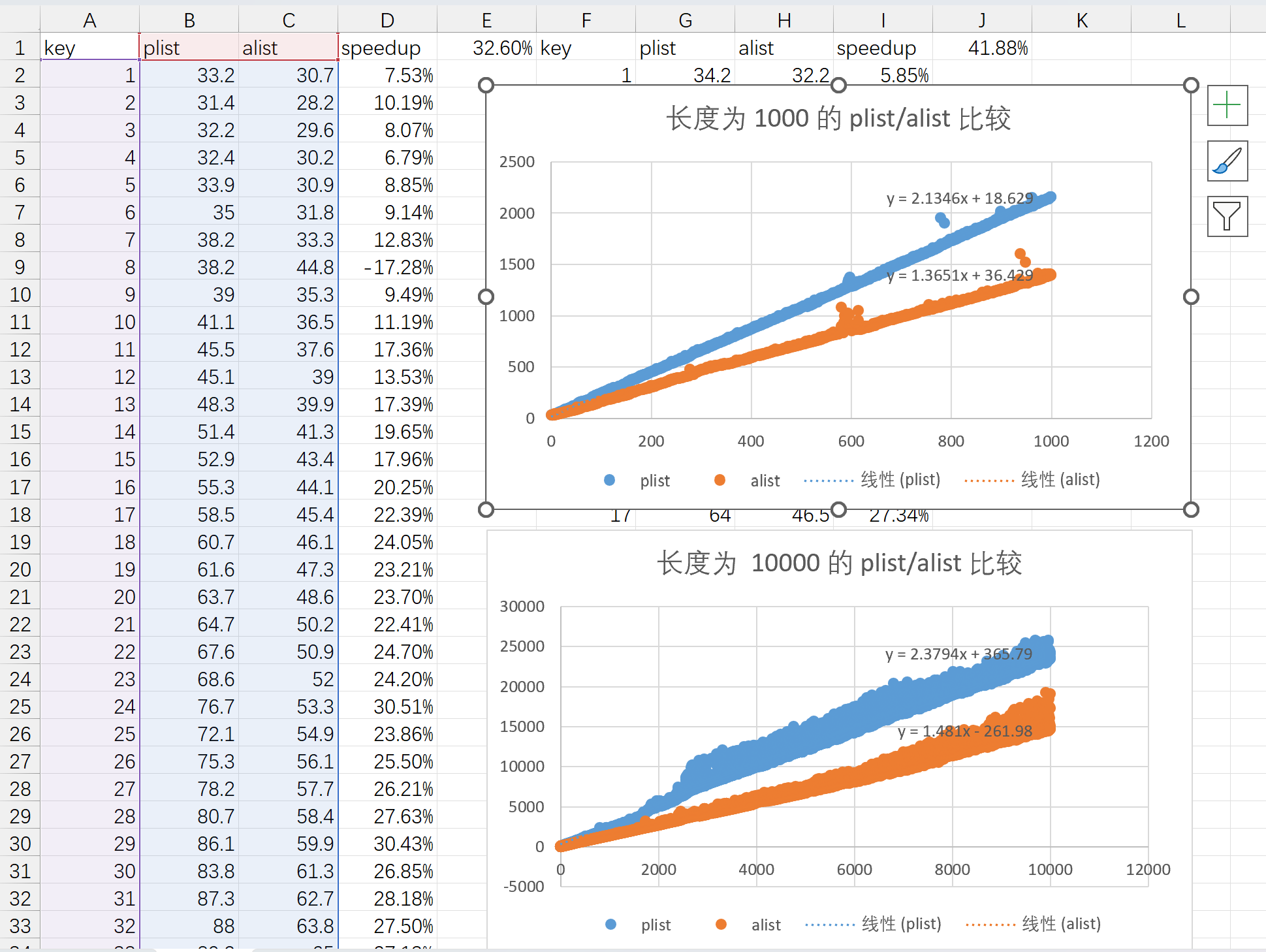
Org 导出的 communication channel(也就是所有元素/对象导出过程的上下文参数)使用的数据类型是 plist(property list,即属性列表)。写 Org 导出后端的时候我考虑了对 plist-get 进行一些优化,顺带比较了一下 plist 和 alist 的查找性能,结果居然是 plist 比 alist 慢:(下图的单位均为 ns)
我能想到的原因大概是同样键值对数量下 alist 长度只有 plist 一半,所以遍历速度会更快。测下来平均能快 30~40%.
