看来现在点“解决方案”还太早了 ![]()
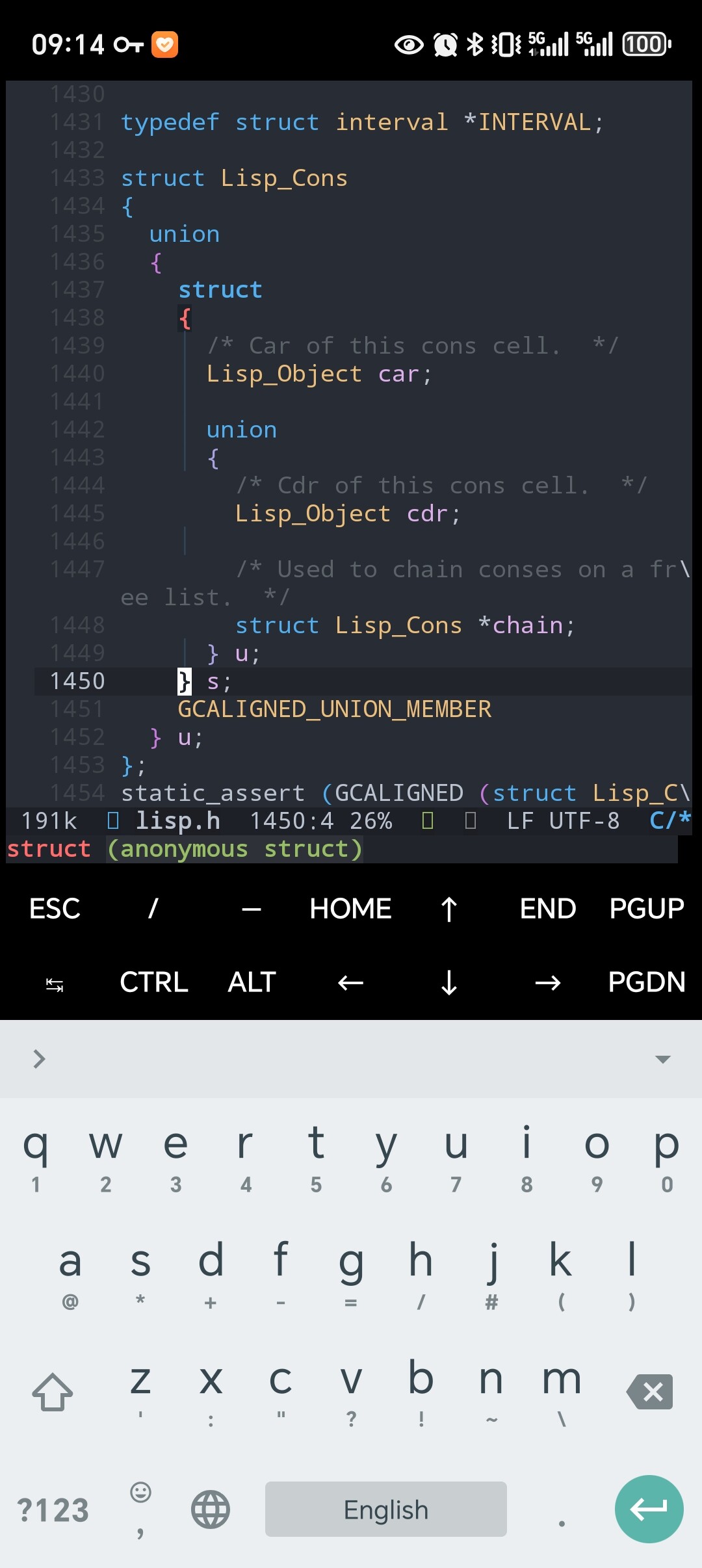
找到啦 工业级别的c 还真是复杂 宏加内联函数。算是小证据之一
从cons的行为中跟踪到xsetcar 再跟踪到这个lisp_cons的结构。 cons首先有个gc优化 就是复用 但其它gc优化的就不管了。
核心是 lisp_cons是一个结构体 而一个对子 刚好能存在一个lisp_cons上 他们是一个连续的内存结构,这样下来alist相比由plist组成的链表内存结构 有更优的内存存储结构。
alist的结构为一个链表对子。而对子 (key . value) 这个是刚好对应 一个c struct的。 从缓存角度来说 alist在读取kv时 优于plist。 因为 alist 是 (cons (k . v) chain-pointer) 而plist是(cons k chain-pointer) 在那个指针指向的位置是v. (感觉我说话有点像2020年的ai了 乱的不行) 比如 以下 ()表达为一个对子, 那 存储 a = 1, b = 2, c = 3的结构如下 alist: ((a . 1) ((b . 2) ((c . 3) nil))) plist: (a (1 (b (2 (c (3 nil)))))) 而对子是连续内存 在alist下 因kv连续 寻找下一个值时 只跳跃一次内存地址 而plist需要两次。因为后者是个chain*。 目前是这样 如果后面发现 其实它是直接塞了一个LispObject进来 我就爆炸啦(目前没看到这么深 但c分配内存应该是固定大小的 所以LispObject直接包一个cons可能性不大)
在缓存上alist表现是会比plist好 同时 对于cpu来说 流水线可能也会更好,因为对子是一个连续内存段 可惜链表不是,cpu乱序可以预先执行alist的查询 因为前后没有关联(猜测)
=====
我瞎写了一些测试代码 就往plist和alist中塞10000个数字 (1 . 6) 到 10000 10006,然后查询1到10000循环150次的时候 plist表现比alist 好 但在低次数的时候 alist表现比plist好,没手动打开native-compile 但应该是支持的 我已经麻了
参考 @Kana 在 8 楼给出的数据,分支预测和缓存命中率没有太大区别:
- alist 缓存未命中 2.26%,分支预测失败 0.07%
- plist 缓存未命中 2.24%,分支预测失败 0.09%
我目前比较认同这个观点,刚才又仔细看了一下 assq 和 plist-get 的代码,可以注意到:
DEFUN ("assq", Fassq, Sassq, 2, 2, 0,
doc: /* Return non-nil if KEY is `eq' to the car of an element of ALIST.
The value is actually the first element of ALIST whose car is KEY.
Elements of ALIST that are not conses are ignored. */)
(Lisp_Object key, Lisp_Object alist)
{
Lisp_Object tail = alist;
FOR_EACH_TAIL (tail)
if (CONSP (XCAR (tail)) && EQ (XCAR (XCAR (tail)), key))
return XCAR (tail);
CHECK_LIST_END (tail, alist);
return Qnil;
}
assq 循环体内没有 side effect,而 plist-get
Lisp_Object
plist_get (Lisp_Object plist, Lisp_Object prop)
{
Lisp_Object tail = plist;
FOR_EACH_TAIL_SAFE (tail)
{
if (! CONSP (XCDR (tail)))
break;
if (EQ (XCAR (tail), prop))
return XCAR (XCDR (tail));
tail = XCDR (tail);
}
return Qnil;
}
可以注意到 tail = XCDR(tail) 在循环体内引入了副作用,而且修改的是正在遍历的对象。
我只知道没有副作用的代码更容易并行,也许和这个有关,对这个的验证需要改一下 FOR_EACH_TAIL_SAFE 改成每次跳两次,也就是取 CDDR。
试试去。
最好看编译优化后的汇编代码,如果你不加volatile限制,它在编译器眼里放哪儿都行(这不是C++,不存在构造对象开销的)。O0和O2你反汇编出来长得不一样的。
编译emacs时加-g选项,用perf annotate查看热点函数的反汇编。参考emacs/etc/DEBUG
先别猜了兄弟,尊重实验,实验
1 个赞
你就算写 C, 涉及到非平凡的初始化也是会有开销的. C 在大部分情况下不会比 C++ 实现得更高效.
在我看来这条语句产生唯一的开销就是调用函数的时候帧指针寄存器的值多加了16。关于C/C++的对象构造代价问题,这个问题我认为是implementation-defined,你可以另开一个水帖去讨论😳
用笔记本跑了一些测试,感觉可能不是很准,明天用我的小台式跑时间更长的测试去。
测试环境是 WSL2 Ubuntu noble。Emacs 编译参数取 ./configure --without-all --without-x (CFLAGS 是默认的 -O2 -g3 )
目前我还没改 plist_get 的实现,而是拿之前的代码小作修改后跑了一些简单的测试,代码如下:
;;; -*- lexical-binding:t; -*-
(require 'map)
(defun t-pl (len epoch)
(let* ((pl (let ((res))
(dotimes (x len)
(push (intern (format "a%03d" x)) res)
(push t res))
(nreverse res)))
(keys (map-keys pl)))
(dolist (k keys)
(dotimes (_ epoch)
(plist-get pl k)))))
(defun t-al (len epoch)
(let* ((al (let ((res))
(dotimes (x len)
(push (cons (intern (format "a%03d" x)) t) res))
(nreverse res)))
(keys (map-keys al)))
(dolist (k keys)
(dotimes (_ epoch)
(alist-get k al)))))
(provide 't)
编译完 Emacs 和 perf 后,我在 Emacs 的 src 目录下,使用如下命令进行测试,并统计测试数据:
perf stat -r 10 -e cycles -e instructions -e cache-misses -e cache-references -e branch-misses -e branch-instructions -e dTLB-load-misses -e dTLB-loads -e iTLB-load-misses -e iTLB-loads ./emacs --batch -L ~ --eval "(progn (require 't) (t-al 256 100000))"
(我将 t.el 放在 ~ 目录下)
这是 alist 测试,其中 L 是列表长度,E 是访问每个元素的次数,长度乘以次数就是总访问次数。times/s 是每轮测试用时(perf 我指定了 -r 10,time/s 乘以 10 就是某次测试的总用时)
| (L, E) | time/s | IPC | cache-misses | branch-misses | dTLB-load-misses | iTLB-load-misses |
|---|---|---|---|---|---|---|
| (4, 1E7) | 0.90 | 6.40 | 10.43% | 0.03% | 17.09 | 18.19% |
| (8, 1E7) | 1.98 | 6.35 | 9.65% | 0.02% | 19.33% | 34.37% |
| (16, 5E6) | 2.26 | 6.26 | 8.99% | 0.01% | 20.93% | 30.40% |
| (32, 2.5E6) | 2.98 | 5.69 | 8.80% | 0.01% | 22.67% | 44.06% |
| (64, 1E6) | 3.83 | 4.79 | 6.93% | 0.02% | 21.65% | 54.99% |
| (128, 4E5) | 5.16 | 4.25 | 6.53% | 0.02% | 23.29% | 65.72% |
| (256, 1E5) | 4.20 | 4.01 | 6.79% | 0.02% | 22.42% | 63.70% |
| (512, 5E4) | 8.66 | 3.82 | 6.66% | 0.07% | 22.50% | 89.01% |
