states: ["🈚️️\uFE0E", "🈶️️\uFE0F"]
simplifier:
option_name: zh_simp
engine/filters:
- simplifier
- simplifier@emoji_conversion
- uniquifier
- charset_filter@gbk # (※3) GBK 过滤
# 編譯版本的鼠鬚管可以去掉上面幾行的註釋符號,啓用字符集過濾功能
emoji_conversion:
opencc_config: emoji.json
option_name: show_emoji
tags: abc
"speller/algebra/@before 0": xform/^([b-df-hj-np-tv-z])$/$1_/
# 加載 easy_en 依賴
"schema/dependencies/@next": easy_en
# 載入翻譯英文的碼表翻譯器,取名爲 english
"engine/translators/@next": table_translator@english
# english 翻譯器的設定項
english:
dictionary: easy_en
spelling_hints: 9
enable_completion: false # 是否启用英文输入联想补全
enable_sentence: false
initial_quality: -2 # 调整英文候选词的位置,如 -3 会更靠后
# 載入朙月拼音擴充詞庫
"translator/dictionary": luna_pinyin.extended
# 符号快速输入和部分符号的快速上屏
punctuator:
import_preset: symbols
symbols:
"/fs": [½, ‰, ¼, ⅓, ⅔, ¾, ⅒]
"/bq":
[😂️, 😅️, ☺️, 😱️, 😭️, 😇️, 🙃️, 🤔️, 💊️, 💯️, 👍️, 🙈️, 💩️, 😈️]
"/dn": [⌘, ⌥, ⇧, ⌃, ⎋, ⇪, , ⌫, ⌦, ↩︎, ⏎, ↑, ↓, ←, →, ↖, ↘, ⇟, ⇞]
"/fh":
[
©,
®,
℗,
℠,
™,
℡,
␡,
♂,
♀,
☉,
☊,
☋,
☌,
☍,
☐,
☑︎,
☒,
☜,
☝,
☞,
☟,
✎,
✄,
♲,
♻,
⚐,
⚑,
⚠,
]
"/xh": [*, ×, ✱, ★, ☆, ✩, ✧, ❋, ❊, ❉, ❈, ❅, ✿, ✲]
"/py":
[
ā,
á,
ǎ,
à,
ō,
ó,
ǒ,
ò,
ê,
ê̄,
ế,
ê̌,
ề,
ē,
é,
ě,
è,
ī,
í,
ǐ,
ì,
ū,
ú,
ǔ,
ù,
ü,
ǖ,
ǘ,
ǚ,
ǜ,
ḿ,
m̀,
ń,
ň,
ǹ,
ẑ,
ĉ,
ŝ,
ŋ,
]
"/pyd":
[
Ā,
Á,
Ǎ,
À,
Ō,
Ó,
Ǒ,
Ò,
Ê,
Ê̄,
Ế,
Ê̌,
Ề,
Ē,
É,
Ě,
È,
Ī,
Í,
Ǐ,
Ì,
Ū,
Ú,
Ǔ,
Ù,
Ü,
Ǖ,
Ǘ,
Ǚ,
Ǜ,
Ḿ,
M̀,
Ń,
Ň,
Ǹ,
Ẑ,
Ĉ,
Ŝ,
Ŋ,
]
half_shape:
"#": "#"
"!": "!"
"*": "*"
"`": "`"
"~": "~"
"@": "@"
"=": "="
"/": ["/", "÷"]
'\': "、"
"_": "──"
"'": { pair: ["「", "」"] }
"[": ["【", "[", "『"]
"]": ["】", "]", "』"]
"$": ["¥", "$", "€", "£", "¢", "¤"]
"<": ["《", "〈", "«", "<"]
">": ["》", "〉", "»", ">"]
recognizer/patterns/punct: "^/([a-z]+|[0-9]0?)$"
# 模糊拼音
"speller/algebra":
- erase/^xx$/ # 第一行保留
# 模糊音定義
# 需要哪組就刪去行首的 # 號,單雙向任選
#- derive/^([zcs])h/$1/ # zh, ch, sh => z, c, s
#- derive/^([zcs])([^h])/$1h$2/ # z, c, s => zh, ch, sh
#- derive/^n/l/ # n => l
#- derive/^l/n/ # l => n
# 這兩組一般是單向的
#- derive/^r/l/ # r => l
#- derive/^ren/yin/ # ren => yin, reng => ying
#- derive/^r/y/ # r => y
# 下面 hu <=> f 這組寫法複雜一些,分情況討論
#- derive/^hu$/fu/ # hu => fu
#- derive/^hong$/feng/ # hong => feng
#- derive/^hu([in])$/fe$1/ # hui => fei, hun => fen
#- derive/^hu([ao])/f$1/ # hua => fa, ...