附上测试代码:
Test
(defun t-create-plist (n)
(let ((res))
(dotimes (x n (reverse res))
(push x res) (push (% x 2) res))))
(defun t-create-alist (n)
(let ((res))
(dotimes (x n (reverse res))
(push (cons x (% x 2)) res))))
(defun test-plist (p n epoch)
(let ((res))
(dotimes (x n)
(let* ((run (benchmark-run epoch (plist-get p x)))
(time (/ (- (car run) (caddr run)) 1.0 epoch)))
(push time res)))
(reverse res)))
(defun test-alist (a n epoch)
(let ((res))
(dotimes (x n)
(let* ((run (benchmark-run epoch (alist-get x a)))
(time (/ (- (car run) (caddr run)) 1.0 epoch)))
(push time res)))
(reverse res)))
(let ((native-comp-speed 3))
(native-compile 'test-alist)
(native-compile 'test-plist))
(let ((gc-cons-threshold (expt 1024 3)))
(benchmark-run 1
(setq res-p (test-plist (t-create-plist 1000) 1000 1000))))
(let ((gc-cons-threshold (expt 1024 3)))
(benchmark-run 1
(setq res-p1 (test-plist (t-create-plist 10000) 10000 1000))))
(let ((gc-cons-threshold (expt 1024 3)))
(benchmark-run 1
(setq res-a (test-alist (t-create-alist 1000) 1000 1000))))
(let ((gc-cons-threshold (expt 1024 3)))
(benchmark-run 1
(setq res-a1 (test-alist (t-create-alist 10000) 10000 1000))))
(benchmark-run 1 (setq res-p (test-plist (t-create-plist 64) 64 1000000)))
(benchmark-run 1 (setq res-a (test-alist (t-create-alist 64) 64 1000000)))
4 个赞
一名使用termux然后死机的用户表示怀念lua了
plist访问需要解析列表中每一项,看它是不是key,alist只需要解析key。这和相关函数的实现有关,如果plist底层使用zipped的方式遍历
,效率应该会高很多(但是不安全,因为不能排除某个key没有值的情况)。alist长度刚好是plist两倍的情况,性能差不多的。
可以尝试自己实现一个这样的plist-get试试
我去查了下,有两个版本的实现:
plist-get使用的是equal,key是符号的情况下使用eqget用的是eq。
考虑到key的值一般是符号,但是不一定总是符号,考虑到equal的符号在elisp里实际不一定eq ,所以get可能不合你的预期。
(get是从maclisp继承来的原语。maclisp里面任何两个equal的原子都eq的)
我之前提到的不安全的zipped traverse没有出现。
但是 lsp 使用 plist 作为 json 的表示似乎是效果最好的?因为不管是 lsp-mode 还是 eglot 似乎都选择了 plist 而不是 alist 或者 hashtable 来表示 json。
此外,json-parse-string 也默认选择 plist 来作为表达。
gynamics:
我去查了下,有两个版本的实现:
plist-get使用的是equal,key是符号的情况下使用eqget用的是eq。
实际上,当 plist-get 没有指定比较函数时,plist-get 和 get 内部都使用了 plist_get C 函数:
DEFUN ("plist-get", Fplist_get, Splist_get, 2, 3, 0,
doc: /* Extract a value from a property list.
PLIST is a property list, which is a list of the form
\(PROP1 VALUE1 PROP2 VALUE2...).
This function returns the value corresponding to the given PROP, or
nil if PROP is not one of the properties on the list. The comparison
with PROP is done using PREDICATE, which defaults to `eq'.