| (1024, 1E4) | 6.37 | 3.83 | 1.45% | 0.10% | 21.65% | 76.95% |
这是 plist 测试:
| (L, E) | time/s | IPC | cache-misses | branch-misses | dTLB-load-misses | iTLB-load-misses |
|---|---|---|---|---|---|---|
| (4, 1E7) | 0.65 | 6.41 | 10.24% | 0.04% | 17.62% | 13.31% |
| (8, 1E7) | 1.55 | 6.37 | 9.14% | 0.02% | 18.15% | 25.39% |
| (16, 5E6) | 1.96 | 5.60 | 8.41% | 0.02% | 20.12% | 31.96% |
| (32, 2.5E6) | 3.08 | 4.39 | 8.05% | 0.01% | 19.98% | 43.69% |
| (64, 1E6) | 4.38 | 3.44 | 6.76% | 0.01% | 20.79% | 54.43% |
| (128, 4E5) | 6.96 | 2.73 | 5.50% | 0.11% | 23.60% | 81.20% |
| (256, 1E5) | 6.74 | 2.45 | 5.89% | 0.16% | 23.03% | 79.27% |
| (512, 5E4) | 13.05 | 2.33 | 2.46% | 0.14% | 25.01% | 85.57% |
| (1024, 1E4) | 10.27 | 2.27 | 3.63% | 0.10% | 23.27% | 66.20% |
从这两张表来看,可能真正拉开差距的是列表长度超过 64 后的分支命中率和 IPC。
不过总的来说这并不是一个非常严谨的测试,还需要比较 cycle 数和指令数,我测完了忘了记录了。
总之,欢迎给出一些测试改进建议,我之后写点更加严谨和全面的测试。
perf 真好玩
2 个赞
(![]() ,空调管道弯成 U 形导致空调水排不出去从内机流出来流到电脑上给我烧了,换了个新的 Redmi book pro 16 2025,这 ultra7 255H 比之前的 i5-11300H 好太多了。新电脑还没装 WSL 只能在 Windows 上测了。)
,空调管道弯成 U 形导致空调水排不出去从内机流出来流到电脑上给我烧了,换了个新的 Redmi book pro 16 2025,这 ultra7 255H 比之前的 i5-11300H 好太多了。新电脑还没装 WSL 只能在 Windows 上测了。)
具体开始之前先做个总结。
@gynamics
3 楼, 4 楼提到 plist-get 可能使用了 equal 而不是 eq ,我(在 6 楼)检查了一下,plist-get 在没有指定谓词时会使用 eq。
7 楼提到列表遍历的性能开销在对列表成员的检查上,我(在 8 楼)使用 string 和 string= 测试 plist 和 alist 性能,两者性能几乎一致,这说明当 key 非常简单时,性能开销不在 key 的检查上
在 15 楼指出可以考虑对 plist-get 做循环展开,每轮经过两个节点。
@Kana
9 楼通过 perf 测试发现发现 alist-get 的 IPC 几乎是 plist-get 的一倍。但是两者的缓存命中率或分支命中率大同小异。同时 9 楼还提到了可能的内存对齐问题:16-byte 对齐可能比 8-byte 对齐快。
13 楼指出 plist 和 alist 都需要访问 2N 个 cons,也通过代码排除了对齐的问题。最后指出可能和指令间数据依赖倒置无法流水线并行。
@acoret
14, 19 楼指出 plist 可能更符合缓存机制,可以考虑使用 Scheme 实现 plist/list 来测试。
@cireu
16 楼指出可能是因为 plist 更长需要更多的 point chasing
首先,让我们来排除一下缓存造成的影响。
众所周知,Elisp 中管理 cons 使用的是 32KB 对齐的 cons block,单个 cons 大小为 16Byte,32KB / 16B = 2048。但实际上每个 cons block 能存放的 cons 个数为 2030,后面还需要一些 GC 管理 bitmark 和可能的 padding。现代桌面 CPU 的 L1-cache 一般是 32KB 到 64 KB,如果我们能让 alist/plist 的所有 cons 都在一个 cons block 里面,测试时应该能够把缓存的影响减小到最小。
对于相同键值对数量的 plist/alist 而言它们使用的 cons 数量相同,都是键值对数量的两倍,也就是说单个 cons block 能以 alist/plist 形式放下的最大键值对数量是 1015。
但是,在 Elisp 层面我们没有办法得到一整个干净的 cons block,我写了两个 subr 来确保这一点:
// fns.c
DEFUN ("yy-ptr", Fyy_ptr, Syy_ptr, 1, 1, 0,
doc: /* yy's ptr function, get pointer value >> 3 */)
(Lisp_Object obj)
{
if (!CONSP (obj))
return Qnil;
return make_ufixnum(XLI(obj) >> 3);
}
// in fns.c's syms_of_fns (void)
defsubr (&Syy_ptr);
// alloc.c
DEFUN ("yy-cons-bulk", Fyy_cons_bulk, Syy_cons_bulk, 0, 0, 0,
doc: /* Create a CONS_BLOCK_SIZE vector containing a whole cons_block's conses.
Return Cons of Last cons_block's rest number of cons and the vector. */)
(void)
{
Lisp_Object val;
Lisp_Object vec;
EMACS_INT cnt = 0;
struct Lisp_Cons *copy = cons_free_list;
cons_free_list = NULL;
val = Qnil;
while (cons_block_index < CONS_BLOCK_SIZE)
{
val = Fcons (Qnil, val);
cnt = cnt + 1;
}
vec = make_vector (CONS_BLOCK_SIZE, Qnil);
for (EMACS_INT i = 0; i < CONS_BLOCK_SIZE; i++)
{
val = Fcons (Qt, Qt);
ASET(vec, i, val);
}
cons_free_list = copy;
return Fcons(make_fixnum(cnt), vec);
}
// in alloc.c's syms_of_alloc (void)
defsubr (&Syy_cons_bulk);
简单来说,如果 Elisp 的类型 bit tag 在最低位的话(大多数平台上的 Emacs 都会将 bit tags 放在 LSB),yy-ptr 会返回 cons 的指针值右移 3 位,由于 cons 至少是 8 字节对齐,这个值就是 cons 地址值除以 8 。
yy-cons-bulk 会将管理零散 cons 的 cons_free_list 暂时设置为空来强制让 Fcons 使用已有 cons block 或分配新的 cons block,通过消耗可能的已有 cons block 后分配新的 cons block 并放到向量中,我们就得到了一整个 cons block 的 cons。下面的函数可以测试我们获取的 vector 包含一整个 cons block,且长度为 2030:
(defun yy-bulk-test ()
(let* ((a (cdr (yy-cons-bulk)))
(len (length a))
(i 0))
(should (= len 2030))
(should (zerop (% (yy-ptr (aref a 0)) (expt 2 12))))
(while (< (incf i) len)
(should (= 2 (- (yy-ptr (aref a i))
(yy-ptr (aref a (1- i)))))))))
plist 的结构很简单,就是单层 list:
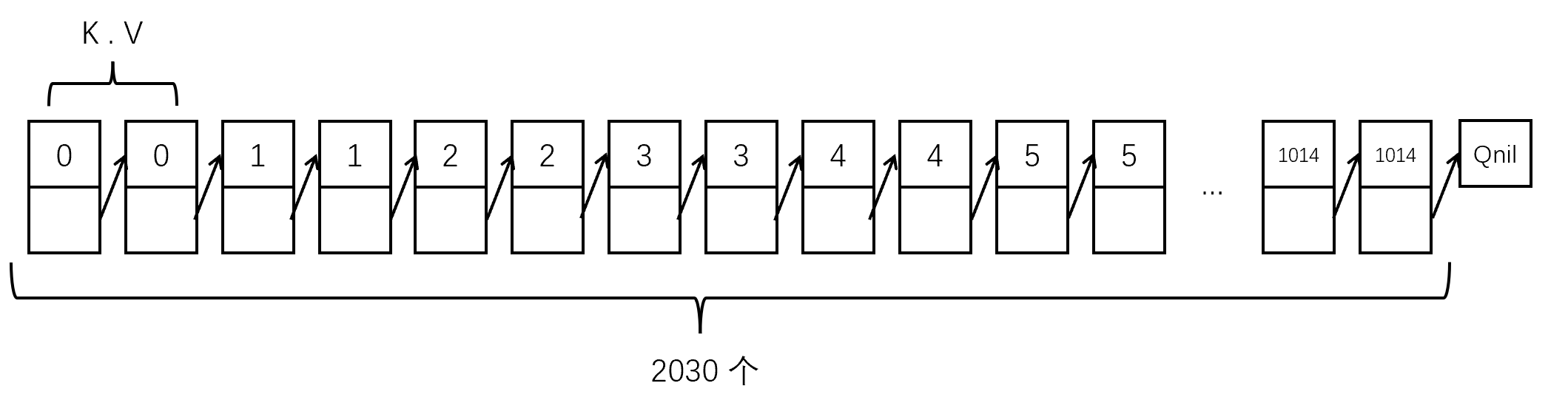
至于 alist,如果使用 (push (cons k v) ls) 的方式在单个空的 cons block 中创建,结构如下(这一张图主要想表现的是键值对 cons 和列表主体 cons 是相邻交错的):

除了这一种 alist 外,我们还可以把 kv cons 放在前 1015 个,把列表 cons 放在后 1015 个(或者倒过来),下面是用来生成单个 cons block 内的 plist/alist 的函数(*-alist1 对应交错分配,*-alist2 对应前 kv 后列表, *-alist3 对应前列表后 kv):