#- derive/^fu$/hu/ # fu => hu
#- derive/^feng$/hong/ # feng => hong
#- derive/^fe([in])$/hu$1/ # fei => hui, fen => hun
#- derive/^f([ao])/hu$1/ # fa => hua, ...
# 韻母部份
#- derive/^([bpmf])eng$/$1ong/ # meng = mong, ...
#- derive/([ei])n$/$1ng/ # en => eng, in => ing
#- derive/([ei])ng$/$1n/ # eng => en, ing => in
# 樣例足夠了,其他請自己總結……
# 模糊音定義先於簡拼定義,方可令簡拼支持以上模糊音
- abbrev/^([a-z]).+$/$1/ # 簡拼(首字母)
- abbrev/^([zcs]h).+$/$1/ # 簡拼(zh, ch, sh)
# 以下是一組容錯拼寫,《漢語拼音》方案以前者爲正
- derive/^([nl])ve$/$1ue/ # nve = nue, lve = lue
- derive/^([jqxy])u/$1v/ # ju = jv,
- derive/un$/uen/ # gun = guen,
- derive/ui$/uei/ # gui = guei,
- derive/iu$/iou/ # jiu = jiou,
# 自動糾正一些常見的按鍵錯誤
- derive/([aeiou])ng$/$1gn/ # dagn => dang
- derive/([dtngkhrzcs])o(u|ng)$/$1o/ # zho => zhong|zhou
- derive/ong$/on/ # zhonguo => zhong guo
- derive/ao$/oa/ # hoa => hao
- derive/ua$/au/ # shau => shua
- derive/([iu])a(o|ng?)$/a$1$2/ # tain => tian
# 分尖團後 v => ü 的改寫條件也要相應地擴充:
#'translator/preedit_format':
# - "xform/([nljqxyzcs])v/$1ü/"
__include: octagram
octagram:
__patch:
grammar:
language: amz-v2n3m1-zh-hans
collocation_max_length: 5
collocation_min_length: 2
translator/contextual_suggestions: true
translator/max_homophones: 7
translator/max_homographs: 7
我放在了最后。
扫了眼感觉不加 __include: octagram 也没啥问题,去看 build 目录下的 schema 吧
哦对,建议别用 __include,原因详见:fix(config_compiler): "/" mistaken as path separator in merged map key by kionz · Pull Request #192 · rime/librime · GitHub
补充: 需要安装 lua & octagram 这两个插件才能起作用:
[I] app-i18n/librime-lua
Available versions: (~)20240819212322 **99999999999999*l {LUA_SINGLE_TARGET="lua5-3 lua5-4"}