This function doesn't signal an error if PLIST is invalid. */)
(Lisp_Object plist, Lisp_Object prop, Lisp_Object predicate)
{
if (NILP (predicate))
return plist_get (plist, prop);
Lisp_Object tail = plist;
FOR_EACH_TAIL_SAFE (tail)
{
if (! CONSP (XCDR (tail)))
break;
if (!NILP (calln (predicate, XCAR (tail), prop)))
return XCAR (XCDR (tail));
tail = XCDR (tail);
}
return Qnil;
}
/* Faster version of Fplist_get that works with EQ only. */
Lisp_Object
plist_get (Lisp_Object plist, Lisp_Object prop)
{
Lisp_Object tail = plist;
FOR_EACH_TAIL_SAFE (tail)
{
if (! CONSP (XCDR (tail)))
break;
if (EQ (XCAR (tail), prop))
return XCAR (XCDR (tail));
tail = XCDR (tail);
}
return Qnil;
}
DEFUN ("get", Fget, Sget, 2, 2, 0,
doc: /* Return the value of SYMBOL's PROPNAME property.
This is the last value stored with `(put SYMBOL PROPNAME VALUE)'. */)
(Lisp_Object symbol, Lisp_Object propname)
{
CHECK_SYMBOL (symbol);
Lisp_Object propval = plist_get (CDR (Fassq (symbol,
Voverriding_plist_environment)),
propname);
if (!NILP (propval))
return propval;
return plist_get (XSYMBOL (symbol)->u.s.plist, propname);
}
目前我还是倾向于 plist 和 alist 在 key 为指针可以放下的值时使用的底层查找函数 plist_get 和 remq 出现性能差异的原因是 plist 需要遍历的列表长度更长。
感觉 plist 确实“更用户友好”,没那么多括号要写。
1 个赞
include-yy:
plist 需要遍历的列表长度更长。
这个影响应该非常小,性能开销的大头在对列表成员的检查上。如果plist是严格的pair list,只检查为key的奇数项不会浪费时间。
如果使用 string 而不是数字或符号作为键,plist 和 alist 差异很小,也就是你说的“性能开销大头在成员检查上:
考虑到 eq 比较开销非常低,这里我还是觉得对 eq alist/plist 来说遍历是主要开销
以下是测试代码:
(setq pl
(let ((res))
(dotimes (x 64)
(push (format "%03d" x) res)
(push t res))
(nreverse res)))
(setq al
(let ((res))
(dotimes (x 64)
(push (cons (format "%03d" x) t) res))
(nreverse res)))
(defun test-pl (ls epoch)
(let ((keys (map-keys ls)) res)
(dolist (k keys)
(let* ((run (benchmark-run epoch (plist-get ls k #'string=)))
(time (/ (car run) 1.0 epoch)))
(push time res)))
(nreverse res)))
(defun test-al (ls epoch)
(let ((keys (map-keys ls)) res)
(dolist (k keys)