(defun make-test-plist ()
(let ((pv (cdr (yy-cons-bulk))))
(cl-assert (= (length pv) 2030))
(cl-do ((i 0 (1+ i)))
((> i 2028))
(setcar (aref pv i) (/ i 2))
(setcdr (aref pv i) (aref pv (1+ i))))
(setcar (aref pv 2029) 1014)
(setcdr (aref pv 2029) nil)
(let ((pl (aref pv 0))
(i 0))
(cl-mapl (lambda (x)
(cl-assert (eq x (aref pv i)))
(cl-incf i))
pl)
(dotimes (i 1015)
(cl-assert (eq (plist-get pl i) i)))
pl)))
(defun make-test-alist1 ()
(let ((av (cdr (yy-cons-bulk))))
(cl-assert (= (length av) 2030))
(cl-do ((i 0 (+ i 2))
(j 1 (+ j 2)))
((= i 2028))
(setcar (aref av i) (/ i 2))
(setcdr (aref av i) (/ i 2))
(setcar (aref av j) (aref av i))
(setcdr (aref av j) (aref av (+ j 2))))
(setcar (aref av 2028) 1014)
(setcdr (aref av 2028) 1014)
(setcar (aref av 2029) (aref av 2028))
(setcdr (aref av 2029) nil)
(let* ((al (aref av 1))
(k 0))
(dotimes (i 1015)
(cl-assert (eq (alist-get i al) i)))
(cl-mapl (lambda (x)
(cl-assert (eq x (aref av (1+ (* 2 k)))))
(cl-assert (eq (car x) (aref av (* k 2))))
(cl-incf k))
al)
al)))
(defun make-test-alist2 ()
(let ((av (cdr (yy-cons-bulk))))
(cl-assert (= (length av) 2030))
(cl-do ((i 0 (+ i 1)))
((> i 1014))
(setcar (aref av i) i)
(setcdr (aref av i) i))
(cl-do ((i 1015 (+ i 1)))
((> i 2028))
(setcar (aref av i) (aref av (- i 1015)))
(setcdr (aref av i) (aref av (1+ i))))
(setcar (aref av 2029) (aref av 1014))
(setcdr (aref av 2029) nil)
(let* ((al (aref av 1015))
(k 0))
(dotimes (i 1015)
(cl-assert (eq (alist-get i al) i)))
(cl-mapl (lambda (x)
(cl-assert (eq x (aref av (+ k 1015))))
(cl-assert (eq (car x) (aref av k)))
(cl-incf k))
al)
al)))
(defun make-test-alist3 ()
(let ((av (cdr (yy-cons-bulk))))
(cl-assert (= (length av) 2030))
(cl-do ((i 1015 (+ i 1)))
((> i 2029))
(setcar (aref av i) (- i 1015))
(setcdr (aref av i) (- i 1015)))
(cl-do ((i 0 (+ i 1)))
((> i 1014))
(setcar (aref av i) (aref av (+ i 1015)))
(setcdr (aref av i) (aref av (1+ i))))
(setcar (aref av 1014) (aref av 2029))
(setcdr (aref av 1014) nil)
(let* ((al (aref av 0))
(k 0))
(dotimes (i 1015)
(cl-assert (eq (alist-get i al) i)))
(cl-mapl (lambda (x)
(cl-assert (eq x (aref av k)))
(cl-assert (eq (car x) (aref av (+ k 1015))))
(cl-incf k))
al)
al)))
以下是用于测试的代码:
(progn
(defun test-p (key plist rep)
(declare (ftype (function (t list fixnum) float)))
(let ((t1 (float-time)))
(dotimes (_ rep)
(plist-get plist key))
(* (/ (- (float-time) t1) rep) (expt 10 9))))
(defun test-a (key alist rep)
(declare (ftype (function (t list fixnum) float)))
(let ((t1 (float-time)))
(dotimes (_ rep)
(alist-get key alist))
(* (/ (- (float-time) t1) rep) (expt 10 9))))
(dlet ((native-comp-speed 3))
(native-compile 'test-p)
(native-compile 'test-a)))
(setq pl (make-test-plist))
(setq al1 (make-test-alist1))
(setq al2 (make-test-alist2))
(setq al3 (make-test-alist3))
(when nil
(setq a
(let ((res))
(dotimes (i 1015)
(push (test-p i pl 10000) res))
(reverse res)))
(setq b
(let ((res))
(dotimes (i 1015)
(push (test-a i al1 10000) res))
(reverse res)))
(setq c
(let ((res))
(dotimes (i 1015)
(push (test-a i al2 10000) res))
(reverse res)))
(setq d
(let ((res))
(dotimes (i 1015)
(push (test-a i al3 10000) res))
(reverse res)))
)
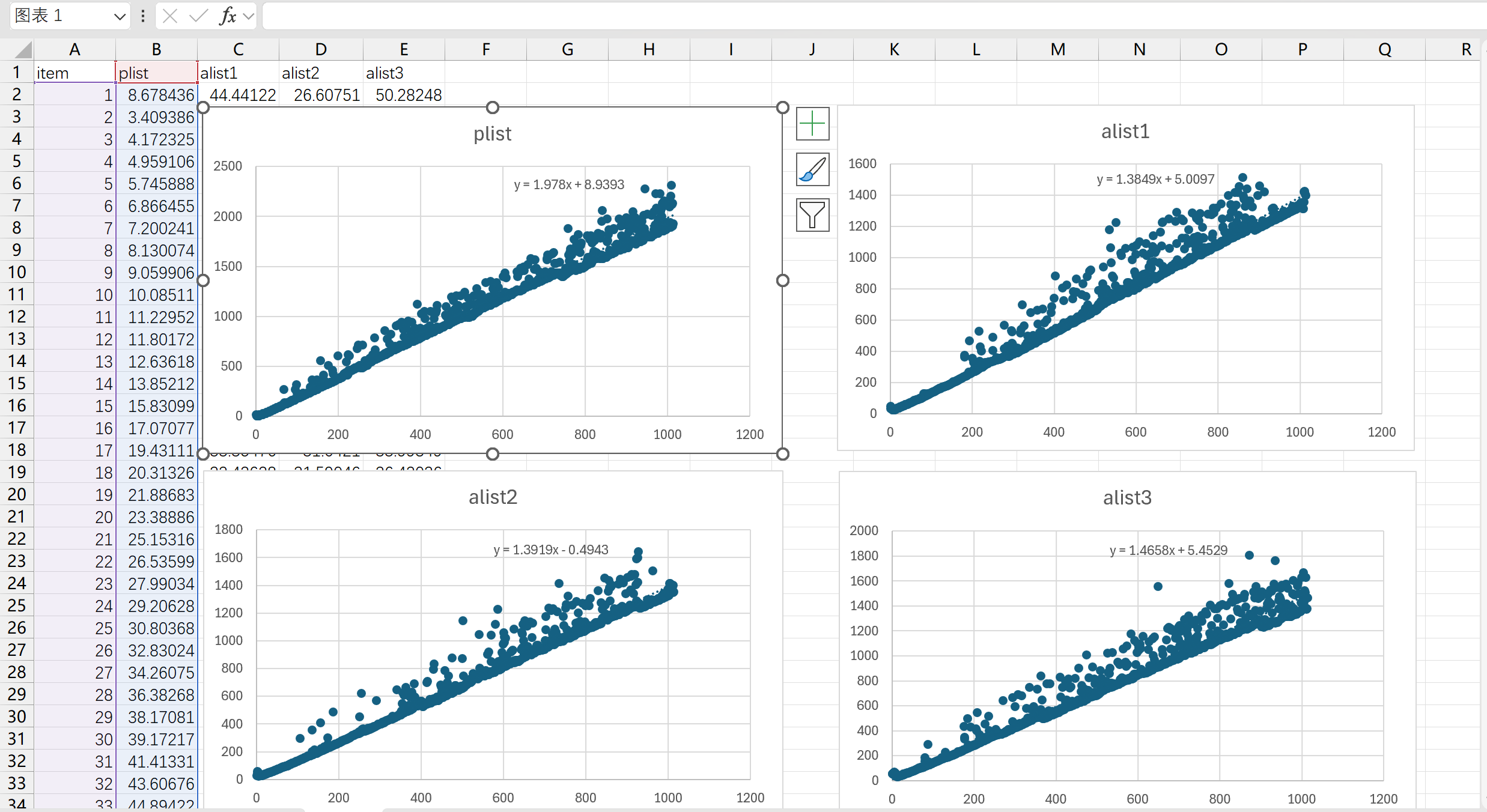
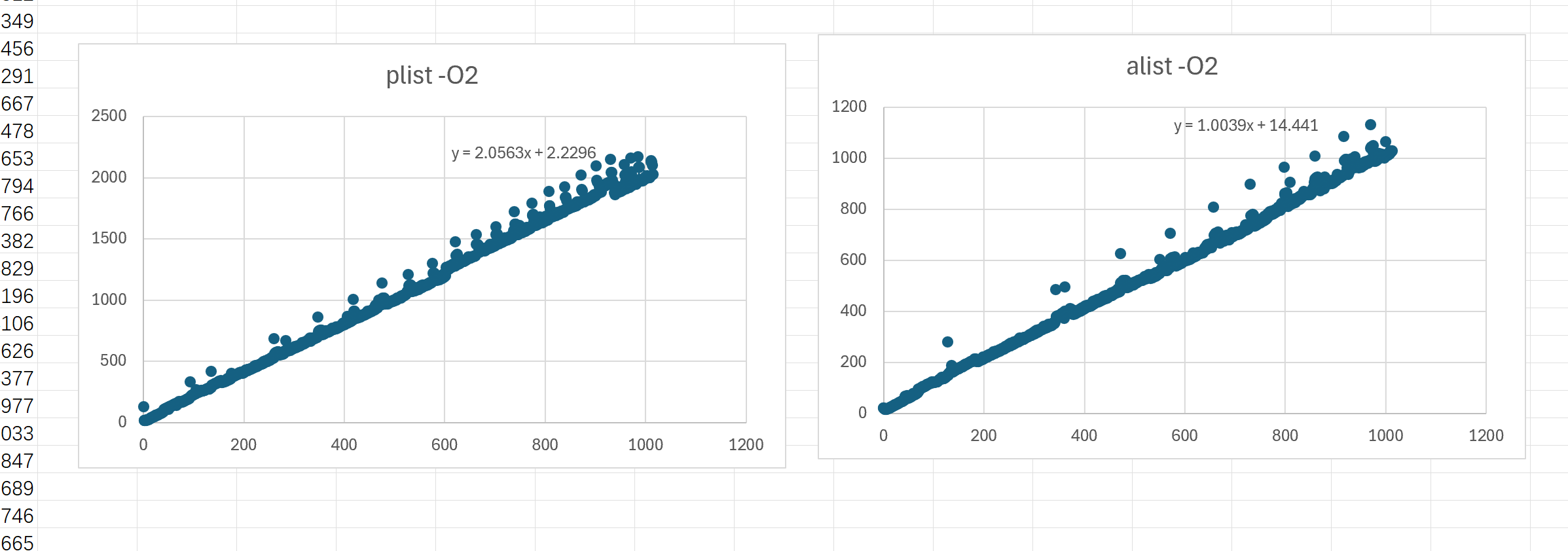
分别对 plist, alist1/2/3 绘制散点图,并计算拟合曲线,可以得到如下结果:
1 个赞
考虑到 plist-get 和 alist-get 都并不是直接调用 plist_get 和 assq ,我是用如下 subr 替换 plist-get 和 alist-get 进行了测试:
DEFUN ("my-plist-get", Fmy_plist_get, Smy_plist_get, 2, 2, 0,
doc: /* plist_get, without any check. */)
(Lisp_Object plist, Lisp_Object prop)
{
for(; !NILP (plist); plist = XCDR (XCDR (plist)))
{
if (EQ (XCAR (plist), prop))
return XCAR (XCDR (plist));
}
return Qnil;
}
DEFUN ("my-alist-get", Fmy_alist_get, Smy_alist_get, 2, 2, 0,
doc: /* alist_get, witout any check. */)
(Lisp_Object key, Lisp_Object alist)
{
for (; ! NILP (alist); alist = XCDR (alist))
if (EQ (XCAR (XCAR (alist)), key))
return XCDR (XCAR (alist));
return Qnil;
}