Installed versions: 20240819212322(14时03分41秒 2024年12月18日)(LUA_SINGLE_TARGET="lua5-4 -lua5-3")
Homepage: https://github.com/hchunhui/librime-lua
Description: Lua module for RIME
[I] app-i18n/librime-octagram [1]
Available versions: 9999*l
Installed versions: 9999*l(10时13分36秒 2024年12月18日)
Homepage: https://github.com/lotem/librime-octagram
Description: Lua module for RIME
weasel和squirrel,乃至手机端的fcitx5-rime都内置了Lua和Octagram插件。
有些发行版都把插件给封在了 librime 这个包里面,比如 arch linux,
还有一些是单独的插件包,但是作为 librime 的依赖了,比如 ubuntu,
还有的,比如 Gentoo,官方源里就没有 librime-octagram , 还得从 overlay 里面去找。。。
算是发行版的问题吧。
可能我配置比较老,我换了雾凇拼音之后,直接按照你的就可以了。雾凇拼音确实不错。
一直用雾凇拼音,听说薄荷不错,词库更好,今天刚切过来试试
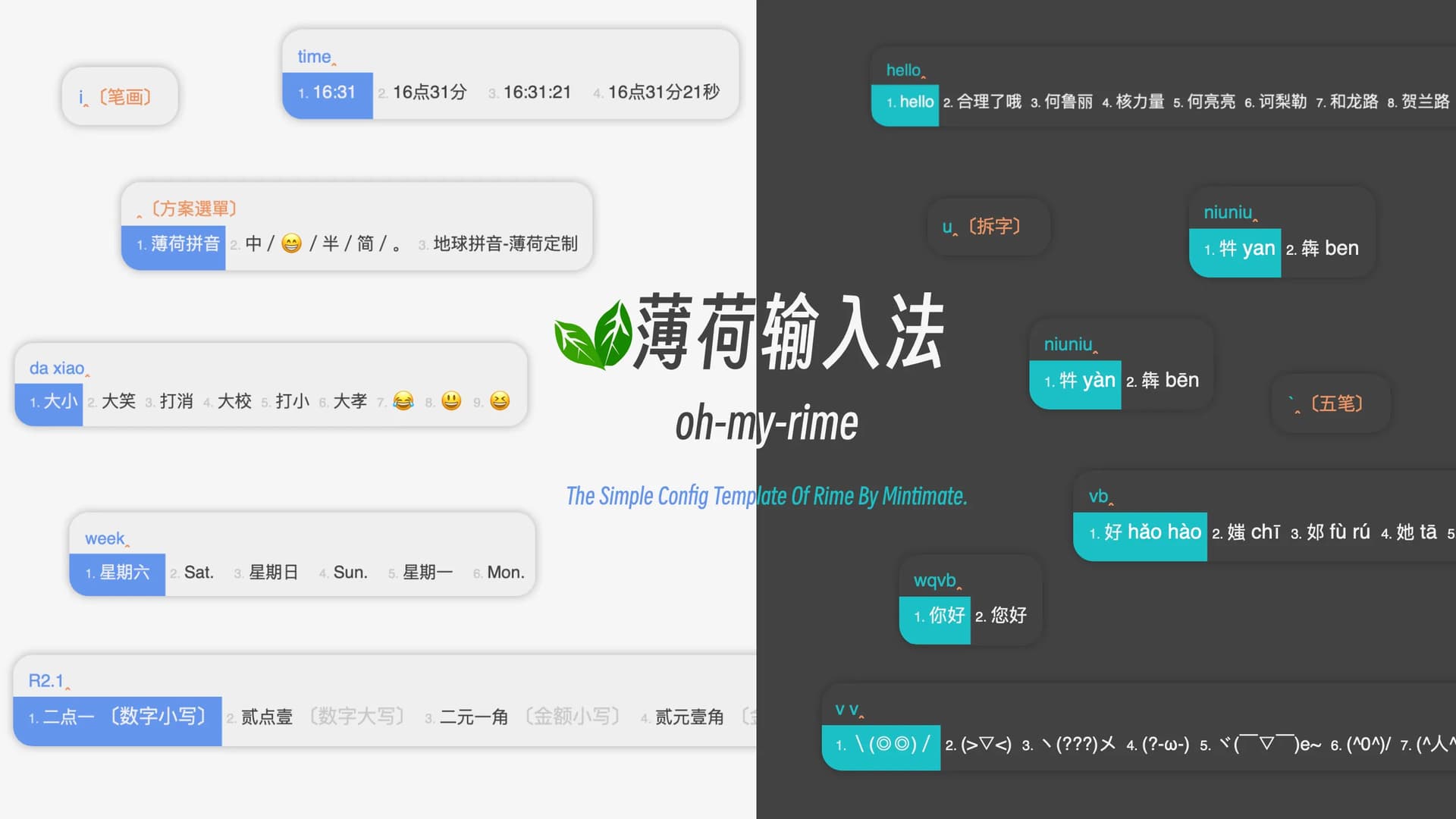
Mintimate/oh-my-rime: The Simple Config Template Of Rime By Mintimate. QQ Chat-Group: 703260572
1 个赞
作者在这里发布 rime 分词大模型:
其中 v2 版 100 MB 的效果也不错,资源占用不那么高
gentoo 用户可以参考我这次提交:
需要安装 app-i18n/librime-octagram 但官方库里没这个包,网上找了个,但似乎有依赖问题,需要安装 dev-libs/utfcpp,幸好gentoo 有这个包,多加了一行依赖 vmacs/linux/etc/portage/local/app-i18n/librime-octagram/librime-octagram-99999999999999.ebuild at master · jixiuf/vmacs · GitHub 放到我个人的仓库里了。
sudo ebuild librime-octagram-99999999999999.ebuild manifest
app-i18n/librime-lua 这个包是否需要我不确定,也一并装上了。
我自己维护的自用的一个五笔拼音混合输入方案,没采用补丁的形式,直接修改的原方案。 不确定 这个东西是否支持五笔,配在五笔那有可能有问题,只能先观察使用一段时间再说
1 个赞
谢谢推荐,用薄荷+语言模型在emacs里使用体验很不错,最主要是解决了微软拼音输入框字母显示太小的问题。不过要替代微软拼音,我还有个需求,即“人名模式”,找了一圈没找到合适的解决办法,所以搭车问一下:
- 哪里有 rime 人名词库?
- 能否配置快捷键 如 ; 进入“人名模式”?其实就是从人名词库筛选。而不在人名模式下,人名词库不进入候选词,除了之前经常输入已进入用户词库的人名。


请教下,这个模型对于双拼可以使用吗?比如小鹤双拼。
可以,字数补丁
1 个赞
我就在用双拼,完全没问题
1 个赞
主楼的rime_frost_double_pinyin_flypy就是小鹤方案的意思
1 个赞