(let* ((run (benchmark-run epoch (alist-get k ls nil nil #'string=)))
(time (/ (car run) 1.0 epoch)))
(push time res)))
(nreverse res)))
(let ((native-comp-speed 3))
(native-compile 'test-pl)
(native-compile 'test-al))
(setq res-p (test-pl pl 1000000))
(setq res-a (test-al al 1000000))
Kana
2025 年5 月 31 日 07:44
9
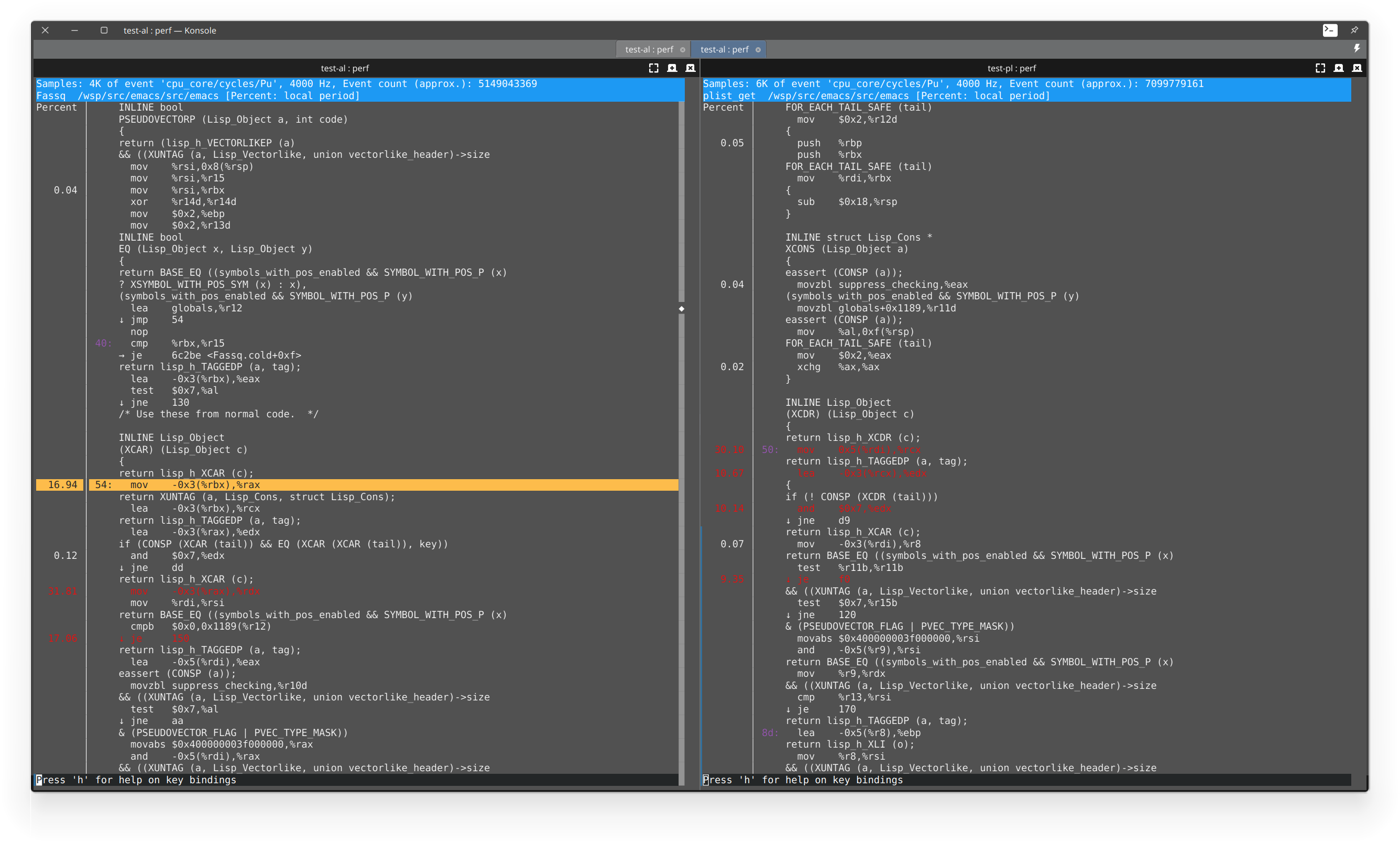
跑了一下 perf,但仍然看不出来什么……
命令及输出
$ perf stat -B -e cache-references,cache-misses,cycles,instructions,branches,branch-misses emacs -q --batch --script test.el --eval '(test-alist (t-create-alist 2000) 2000 2000)'
Performance counter stats for 'emacs -q --batch --script test.el --eval (test-alist (t-create-alist 2000) 2000 2000)':
1,664,859,118 cache-references:u
37,560,924 cache-misses:u # 2.26% of all cache refs
22,989,245,371 cycles:u
89,163,920,063 instructions:u # 3.88 insn per cycle
29,026,961,366 branches:u
21,303,743 branch-misses:u # 0.07% of all branches
5.229262209 seconds time elapsed
5.180081000 seconds user
0.023831000 seconds sys
$ perf stat -B -e cache-references,cache-misses,cycles,instructions,branches,branch-misses emacs -q --batch --script test.el --eval '(test-plist (t-create-plist 2000) 2000 2000)'
Performance counter stats for 'emacs -q --batch --script test.el --eval (test-plist (t-create-plist 2000) 2000 2000)':
1,661,666,301 cache-references:u
37,152,948 cache-misses:u # 2.24% of all cache refs
40,751,947,902 cycles:u
84,247,031,479 instructions:u # 2.07 insn per cycle
24,801,242,536 branches:u
21,350,234 branch-misses:u # 0.09% of all branches
9.235591770 seconds time elapsed
9.183998000 seconds user
0.022889000 seconds sys
二者的执行指令数量都差不多,但是 IPC(insn per cycle)不知为什么差异巨大:alist-get 是 3.8 IPC,而 plist-get 是 2.07 IPC,减了将近一半。常见的解释一般是缓存命中率或是分支预测有问题,但二者这两项也大同小异……不知道有没有比较熟悉底层调优的人来分析一下。
二者一个循环的操作也几乎一致
第 1 列
第 2 列
plist
alist
(consp list)
(consp list)
(consp (cdr list))
(consp (car list))
非 cons 时跳出循环
非 cons 时继续下个循环
(eq (car list) key)
(eq (caar list) key)
(setq list (cddr list))
(setq list (cdr list))