将 test-p 和 test-a 中的 plist-get 和 alist-get 替换位 my-plist-get 和 my-alist-get ,再进行测试可以得到如下结果:
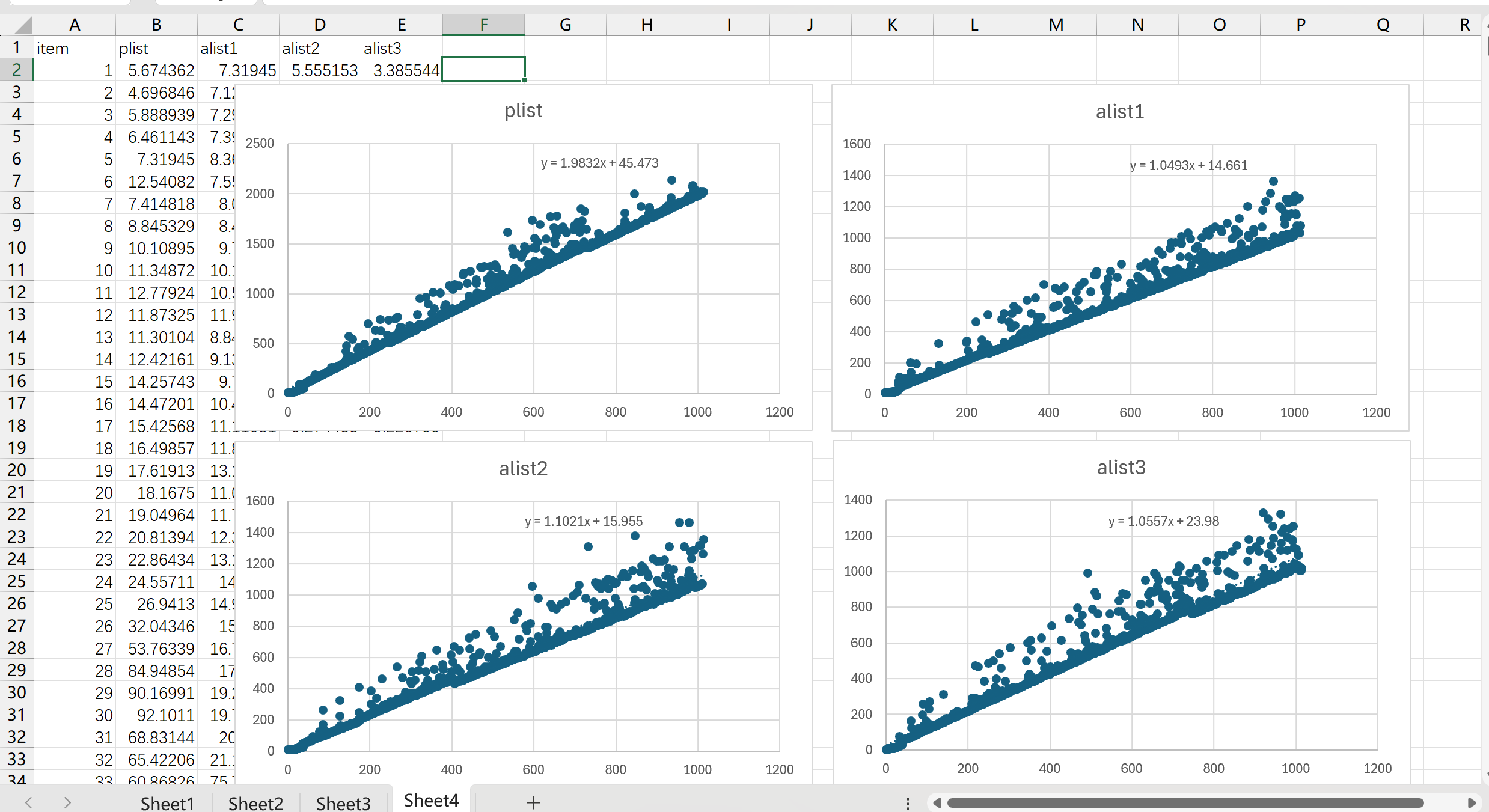
在去掉了几乎所有检查的情况下,两者的拟合曲线的斜率几乎是 1:2 的关系。
下面是 objdump 的输出结果:
my-plist-get:
00000000000015b0 <Fmy_plist_get>:
15b0: 53 push %rbx
15b1: 49 89 d1 mov %rdx,%r9
15b4: 48 85 c9 test %rcx,%rcx
15b7: 0f 84 bb 00 00 00 je 1678 <Fmy_plist_get+0xc8>
15bd: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax # 15c4 <Fmy_plist_get+0x14>
15c4: 44 0f b6 90 10 11 00 movzbl 0x1110(%rax),%r10d
15cb: 00
15cc: eb 20 jmp 15ee <Fmy_plist_get+0x3e>
15ce: 66 90 xchg %ax,%ax
15d0: 49 8b 50 08 mov 0x8(%r8),%rdx
15d4: 4c 8d 42 fd lea -0x3(%rdx),%r8
15d8: 48 39 c1 cmp %rax,%rcx
15db: 0f 84 8b 00 00 00 je 166c <Fmy_plist_get+0xbc>
15e1: 49 8b 48 08 mov 0x8(%r8),%rcx
15e5: 48 85 c9 test %rcx,%rcx
15e8: 0f 84 8a 00 00 00 je 1678 <Fmy_plist_get+0xc8>
15ee: 48 8b 51 fd mov -0x3(%rcx),%rdx
15f2: 4c 8d 41 fd lea -0x3(%rcx),%r8
15f6: 4c 89 c9 mov %r9,%rcx
15f9: 48 89 d0 mov %rdx,%rax
15fc: 45 84 d2 test %r10b,%r10b
15ff: 74 cf je 15d0 <Fmy_plist_get+0x20>
1601: 41 8d 41 fb lea -0x5(%r9),%eax
1605: a8 07 test $0x7,%al
1607: 75 1d jne 1626 <Fmy_plist_get+0x76>
1609: 48 b8 00 00 00 3f 00 movabs $0x400000003f000000,%rax
1610: 00 00 40
1613: 49 23 41 fb and -0x5(%r9),%rax
1617: 49 bb 00 00 00 06 00 movabs $0x4000000006000000,%r11
161e: 00 00 40
1621: 4c 39 d8 cmp %r11,%rax
1624: 74 5a je 1680 <Fmy_plist_get+0xd0>
1626: 44 8d 5a fb lea -0x5(%rdx),%r11d
162a: 48 89 d0 mov %rdx,%rax
162d: 41 83 e3 07 and $0x7,%r11d
1631: 75 9d jne 15d0 <Fmy_plist_get+0x20>
1633: 49 bb 00 00 00 3f 00 movabs $0x400000003f000000,%r11
163a: 00 00 40
163d: 4c 23 5a fb and -0x5(%rdx),%r11
1641: 4c 89 da mov %r11,%rdx
1644: 49 bb 00 00 00 06 00 movabs $0x4000000006000000,%r11
164b: 00 00 40
164e: 4c 39 da cmp %r11,%rdx
1651: 0f 85 79 ff ff ff jne 15d0 <Fmy_plist_get+0x20>
1657: 49 8b 50 08 mov 0x8(%r8),%rdx
165b: 48 8b 40 03 mov 0x3(%rax),%rax
165f: 4c 8d 42 fd lea -0x3(%rdx),%r8
1663: 48 39 c1 cmp %rax,%rcx
1666: 0f 85 75 ff ff ff jne 15e1 <Fmy_plist_get+0x31>
166c: 48 8b 42 fd mov -0x3(%rdx),%rax
1670: 5b pop %rbx
1671: c3 ret
1672: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
1678: 31 c0 xor %eax,%eax
167a: 5b pop %rbx
167b: c3 ret
167c: 0f 1f 40 00 nopl 0x0(%rax)
1680: 44 8d 5a fb lea -0x5(%rdx),%r11d
1684: 49 8b 49 03 mov 0x3(%r9),%rcx
1688: 48 89 d0 mov %rdx,%rax
168b: 41 83 e3 07 and $0x7,%r11d
168f: 0f 85 3b ff ff ff jne 15d0 <Fmy_plist_get+0x20>
1695: eb 9c jmp 1633 <Fmy_plist_get+0x83>
1697: 66 0f 1f 84 00 00 00 nopw 0x0(%rax,%rax,1)
169e: 00 00
my-alist-get
00000000000012f0 <Fmy_alist_get>:
12f0: 56 push %rsi
12f1: 53 push %rbx
12f2: 49 89 c9 mov %rcx,%r9
12f5: 48 85 d2 test %rdx,%rdx
12f8: 0f 84 b2 00 00 00 je 13b0 <Fmy_alist_get+0xc0>
12fe: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax # 1305 <Fmy_alist_get+0x15>
1305: 44 0f b6 90 10 11 00 movzbl 0x1110(%rax),%r10d
130c: 00
130d: eb 17 jmp 1326 <Fmy_alist_get+0x36>
130f: 90 nop
1310: 48 39 c1 cmp %rax,%rcx
1313: 0f 84 89 00 00 00 je 13a2 <Fmy_alist_get+0xb2>
1319: 49 8b 50 08 mov 0x8(%r8),%rdx
131d: 48 85 d2 test %rdx,%rdx
1320: 0f 84 8a 00 00 00 je 13b0 <Fmy_alist_get+0xc0>
1326: 48 8b 42 fd mov -0x3(%rdx),%rax
132a: 4c 8d 42 fd lea -0x3(%rdx),%r8
132e: 4c 89 c9 mov %r9,%rcx
1331: 48 8b 50 fd mov -0x3(%rax),%rdx
1335: 4c 8d 58 fd lea -0x3(%rax),%r11
1339: 48 89 d0 mov %rdx,%rax
133c: 45 84 d2 test %r10b,%r10b
133f: 74 cf je 1310 <Fmy_alist_get+0x20>
1341: 41 8d 41 fb lea -0x5(%r9),%eax
1345: a8 07 test $0x7,%al
1347: 75 1d jne 1366 <Fmy_alist_get+0x76>
1349: 48 b8 00 00 00 3f 00 movabs $0x400000003f000000,%rax
1350: 00 00 40
1353: 49 23 41 fb and -0x5(%r9),%rax
1357: 48 bb 00 00 00 06 00 movabs $0x4000000006000000,%rbx
135e: 00 00 40
1361: 48 39 d8 cmp %rbx,%rax
1364: 74 52 je 13b8 <Fmy_alist_get+0xc8>
1366: 8d 5a fb lea -0x5(%rdx),%ebx
1369: 48 89 d0 mov %rdx,%rax
136c: 83 e3 07 and $0x7,%ebx
136f: 75 9f jne 1310 <Fmy_alist_get+0x20>
1371: 48 bb 00 00 00 3f 00 movabs $0x400000003f000000,%rbx
1378: 00 00 40
137b: 48 23 5a fb and -0x5(%rdx),%rbx
137f: 48 89 da mov %rbx,%rdx
1382: 48 bb 00 00 00 06 00 movabs $0x4000000006000000,%rbx
1389: 00 00 40
138c: 48 39 da cmp %rbx,%rdx
138f: 0f 85 7b ff ff ff jne 1310 <Fmy_alist_get+0x20>
1395: 48 8b 40 03 mov 0x3(%rax),%rax
1399: 48 39 c1 cmp %rax,%rcx
139c: 0f 85 77 ff ff ff jne 1319 <Fmy_alist_get+0x29>
13a2: 49 8b 43 08 mov 0x8(%r11),%rax
13a6: 5b pop %rbx
13a7: 5e pop %rsi
13a8: c3 ret
13a9: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
13b0: 31 c0 xor %eax,%eax
13b2: 5b pop %rbx
13b3: 5e pop %rsi
13b4: c3 ret
13b5: 0f 1f 00 nopl (%rax)
13b8: 8d 5a fb lea -0x5(%rdx),%ebx
13bb: 49 8b 49 03 mov 0x3(%r9),%rcx
13bf: 48 89 d0 mov %rdx,%rax
13c2: 83 e3 07 and $0x7,%ebx
13c5: 0f 85 45 ff ff ff jne 1310 <Fmy_alist_get+0x20>
13cb: eb a4 jmp 1371 <Fmy_alist_get+0x81>
13cd: 0f 1f 00 nopl (%rax)
1 个赞
从代码长度看,my-plist-get长度是0xee,my-alist-get长度是0xdd,只看长度的话完全不像是1:2的样子。可能的原因是前者的代码会产生更大的流水线延迟。
include-yy的实验代码里并没有用到Emacs的FOR_EACH_TAIL宏,所以也可以排除是宏引入的代码的影响,那么问题出在遍历列表时的数据依赖。这里的my-plist-get是每轮过两个元素,而my-alist-get每轮过一个元素。那也就是说,执行EQ产生的延迟不如一个CDR大。
其实EQ就这两条有效指令。别的分支都是CONSP检查。看起来花在CONSP上的开销要更高,所以结点越多,复杂度出现线性增长。
如果你一定要做优化那我能想到的就是运行时去类型,但是要做这个支持只靠native-comp可能不够。native-comp只是把Lisp转译成了native指令,使用的Lisp原语实现仍然还是原来的实现。
2 个赞
用 Intel 的 vtune 在 Windows 下跑了 Hotspots 和 Microarchitecture Exploration。其中,Hotspots 结果如下:
alist,最前面的两条 XCONS 对应于汇编中的两条 LEA 指令,前一条 2.167s,后一条 8.981s,不知道是不是优化原因时间全算在 LEA 上了。
1320: 0f 84 8a 00 00 00 je 13b0 <Fmy_alist_get+0xc0>
1326: 48 8b 42 fd mov -0x3(%rdx),%rax
132a: 4c 8d 42 fd lea -0x3(%rdx),%r8 ;; 2.167s
132e: 4c 89 c9 mov %r9,%rcx
1331: 48 8b 50 fd mov -0x3(%rax),%rdx
1335: 4c 8d 58 fd lea -0x3(%rax),%r11 ;; 8.981s
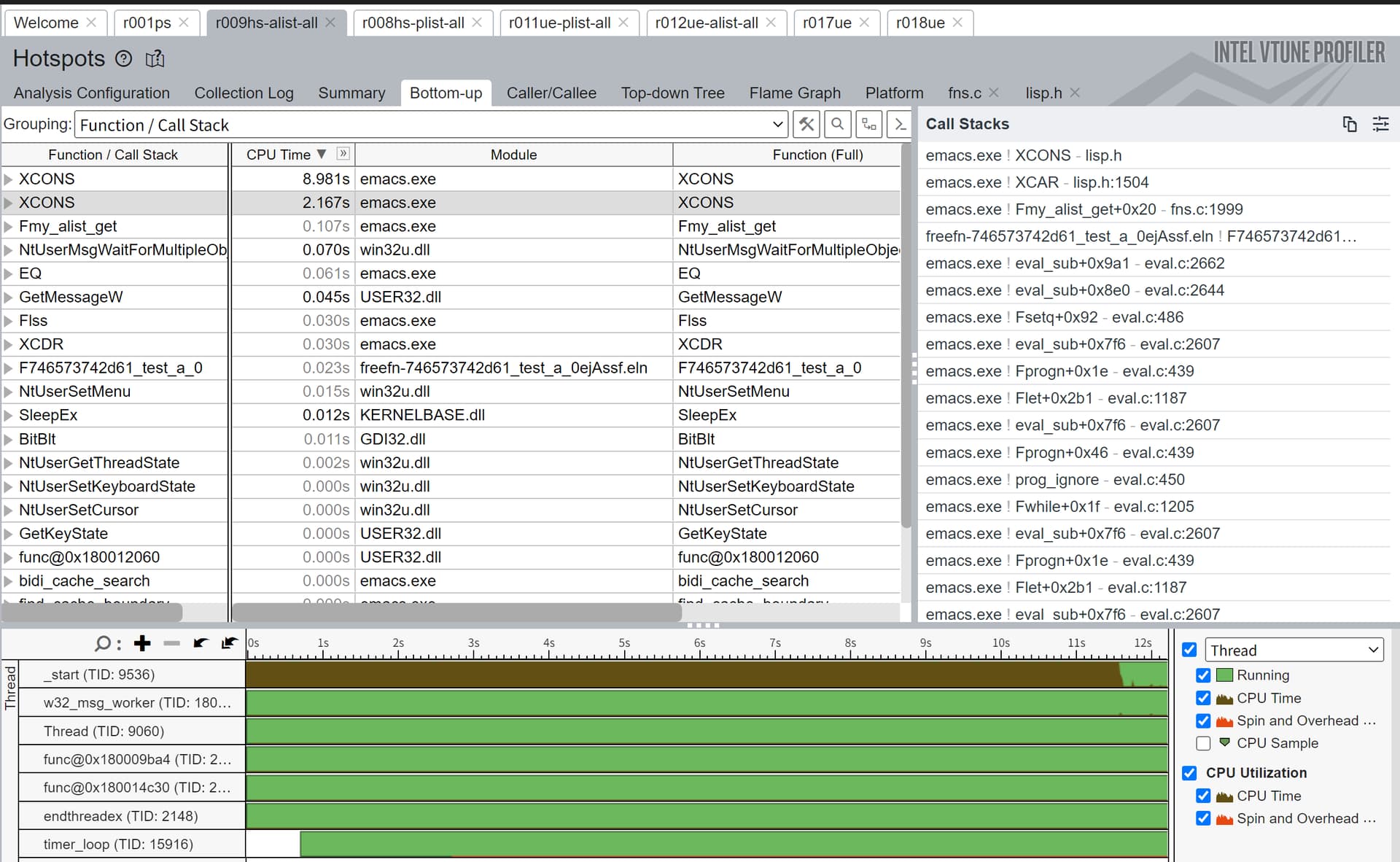
plist,和 plist 的唯一区别是多出的 Fmy_plist_get 时间,差不多正好是两条 XCONS 用时之和,我也不太懂为什么把时间统计到它上面了…
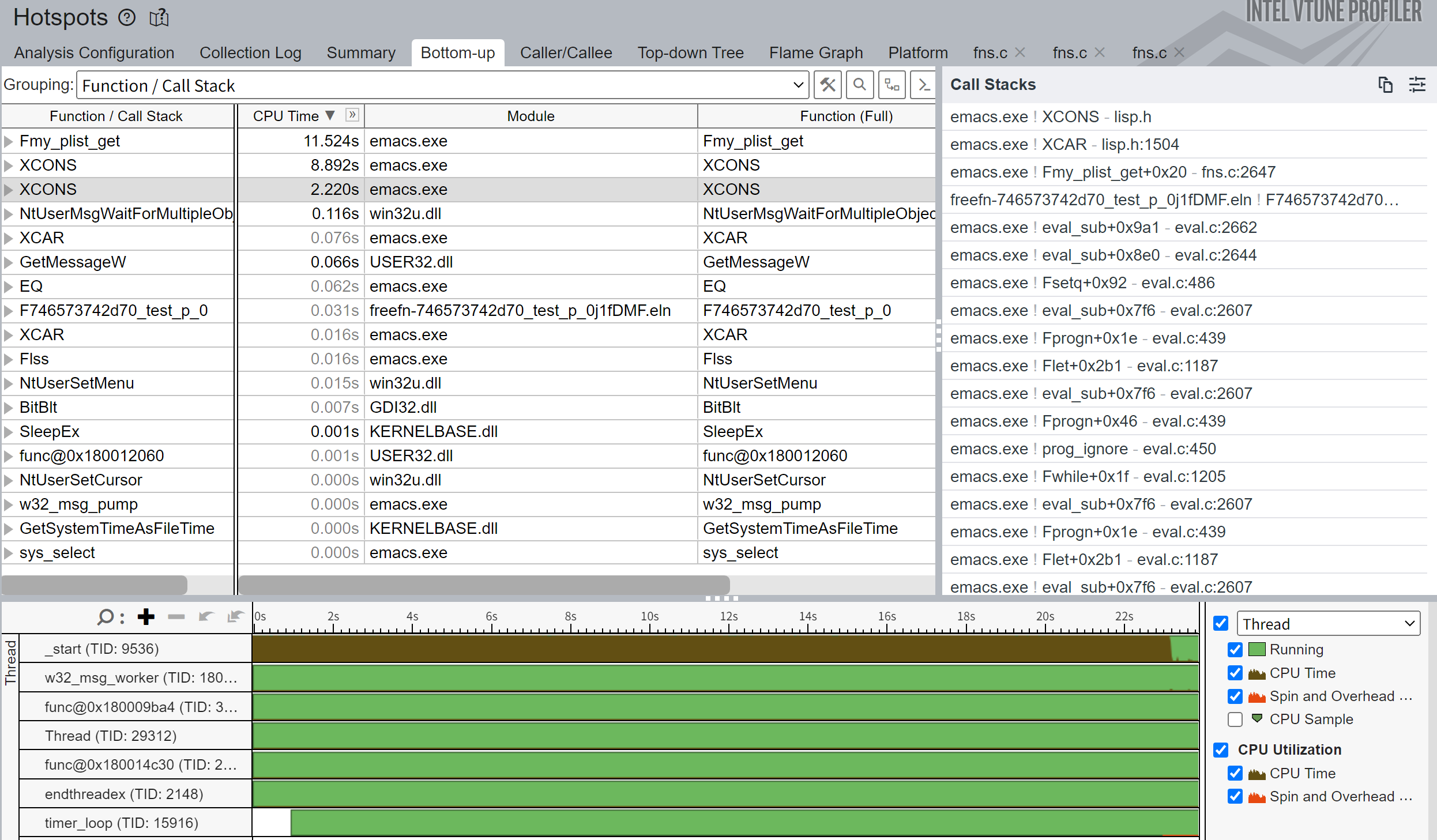
对照 vtune 里面的汇编(相比 AT&T 我更熟悉 Intel 格式一点),我手动反汇编了一下,去掉了 EQ 比较的 SYMBOL_WITH_POS_P 相关部分,不过注释部分还是对照上面帖子给出的汇编:
alist:
Fmy_alist_get (rdx /* alist */, rcx /* key */)
{
if (rdx == Qnil) // 12f5: test %rdx,%rdx
{ // 12f8: je 13b0 <Fmy_alist_get+0xc0>
eax = 0; // 13b0: xor %eax,%eax
return; // 13b4: ret
}
for (;;)
{
rax = mov_xcar(rdx); // 1326: mov -0x3(%rdx),%rax
r8 = lea_xcons(rdx); // 132a: lea -0x3(%rdx),%r8
rcx = r9; // 132e: mov %r9,%rcx
rdx = mov_xcar(rax); // 1331: mov -0x3(%rax),%rdx
r11 = lea_xcons(rax); // 1335: lea -0x3(%rax),%r11
rax = rdx; // 1339: mov %rdx,%rax
if (rax == rcx) // 1310: cmp %rax,%rcx
{ // 1313: je 13a2 <Fmy_alist_get+0xb2>
rax = mov_cdr(r11); // 13a2: mov 0x8(%r11),%rax
return; // 13a8: ret
}
rdx = mov_cdr(r8); // 1319: mov 0x8(%r8),%rdx
if (rdx == Qnil) // 131d: test %rdx,%rdx
{ // 1320: je 13b0 <Fmy_alist_get+0xc0>
eax = 0; // 13b0: xor %eax, %eax
return; // 13b4: ret
}
}
}
plist:
Fmy_plist_get(rdx /* key */, rcx /* plist */)
{
r9 = rdx; // 15b1: mov %rdx,%r9
if (rcx == Qnil) // 15b5: test %rcx,%rcx
{ // 15b7: je 1678 <Fmy_plist_get+0xc8>
eax = 0; // 1678: xor %eax,%eax
return; // 167b: ret
}
for(;;)
{
rdx = mov_xcar(rcx); // 15ee: mov -0x3(%rcx),%rdx
r8 = lea_xcons(rcx); // 15f2: lea -0x3(%rcx),%r8
rcx = r9; // 15f6: mov %r9,%rcx
rax = rdx; // 15f9: mov %rdx,%rax
rdx = mov_cdr(r8); // 15d0: mov 0x8(%r8),%rdx
r8 = lea_xcons(rdx); // 15d4: lea -0x3(%rdx),%r8
if (rcx == rax) // 15d8: cmp %rax,%rcx
{ // 15db: je 166c <Fmy_plist_get+0xbc>
rax = mov_xcar(rdx); // 166c: mov -0x3(%rdx),%rax
return; // 1671: ret
}
rcx = mov_cdr(r8); // 15e1: mov 0x8(%r8),%rcx
if (rcx == Qnil) // 15e5: test %rcx,%rcx
{ // 15e8: je 1678 <Fmy_plist_get+0xc8>
eax = 0; // 1678: xor %eax,%eax
return; // 167b: ret
}
}
}
如果有必要的话,可以想我一样分屏对比一下:
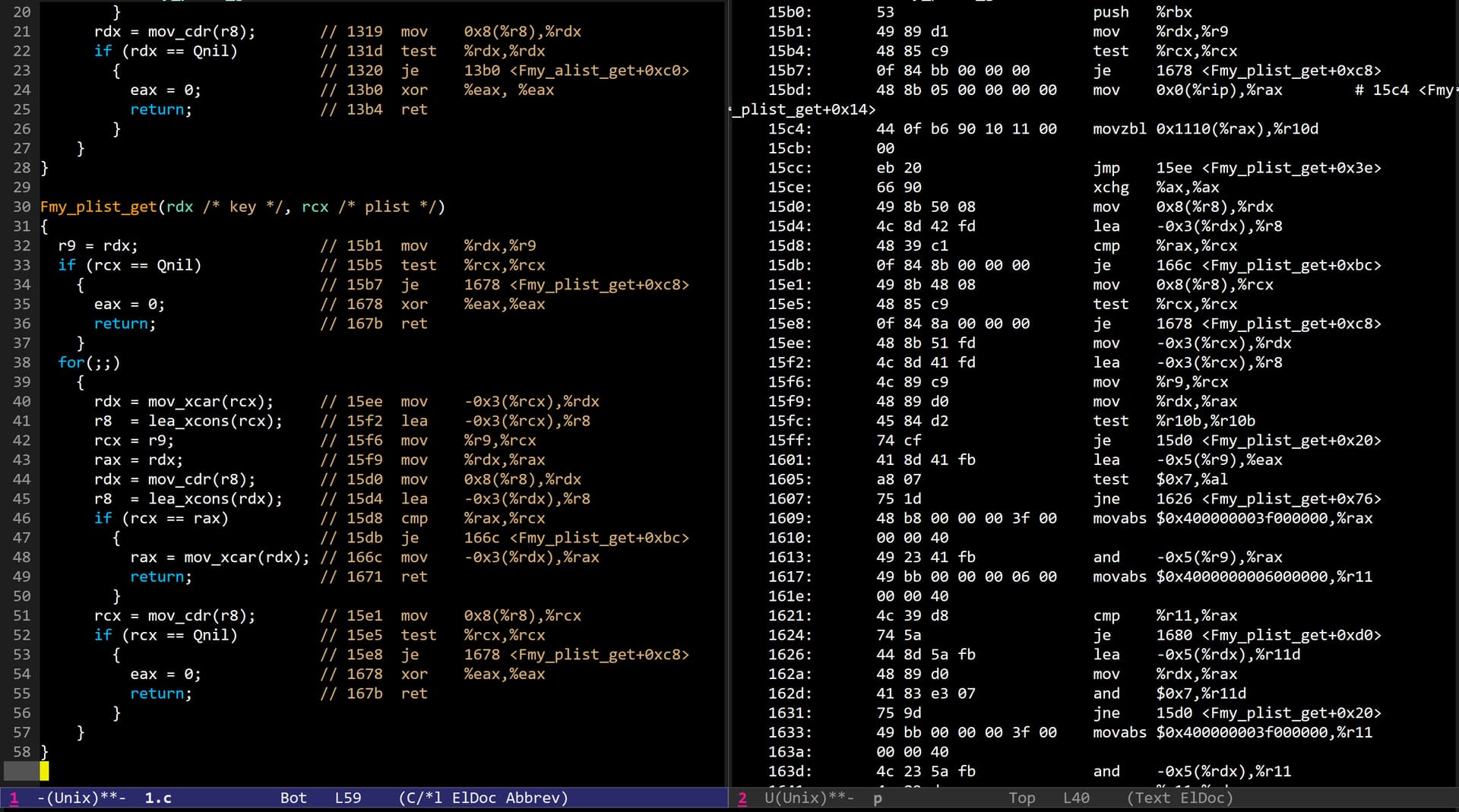
把 alist 和 plist 的循环部分稍作简化可以得到如下代码:
Fmy_alist_get_1()
{
loop {
kv_or_k_rax = xcar(alist_rdx);
p_r8 = xcons(alist_rdx);
key_rcx = key_r9;
k_rdx = xcar(kv_or_k_rax);
p_r11 = xcons(kv_or_k_rax);
kv_or_k_rax = k_rdx;
if (kv_or_k_rax == key_rcx) return;
alist_rdx = p_r8->cdr;
if (alist_rdx == Qnil) return;
}
}
这个代码给我一种感觉:只要拿到了 alist 的表头 KV cons,列表剩下的遍历就和当次循环的 「key 比较」和可能的「返回 KV 的值」操作无关了,也许可以并行?