当然上面 perf 结果里也显示二者 instructions:u 差不太多就是了。
想了想,还有一种可能是对齐问题。如果 16-byte 对齐的地址访问比 8-byte 对齐的更快的话 [citation needed],那么 Lisp_Cons 的 car 应该一般是 16-byte 对齐的,而紧跟后面的 cdr 就只能是 8-byte 对齐了。plist 操作 cdr 更多,而 alist 的 car 更多,说不定能说明速度差异?
1 个赞
同样键值对数量下,plist 是 alist 长度的一倍,可能就是这个原因。
不过我不太懂 cache 命中啥的,也许是列表天然对 cache 不友好。
我用-O2 -g3编了一个emacs跑测试,两边访问的数据都不是对齐的。但是cdr踩到的热点似乎更多一些。
这可能是实际原因,我还没有做踩内存的测试。
2 个赞
但是并不完全是用户友好的原因。除了用户配置变量外,lsp-mode 和 eglot 都选择使用 plist 来表达内部通讯交流的 json 数据结构。
Kana
2025 年6 月 1 日 08:49
13
但其实 plist 和 alist 都需要访问 2N 个 cons,而且上面 perf 结果也显示二者所需的执行指令数差异不大,可能和 list 长度关系不大。主要困惑的点是二者指令的执行效率差异太大了。
的确不是对齐的问题:试用了下 aider,简单用 C 实现了 cons 和 alist-get 及 plist-get,仍然有显著的速度差异,即使调转 car 和 cdr 的顺序让 cdr 放在前面进行 16byte 对齐。
代码
GitHub - gudzpoz/alist-plist-benchmark: Benchmarking alist/plist performance with Linux perf. · GitHub
#define CONS_FIELD(name, alignment) \
union { \
struct cons *pointer; \
uint64_t value; \
} name __attribute__((aligned(alignment)))
// Aligned cons cell structure matching Emacs' memory layout
struct cons {
#ifdef CDR_FIRST
CONS_FIELD(cdr, 16);
CONS_FIELD(car, 8);
#else
CONS_FIELD(car, 16);
CONS_FIELD(cdr, 8);
#endif
};
// Alist lookup (association list)
uint64_t __attribute__((noinline)) alist_get(struct cons *list, uint64_t key) {
while (list != NULL) {
struct cons *pair = list->car.pointer;
if (pair->car.value == key) {
return pair->cdr.value;
}
list = list->cdr.pointer;
}
return -1;
}
// Plist lookup (property list)
uint64_t __attribute__((noinline)) plist_get(struct cons *list, uint64_t key) {
while (list != NULL) {
if (list->car.value == key) {
return list->cdr.pointer->car.value;
}
list = list->cdr.pointer->cdr.pointer;
}
return -1;
}
把 car 和 cdr 互换后,二者的汇编可以说是指令级的一致:
alist 循环plist 循环一致?
mov (%rdi), %raxmov (%rdi), %rax
cmp %rsi, (%rax)cmp %rsi, %x8(%rdi)
je :break_loopje :break_loop
mov 0x8(%rdi), %rdimov (%rax), %rdi
test %rdi, %rditest %rdi, %rdi
jne :loop_startjne :loop_start
我是想不明白了,或许和指令间的数据依赖导致无法流水线并行有关?