Fmy_plist_get_1()
{
loop {
K1_p2_rdx = xcar(P1_k2_p3_rcx);
ptr_r8 = xcons(P1_k2_p3_rcx);
p1_K2_p3_rcx = key_r9;
k_rax = K1_p2_rdx;
k1_P2_rdx = ptr_r8->cdr;
ptr_r8 = xcons(k1_P2_rdx);
if (p1_K2_p3_rcx == k_rax) return;
p1_k2_P3_rcx = ptr_r8->cdr;
if (p1_k2_P3_rcx == Qnil) return;
}
}
类似 Fmy_alist_get_1 ,在拿到 plist 的当前 car 后比较操作就和遍历没关系了,但是每次遍历都有两次 LEA 和 MOV 操作。
就这个猜想来看,对于键值对相同的 plist 和 alist,对获取相同的 key 对应 value,列表长度应该就是两者效率的关键差距所在。
2 个赞
下图是对 plist 的 Microarchitecture Exploration 测试,结果如下:

vtune 里面给出的一些名词解释:
- MUX Reliability
- This metric estimates reliability of HW event-related metrics. Since the number of collected HW events exceeds the number of counters, VTune Profiler uses event multiplexing (MUX) to share HW counters and collect different subsets of events over time. This may affect the precision of collected event data. The ideal value for this metric is 1. If the value is less than 0.7, the collected data may be not reliable.
- Memory Bound
- This metric shows how memory subsystem issues affect the performance. Memory Bound measures a fraction of slots where pipeline could be stalled due to demand load or store instructions. This accounts mainly for incomplete in-flight memory demand loads that coincide with execution starvation in addition to less common cases where stores could imply back-pressure on the pipeline.
从测试结果来看,L1 Bound 和 Cycles of 1 Port Utilized 是最大的影响因素,我不知道为什么还有不到千分之一的指令跑到小核上去了,直接忽略。
下面是 alist 的测试结果:

从 Port Utilization 指标来看它要好于 plist。
最后简单列个表:
| CPI | Memory Bound | L1 Bound | Core Bound | Port Utilization | 0 | 1 | 2 | 3+ | |
|---|---|---|---|---|---|---|---|---|---|
| plist | 0.772 | 38.6% | 47.0% | 51.3% | 38.0% | 0.3% | 35.5% | 7.1% | 10.0% |
| alist | 0.385 | 11.2% | 17.8% | 58.8% | 43.3% | 0.2% | 33.2% | 18.0% | 27.0% |
下面是详细的测试数据:
| SUMMARY | ALIST | PLIST |
|---|---|---|
| Elapsed Time | 12.330s | 22.931s |
| Clockticks | 52,212,190,000 | 104,734,004,000 |
| Performance-core (P-core) | 52,212,190,000 | 104,734,004,000 |
| Efficient-core (E-core) | 1,157,404,000 | 58,976,000 |
| Low-power Efficient-core (LPE-core) | 0 | 0 |
| Instructions Retired | 135,736,950,000 | 135,604,254,000 |
| Performance-core (P-core) | 132,968,764,000 | 135,519,476,000 |
| Efficient-core (E-core) | 2,768,186,000 | 84,778,000 |
| Low-power Efficient-core (LPE-core) | 0 | 0 |
| CPI Rate | 0.385 | 0.772 |
| MUX Reliability | 0.987 | 0.969 |
| Performance-core (P-core) | ||
| Retiring | 24.3% | 12.9% |
| Front-End Bound | 0.8% | 0.7% |
| Bad Speculation | 4.9% | 0.0% |
| Back-End Bound | 70.0% | 89.9% |
| Memory Bound | 11.2% | 38.6% |
| L1 Bound | 17.8% | 47.0% |
| L2 Bound | 0.1% | 0.0% |
| L3 Bound | 0.1% | 0.1% |
| DRAM Bound | 0.1% | 0.0% |
| Store Bound | 0.0% | 0.0% |
| Core Bound | 58.8% | 51.3% |
| Divider | 0.0% | 0.0% |
| Serializing Operations | 0.4% | 0.3% |
| Port Utilization | 43.3% | 38.0% |
| Cycles of 0 Ports Utilized | 0.2% | 0.3% |
| Cycles of 1 Port Utilized | 33.2% | 35.5% |
| Cycles of 2 Ports Utilized | 18.0% | 7.1% |
| Cycles of 3+ Ports Utilized | 27.0% | 10.0% |
| Efficient-core (E-core) | ||
| Retiring | 25.5% | 23.7% |
| Front-End Bound | 2.8% | 17.8% |
| Bad Speculation | 2.3% | 7.4% |
| Back-End Bound | 64.0% | 100.0% |
| Core Bound | 0.7% | 1.5% |
| Resource Bound | 63.4% | 100.0% |
| Memory Scheduler | 0.3% | 0.0% |
| Non-memory Scheduler | 73.1% | 4.5% |
| Register | 0.0% | 0.0% |
| Full Re-order Buffer (ROB) | 0.0% | 0.0% |
| Serializing Operations | 0.9% | 7.4% |
| Info Metrics | ||
| Store Bound | 0.0% | 0.0% |
| Load Bound | 3.6% | 11.9% |
| L1 Bound | 1.2% | 0.0% |
| L2 Bound | 50.0% | 100.0% |
| L2 Miss | 75.0% | 0.0% |
| L3 Bound | 0.0% | 100.0% |
| L3 Miss | 75.0% | 0.0% |
| Low-power Efficient-core (LPE-core) | ||
| Retiring | 0.0% | 0.0% |
| Front-End Bound | 0.0% | 0.0% |
| Bad Speculation | 0.0% | 0.0% |
| Back-End Bound | 0.0% | 0.0% |
| Info Metrics | ||
| Average CPU Frequency | 4.7 GHz | 4.8 GHz |
| Total Thread Count | 3 | 3 |
| Paused Time | 0s | 0s |
3 个赞
好像没啥回复了,那我感觉也差不多了,做个总结吧。
省流版:pointer chasing。 @cireu
完整版:造成 eq 比较 alist/plist 性能差距的原因是在列表遍历过程中 plist 每次需要两次 CDR 而 alist 只需要一次,由于键值比较操作与列表遍历操作可并行且键值比较操作用时远小于内存读取开销(甚至是 L1-cache hit 开销)且链表遍历操作难以并行,查找的主要时间开销来源是在从表头到键值对所在位置的遍历过程。
上一节中的 VTune 指标说明中,Cycles of 1 Port Utilized 有几句话也许值得重复一下:
Cycles of 1 Port Utilized
This can be due to heavy data-dependency among software instructions, or oversubscribing a particular hardware resource.
…
In some other cases with high 1_Port_Utilized and L1 Bound, this metric can point to L1 data-cache latency bottleneck that may not necessarily manifest with complete execution starvation (due to the short L1 latency e.g. walking a linked list) - looking at the assembly can be helpful.
当 L1 Bound 和 Cycles of 1 Port Utilized 指标都比较高时,这表明可能存在一个 L1 数据缓存延迟瓶颈,这意味着即使数据在最快的 L1 缓存中,访问它仍然需要一些时间。而由于 L1 延迟很短,比如在遍历链表,这不一定会表现为完全的执行单元停顿(complete execution starvation)。
这一描述与我们上面的 Hotspots 测试是吻合的,因为 LEA 执行只需要一个指令周期,而 L1-cache hit 一般需要 5 个周期,缓存访问的时间被“错误”地算在了 LEA 上。考虑到上面的测试数据中 CPU 的平均频率是 4.7GHZ, (5 * 1 / 4.7HZ * 1E9) = 1.06ns ,差不多与 my-plist-get 和 my-alist-get 的键值对位置序号/访问时间的曲线斜率吻合。
如果代码是顺序执行的话 ,plist/alist 的查找理论上的算法复杂度根本没有任何区别。但我们可以注意到 my-plist-get 和 my-alist-get 中 遍历 和 键值判断 是 可以并行 的。
实际的执行过程中,由于 CPU 的 OOE(乱序执行,Out-of-Order Execution),alist 中键值判断的 (eq (car (car alist)) key) 与遍历操作 (cdr alist) 可以并行;plist 中的 (eq (car plist)) 与遍历操作 (cdr (cdr plist)) 可以并行。
因此实际的查找用时取决于查找项的位置(列表遍历用时)与最后一次键比较和取值用时。(这是我认为的可能性最大的情况)。
![]()
![]() ,感觉这个答案是拼起来的,列表长度,CPU 并行,缓存命中,汇编… 基本上什么都看了一遍。
,感觉这个答案是拼起来的,列表长度,CPU 并行,缓存命中,汇编… 基本上什么都看了一遍。
3 个赞
推荐用-g + perf annotate看汇编,效果跟我发的图里一样。
此外Emacs有一个包叫做disaster,也是支持显示反汇编对应代码行的。
如果你想对非debug的代码进行反编译,可以使用开源的ghidra工具。
intel后端µcode调度的深度完全可能有几十条µcode那么多,也就是说一条指令的µcode在完全retire之前,前面挤几十条µcode是完全有可能的。具体的调度细节不透明(即使透明,没有专门的工具,只靠软件也无法抓到等价的序列化代码),只能看各种统计参数。编译器只能保证生成的指令流包含正确的数据依赖,并不能决定这些代码实际如何被以什么顺序执行。
2 个赞
装个 WSL2 再去试试,VTune 的信息确实太简略了。
VTune我没用过,看这个界面跟perf差不多,底层用到的硬件支持应该一样的。
这样说的话,我在 WSL 里面跑不知道能不能用上一些硬件特性,毕竟就是虚拟机。
算了,先试试去。
应该是可以的
1 个赞
测试环境:Linux UM760 6.6.87.1-microsoft-standard-WSL2
编译器:gcc (Ubuntu 13.3.0-6ubuntu2~24.04) 13.3.0
测试代码与上面的基本一致。
perf 命令: perf record -F 99 -p 2055 -g -e cpu-clock:u 与 perf annotate -i perf.data
my-plist-get 结果及汇编:
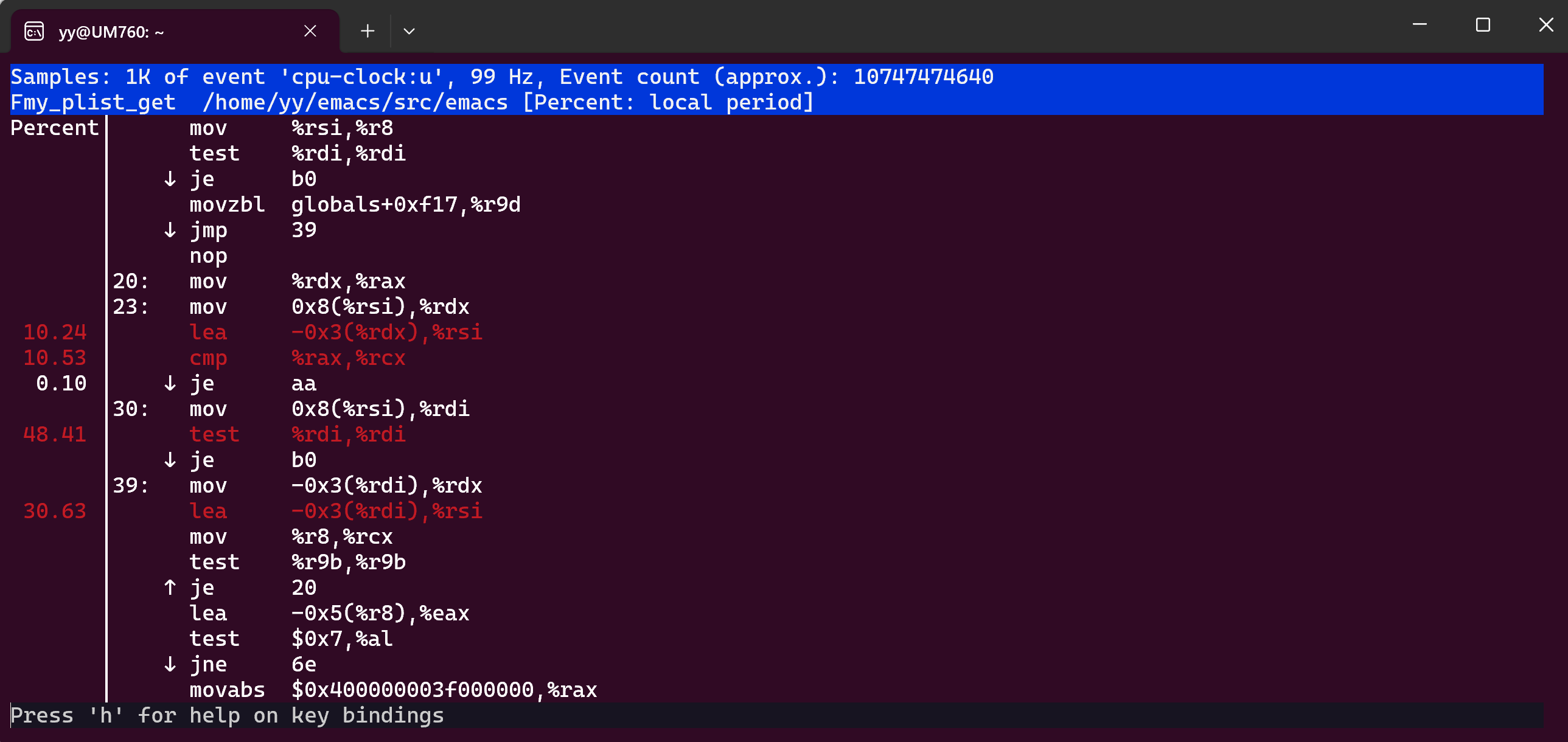
objdump -d -S fns.o > xxx.txt
000000000017a950 <Fmy_plist_get>:
{
17a950: f3 0f 1e fa endbr64
17a954: 49 89 f0 mov %rsi,%r8
for(; !NILP (plist); plist = XCDR (XCDR (plist)))
17a957: 48 85 ff test %rdi,%rdi
17a95a: 0f 84 a0 00 00 00 je 17aa00 <Fmy_plist_get+0xb0>
(__builtin_expect (symbols_with_pos_enabled, false)
17a960: 44 0f b6 0d ef 08 17 movzbl 0x1708ef(%rip),%r9d # 2eb257 <globals+0xf17>
17a967: 00
17a968: eb 1f jmp 17a989 <Fmy_plist_get+0x39>
17a96a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
return lisp_h_XLI (o);
17a970: 48 89 d0 mov %rdx,%rax
return XUNTAG (a, Lisp_Cons, struct Lisp_Cons);
17a973: 48 8b 56 08 mov 0x8(%rsi),%rdx
17a977: 48 8d 72 fd lea -0x3(%rdx),%rsi
if (EQ (XCAR (plist), prop))
17a97b: 48 39 c1 cmp %rax,%rcx
17a97e: 74 7a je 17a9fa <Fmy_plist_get+0xaa>
return lisp_h_XCDR (c);
17a980: 48 8b 7e 08 mov 0x8(%rsi),%rdi
for(; !NILP (plist); plist = XCDR (XCDR (plist)))
17a984: 48 85 ff test %rdi,%rdi
17a987: 74 77 je 17aa00 <Fmy_plist_get+0xb0>
return lisp_h_XCAR (c);
17a989: 48 8b 57 fd mov -0x3(%rdi),%rdx
return XUNTAG (a, Lisp_Cons, struct Lisp_Cons);
17a98d: 48 8d 77 fd lea -0x3(%rdi),%rsi
return lisp_h_XLI (o);
17a991: 4c 89 c1 mov %r8,%rcx
return BASE_EQ ((__builtin_expect (symbols_with_pos_enabled, false)
17a994: 45 84 c9 test %r9b,%r9b
17a997: 74 d7 je 17a970 <Fmy_plist_get+0x20>
return lisp_h_TAGGEDP (a, tag);
17a999: 41 8d 40 fb lea -0x5(%r8),%eax
&& ((XUNTAG (a, Lisp_Vectorlike, union vectorlike_header)->size
17a99d: a8 07 test $0x7,%al
17a99f: 75 1d jne 17a9be <Fmy_plist_get+0x6e>
& (PSEUDOVECTOR_FLAG | PVEC_TYPE_MASK))
17a9a1: 48 b8 00 00 00 3f 00 movabs $0x400000003f000000,%rax
17a9a8: 00 00 40
17a9ab: 49 23 40 fb and -0x5(%r8),%rax
&& ((XUNTAG (a, Lisp_Vectorlike, union vectorlike_header)->size
17a9af: 48 bf 00 00 00 06 00 movabs $0x4000000006000000,%rdi
17a9b6: 00 00 40
17a9b9: 48 39 f8 cmp %rdi,%rax
17a9bc: 74 4a je 17aa08 <Fmy_plist_get+0xb8>
return lisp_h_TAGGEDP (a, tag);
17a9be: 8d 7a fb lea -0x5(%rdx),%edi
return lisp_h_XLI (o);
17a9c1: 48 89 d0 mov %rdx,%rax
&& ((XUNTAG (a, Lisp_Vectorlike, union vectorlike_header)->size
17a9c4: 83 e7 07 and $0x7,%edi
17a9c7: 75 aa jne 17a973 <Fmy_plist_get+0x23>
& (PSEUDOVECTOR_FLAG | PVEC_TYPE_MASK))
17a9c9: 48 bf 00 00 00 3f 00 movabs $0x400000003f000000,%rdi
17a9d0: 00 00 40
17a9d3: 48 23 7a fb and -0x5(%rdx),%rdi
17a9d7: 48 89 fa mov %rdi,%rdx
&& ((XUNTAG (a, Lisp_Vectorlike, union vectorlike_header)->size
17a9da: 48 bf 00 00 00 06 00 movabs $0x4000000006000000,%rdi
17a9e1: 00 00 40
17a9e4: 48 39 fa cmp %rdi,%rdx
17a9e7: 75 8a jne 17a973 <Fmy_plist_get+0x23>
return XUNTAG (a, Lisp_Cons, struct Lisp_Cons);
17a9e9: 48 8b 56 08 mov 0x8(%rsi),%rdx
return lisp_h_XLI (o);
17a9ed: 48 8b 40 03 mov 0x3(%rax),%rax
return XUNTAG (a, Lisp_Cons, struct Lisp_Cons);
17a9f1: 48 8d 72 fd lea -0x3(%rdx),%rsi
if (EQ (XCAR (plist), prop))
17a9f5: 48 39 c1 cmp %rax,%rcx
17a9f8: 75 86 jne 17a980 <Fmy_plist_get+0x30>
return lisp_h_XCAR (c);
17a9fa: 48 8b 42 fd mov -0x3(%rdx),%rax
return XCAR (XCDR (plist));
17a9fe: c3 ret
17a9ff: 90 nop
return Qnil;
17aa00: 31 c0 xor %eax,%eax
}
17aa02: c3 ret
17aa03: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
return lisp_h_TAGGEDP (a, tag);
17aa08: 8d 7a fb lea -0x5(%rdx),%edi
return lisp_h_XLI (o);
17aa0b: 49 8b 48 03 mov 0x3(%r8),%rcx
17aa0f: 48 89 d0 mov %rdx,%rax
&& ((XUNTAG (a, Lisp_Vectorlike, union vectorlike_header)->size
17aa12: 83 e7 07 and $0x7,%edi
17aa15: 0f 85 58 ff ff ff jne 17a973 <Fmy_plist_get+0x23>
17aa1b: eb ac jmp 17a9c9 <Fmy_plist_get+0x79>
17aa1d: 0f 1f 00 nopl (%rax)
无源代码版
0000000000001320 <Fmy_plist_get>:
1320: f3 0f 1e fa endbr64
1324: 49 89 f0 mov %rsi,%r8
1327: 48 85 ff test %rdi,%rdi
132a: 0f 84 a0 00 00 00 je 13d0 <Fmy_plist_get+0xb0>
1330: 44 0f b6 0d 00 00 00 movzbl 0x0(%rip),%r9d # 1338 <Fmy_plist_get+0x18>
1337: 00
1338: eb 1f jmp 1359 <Fmy_plist_get+0x39>
133a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
1340: 48 89 d0 mov %rdx,%rax
1343: 48 8b 56 08 mov 0x8(%rsi),%rdx
1347: 48 8d 72 fd lea -0x3(%rdx),%rsi
134b: 48 39 c1 cmp %rax,%rcx
134e: 74 7a je 13ca <Fmy_plist_get+0xaa>
1350: 48 8b 7e 08 mov 0x8(%rsi),%rdi
1354: 48 85 ff test %rdi,%rdi
1357: 74 77 je 13d0 <Fmy_plist_get+0xb0>
1359: 48 8b 57 fd mov -0x3(%rdi),%rdx
135d: 48 8d 77 fd lea -0x3(%rdi),%rsi
1361: 4c 89 c1 mov %r8,%rcx
1364: 45 84 c9 test %r9b,%r9b
1367: 74 d7 je 1340 <Fmy_plist_get+0x20>
1369: 41 8d 40 fb lea -0x5(%r8),%eax
136d: a8 07 test $0x7,%al
136f: 75 1d jne 138e <Fmy_plist_get+0x6e>
1371: 48 b8 00 00 00 3f 00 movabs $0x400000003f000000,%rax
1378: 00 00 40
137b: 49 23 40 fb and -0x5(%r8),%rax
137f: 48 bf 00 00 00 06 00 movabs $0x4000000006000000,%rdi
1386: 00 00 40
1389: 48 39 f8 cmp %rdi,%rax
138c: 74 4a je 13d8 <Fmy_plist_get+0xb8>
138e: 8d 7a fb lea -0x5(%rdx),%edi
1391: 48 89 d0 mov %rdx,%rax
1394: 83 e7 07 and $0x7,%edi