1 个赞
说不好是缓存的问题 不过只是猜想
按我的理解 plist应该更符合缓存机制 但实际上可能是alist 因为lisp系对cons的内存结构和gc都有优化
最简单的法子 就是用其它scheme进行复现一下plist和alist
Kana:
或许和指令间的数据依赖导致无法流水线并行有关
目前我也这样猜测。不知道其它的gcc优化级别会有什么影响,还有其它不同的架构上是什么情况。Emacs用了一个比较复杂的for循环封装列表遍历,只看C代码可能不好解。
我有一个想法是,如果plist-get做循环展开,每轮过两个结点,性能可能会提升。
1 个赞
cireu
2025 年6 月 2 日 07:42
16
猜测一下:plist 更长,所以需要的 pointer chasing 更多,比如把 list 拆成 pair 的表示法
(:a 1 :b 2 :c 3) => (:a . (1 . (:b . (2 . (:c . (3 . nil))))))
((a . 1) (b . 2) (c . 3)) => ((a . 1) . ((b . 2) . ((c . 3) . nil)))
alist 访问到一个 key-value pair, 直接取 pair 的 cdr 就可以访问 value, plist 访问到 key 还要取 cdr 的 car 才能访问到 value.
3 个赞
就上面所有帖子综合来看,缓存影响的“可能性”最大,不过我不太懂性能分析,这个帖子我能做的讨论大概就到这里了,之后学点性能测试工具去。
解决方案,目前来看就给楼上了。
另,根据 elisp 管理 cons 和其他数据类型分配的方法来看,同一 list 的各 cons 之间应该有不少的“间隔”或者说被其他对象使用的“坑位”,可以简单看看 alloc.c 的相关代码。
是的,M-x occur 能找到很多 plist-get 调用。这个选择与性能应该没太大关系。
难说,elisp 的 plist 和 alist 都有原语级别的 remq 和 plist-get,如果要在其他 Lisp 里试试,alist 和 plist 相关代码都得用 Lisp 实现,某些比较细的差异可能体现不出来。
不过确实也值得一试,之后看看。
你真的尝试模拟了吗? 就拿你这个例子:
访问 plist[:b]: 第一次 car 发现是 :a, 再 cdr 两次到 :b, car 一下发现是要找的键值对, 再 cdr + car 拿到值.
总共 三次 car + 三次 cdr
访问 alist[:b]: car 两次发现是 :a, 再 cdr + car 拿到下一个键值对, 再 car 发现 key 是 :b, 再 cdr 拿到值.
总共 四次 car + 两次 cdr
理论上的算法复杂度根本没有任何区别
另外见 Plist is Better than Alist?
怀疑点是cons为gc 直接两者是同一内存块 这样前者读取的时候 后者已经在缓存内了 而plist可能就是一指针链表 这种情况下alist秒了plist是可能的 不过得从原码上找到依据 我去翻一下试试(主要是我真不会c 只是个clj小鬼)
===
没找到证据能证明是缓存问题,我看不懂代码 菜鸡已经被工业c代码震撼了 学校里写的都是什么屎 连malloc都没看懂 *new = xxx-alloc(sizeof(*new), MEM_TYPE_CONS) 这是什么操作 啊?
include-yy:
就上面所有帖子综合来看,缓存影响的“可能性”最大
我认为Kana在8楼给的perf结论非常有力,二者是IPC差异巨大,缓存命中率和分支预测率差别不大。主要的差异是在指令并行度上,与缓存关系不大。Elisp里的同类对象,包括列表结点,都是对齐存储的,不存在内存分布差异上的问题,所以没有直接证据支持是缓存影响。
我在10楼贴了对应的汇编代码,这里的汇编左边是assq,右边是plist-get,inline函数做了展开。这里只能对照手册看指令依赖和数据依赖分析并行度。我在后面提架构和编译优化问题就是针对这个说的。现代处理器的流水线深度都在10以上,不要觉得只有cache miss影响大。
1 个赞