1397: 75 aa jne 1343 <Fmy_plist_get+0x23>
1399: 48 bf 00 00 00 3f 00 movabs $0x400000003f000000,%rdi
13a0: 00 00 40
13a3: 48 23 7a fb and -0x5(%rdx),%rdi
13a7: 48 89 fa mov %rdi,%rdx
13aa: 48 bf 00 00 00 06 00 movabs $0x4000000006000000,%rdi
13b1: 00 00 40
13b4: 48 39 fa cmp %rdi,%rdx
13b7: 75 8a jne 1343 <Fmy_plist_get+0x23>
13b9: 48 8b 56 08 mov 0x8(%rsi),%rdx
13bd: 48 8b 40 03 mov 0x3(%rax),%rax
13c1: 48 8d 72 fd lea -0x3(%rdx),%rsi
13c5: 48 39 c1 cmp %rax,%rcx
13c8: 75 86 jne 1350 <Fmy_plist_get+0x30>
13ca: 48 8b 42 fd mov -0x3(%rdx),%rax
13ce: c3 ret
13cf: 90 nop
13d0: 31 c0 xor %eax,%eax
13d2: c3 ret
13d3: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
13d8: 8d 7a fb lea -0x5(%rdx),%edi
13db: 49 8b 48 03 mov 0x3(%r8),%rcx
13df: 48 89 d0 mov %rdx,%rax
13e2: 83 e7 07 and $0x7,%edi
13e5: 0f 85 58 ff ff ff jne 1343 <Fmy_plist_get+0x23>
13eb: eb ac jmp 1399 <Fmy_plist_get+0x79>
13ed: 0f 1f 00 nopl (%rax)
my-alist-get 及汇编:

0000000000001250 <Fmy_alist_get>:
{
1250: f3 0f 1e fa endbr64
1254: 49 89 f8 mov %rdi,%r8
for (; ! NILP (alist); alist = XCDR (alist))
1257: 48 85 f6 test %rsi,%rsi
125a: 0f 84 a0 00 00 00 je 1300 <Fmy_alist_get+0xb0>
(__builtin_expect (symbols_with_pos_enabled, false)
1260: 44 0f b6 0d 00 00 00 movzbl 0x0(%rip),%r9d # 1268 <Fmy_alist_get+0x18>
1267: 00
1268: eb 17 jmp 1281 <Fmy_alist_get+0x31>
126a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
return lisp_h_XLI (o);
1270: 48 89 d0 mov %rdx,%rax
if (EQ (XCAR (XCAR (alist)), key))
1273: 48 39 c8 cmp %rcx,%rax
1276: 74 7c je 12f4 <Fmy_alist_get+0xa4>
return lisp_h_XCDR (c);
1278: 48 8b 77 08 mov 0x8(%rdi),%rsi
for (; ! NILP (alist); alist = XCDR (alist))
127c: 48 85 f6 test %rsi,%rsi
127f: 74 7f je 1300 <Fmy_alist_get+0xb0>
return XUNTAG (a, Lisp_Cons, struct Lisp_Cons);
1281: 48 8b 46 fd mov -0x3(%rsi),%rax
1285: 48 8d 7e fd lea -0x3(%rsi),%rdi
return lisp_h_XLI (o);
1289: 4c 89 c1 mov %r8,%rcx
return lisp_h_XCAR (c);
128c: 48 8b 50 fd mov -0x3(%rax),%rdx
return XUNTAG (a, Lisp_Cons, struct Lisp_Cons);
1290: 48 8d 70 fd lea -0x3(%rax),%rsi
return BASE_EQ ((__builtin_expect (symbols_with_pos_enabled, false)
1294: 45 84 c9 test %r9b,%r9b
1297: 74 d7 je 1270 <Fmy_alist_get+0x20>
return lisp_h_TAGGEDP (a, tag);
1299: 41 8d 40 fb lea -0x5(%r8),%eax
&& ((XUNTAG (a, Lisp_Vectorlike, union vectorlike_header)->size
129d: a8 07 test $0x7,%al
129f: 75 1d jne 12be <Fmy_alist_get+0x6e>
& (PSEUDOVECTOR_FLAG | PVEC_TYPE_MASK))
12a1: 48 b8 00 00 00 3f 00 movabs $0x400000003f000000,%rax
12a8: 00 00 40
12ab: 49 23 40 fb and -0x5(%r8),%rax
&& ((XUNTAG (a, Lisp_Vectorlike, union vectorlike_header)->size
12af: 49 ba 00 00 00 06 00 movabs $0x4000000006000000,%r10
12b6: 00 00 40
12b9: 4c 39 d0 cmp %r10,%rax
12bc: 74 4a je 1308 <Fmy_alist_get+0xb8>
return lisp_h_TAGGEDP (a, tag);
12be: 44 8d 52 fb lea -0x5(%rdx),%r10d
return lisp_h_XLI (o);
12c2: 48 89 d0 mov %rdx,%rax
&& ((XUNTAG (a, Lisp_Vectorlike, union vectorlike_header)->size
12c5: 41 83 e2 07 and $0x7,%r10d
12c9: 75 a8 jne 1273 <Fmy_alist_get+0x23>
& (PSEUDOVECTOR_FLAG | PVEC_TYPE_MASK))
12cb: 49 ba 00 00 00 3f 00 movabs $0x400000003f000000,%r10
12d2: 00 00 40
12d5: 4c 23 52 fb and -0x5(%rdx),%r10
12d9: 4c 89 d2 mov %r10,%rdx
&& ((XUNTAG (a, Lisp_Vectorlike, union vectorlike_header)->size
12dc: 49 ba 00 00 00 06 00 movabs $0x4000000006000000,%r10
12e3: 00 00 40
12e6: 4c 39 d2 cmp %r10,%rdx
12e9: 75 88 jne 1273 <Fmy_alist_get+0x23>
return lisp_h_XLI (o);
12eb: 48 8b 40 03 mov 0x3(%rax),%rax
if (EQ (XCAR (XCAR (alist)), key))
12ef: 48 39 c8 cmp %rcx,%rax
12f2: 75 84 jne 1278 <Fmy_alist_get+0x28>
return lisp_h_XCDR (c);
12f4: 48 8b 46 08 mov 0x8(%rsi),%rax
return XCDR (XCAR (alist));
12f8: c3 ret
12f9: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
return Qnil;
1300: 31 c0 xor %eax,%eax
}
1302: c3 ret
1303: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
return lisp_h_TAGGEDP (a, tag);
1308: 44 8d 52 fb lea -0x5(%rdx),%r10d
return lisp_h_XLI (o);
130c: 49 8b 48 03 mov 0x3(%r8),%rcx
1310: 48 89 d0 mov %rdx,%rax
&& ((XUNTAG (a, Lisp_Vectorlike, union vectorlike_header)->size
1313: 41 83 e2 07 and $0x7,%r10d
1317: 0f 85 56 ff ff ff jne 1273 <Fmy_alist_get+0x23>
131d: eb ac jmp 12cb <Fmy_alist_get+0x7b>
131f: 90 nop
0000000000001250 <Fmy_alist_get>:
1250: f3 0f 1e fa endbr64
1254: 49 89 f8 mov %rdi,%r8
1257: 48 85 f6 test %rsi,%rsi
125a: 0f 84 a0 00 00 00 je 1300 <Fmy_alist_get+0xb0>
1260: 44 0f b6 0d 00 00 00 movzbl 0x0(%rip),%r9d # 1268 <Fmy_alist_get+0x18>
1267: 00
1268: eb 17 jmp 1281 <Fmy_alist_get+0x31>
126a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
1270: 48 89 d0 mov %rdx,%rax
1273: 48 39 c8 cmp %rcx,%rax
1276: 74 7c je 12f4 <Fmy_alist_get+0xa4>
1278: 48 8b 77 08 mov 0x8(%rdi),%rsi
127c: 48 85 f6 test %rsi,%rsi
127f: 74 7f je 1300 <Fmy_alist_get+0xb0>
1281: 48 8b 46 fd mov -0x3(%rsi),%rax
1285: 48 8d 7e fd lea -0x3(%rsi),%rdi
1289: 4c 89 c1 mov %r8,%rcx
128c: 48 8b 50 fd mov -0x3(%rax),%rdx
1290: 48 8d 70 fd lea -0x3(%rax),%rsi
1294: 45 84 c9 test %r9b,%r9b
1297: 74 d7 je 1270 <Fmy_alist_get+0x20>
1299: 41 8d 40 fb lea -0x5(%r8),%eax
129d: a8 07 test $0x7,%al
129f: 75 1d jne 12be <Fmy_alist_get+0x6e>
12a1: 48 b8 00 00 00 3f 00 movabs $0x400000003f000000,%rax
12a8: 00 00 40
12ab: 49 23 40 fb and -0x5(%r8),%rax
12af: 49 ba 00 00 00 06 00 movabs $0x4000000006000000,%r10
12b6: 00 00 40
12b9: 4c 39 d0 cmp %r10,%rax
12bc: 74 4a je 1308 <Fmy_alist_get+0xb8>
12be: 44 8d 52 fb lea -0x5(%rdx),%r10d
12c2: 48 89 d0 mov %rdx,%rax
12c5: 41 83 e2 07 and $0x7,%r10d
12c9: 75 a8 jne 1273 <Fmy_alist_get+0x23>
12cb: 49 ba 00 00 00 3f 00 movabs $0x400000003f000000,%r10
12d2: 00 00 40
12d5: 4c 23 52 fb and -0x5(%rdx),%r10
12d9: 4c 89 d2 mov %r10,%rdx
12dc: 49 ba 00 00 00 06 00 movabs $0x4000000006000000,%r10
12e3: 00 00 40
12e6: 4c 39 d2 cmp %r10,%rdx
12e9: 75 88 jne 1273 <Fmy_alist_get+0x23>
12eb: 48 8b 40 03 mov 0x3(%rax),%rax
12ef: 48 39 c8 cmp %rcx,%rax
12f2: 75 84 jne 1278 <Fmy_alist_get+0x28>
12f4: 48 8b 46 08 mov 0x8(%rsi),%rax
12f8: c3 ret
12f9: 0f 1f 80 00 00 00 00 nopl 0x0(%rax)
1300: 31 c0 xor %eax,%eax
1302: c3 ret
1303: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
1308: 44 8d 52 fb lea -0x5(%rdx),%r10d
130c: 49 8b 48 03 mov 0x3(%r8),%rcx
1310: 48 89 d0 mov %rdx,%rax
1313: 41 83 e2 07 and $0x7,%r10d
1317: 0f 85 56 ff ff ff jne 1273 <Fmy_alist_get+0x23>
131d: eb ac jmp 12cb <Fmy_alist_get+0x7b>
131f: 90 nop
顺带一提,这是这俩的曲线:
1 个赞