我主要是想把 ppt 某一页的快照根据 org 链接自动插入到 org 里,因为 ppt 本身就是保存在本地的,如果截图插入 org 的话,还要额外维护一份截图文件,但如果程序化了,那么图片丢失了再生成一次就行了。
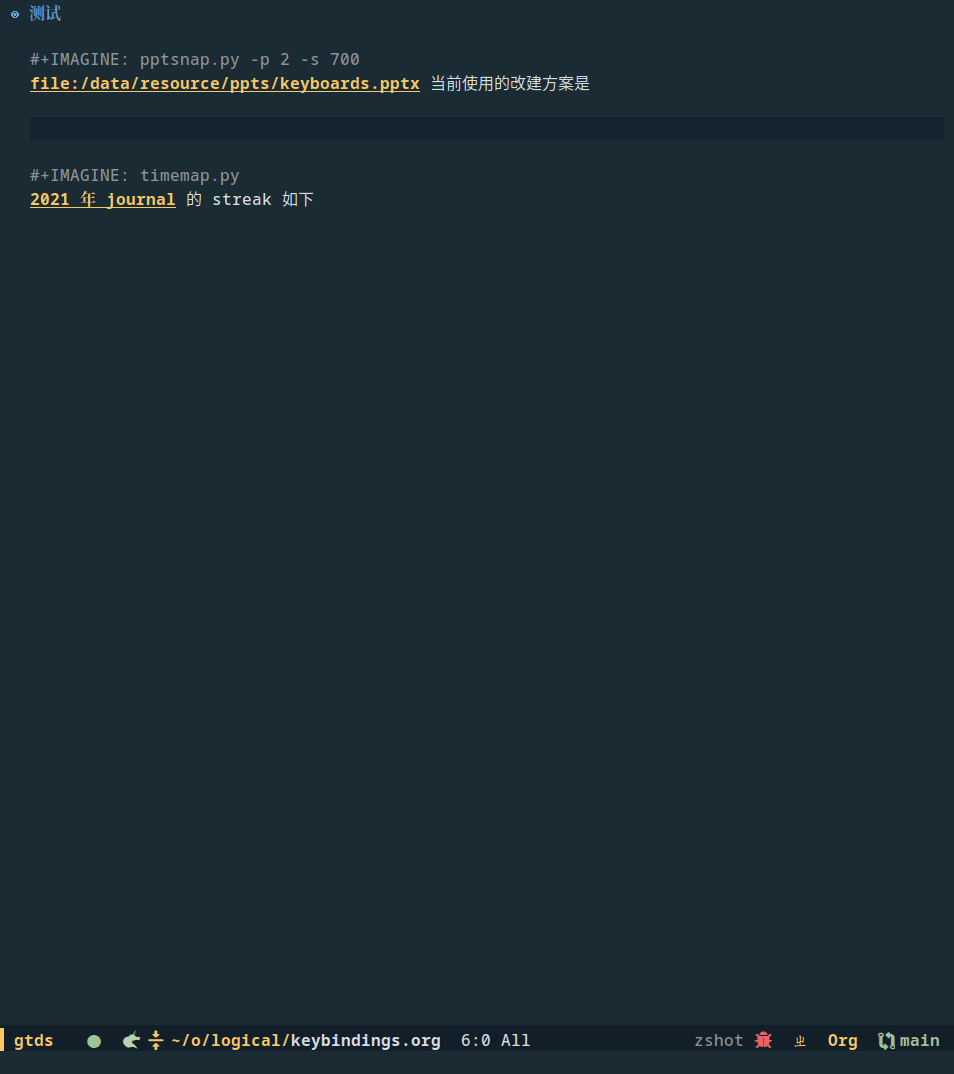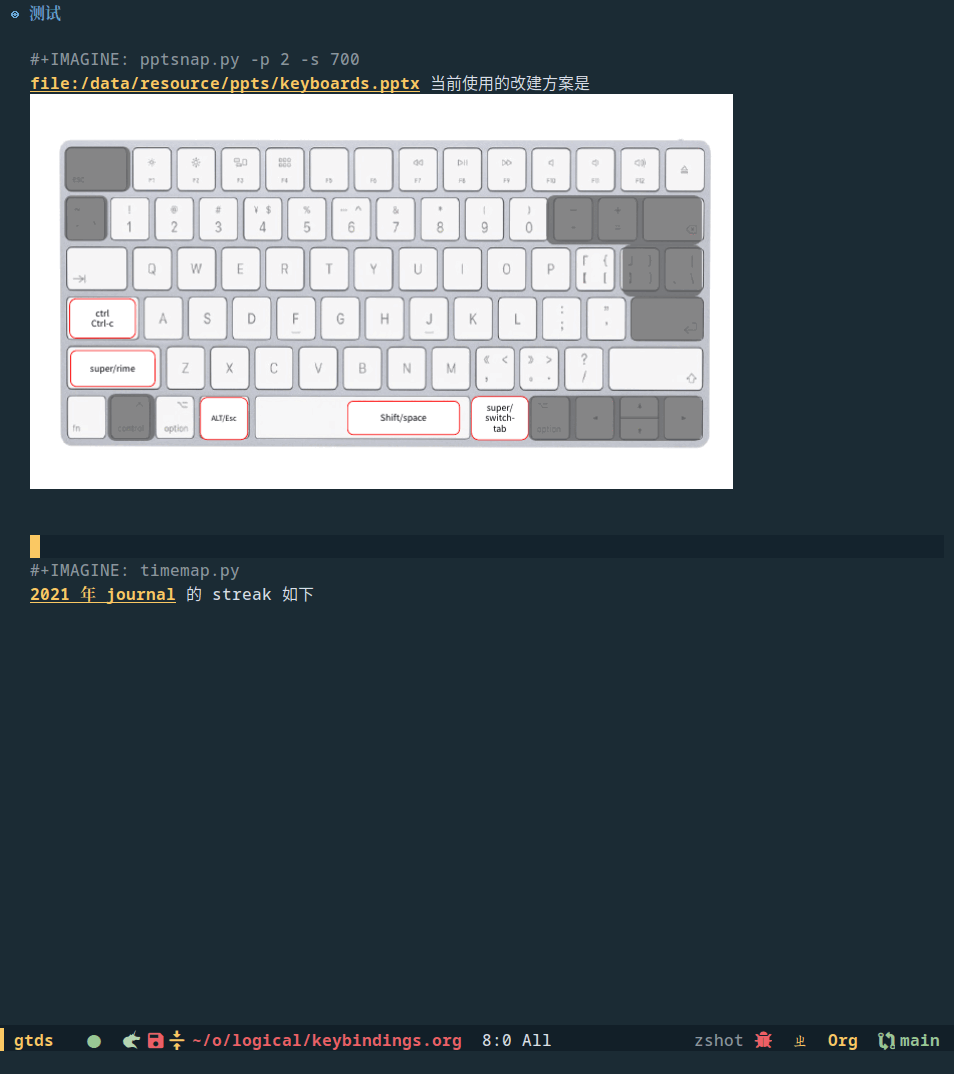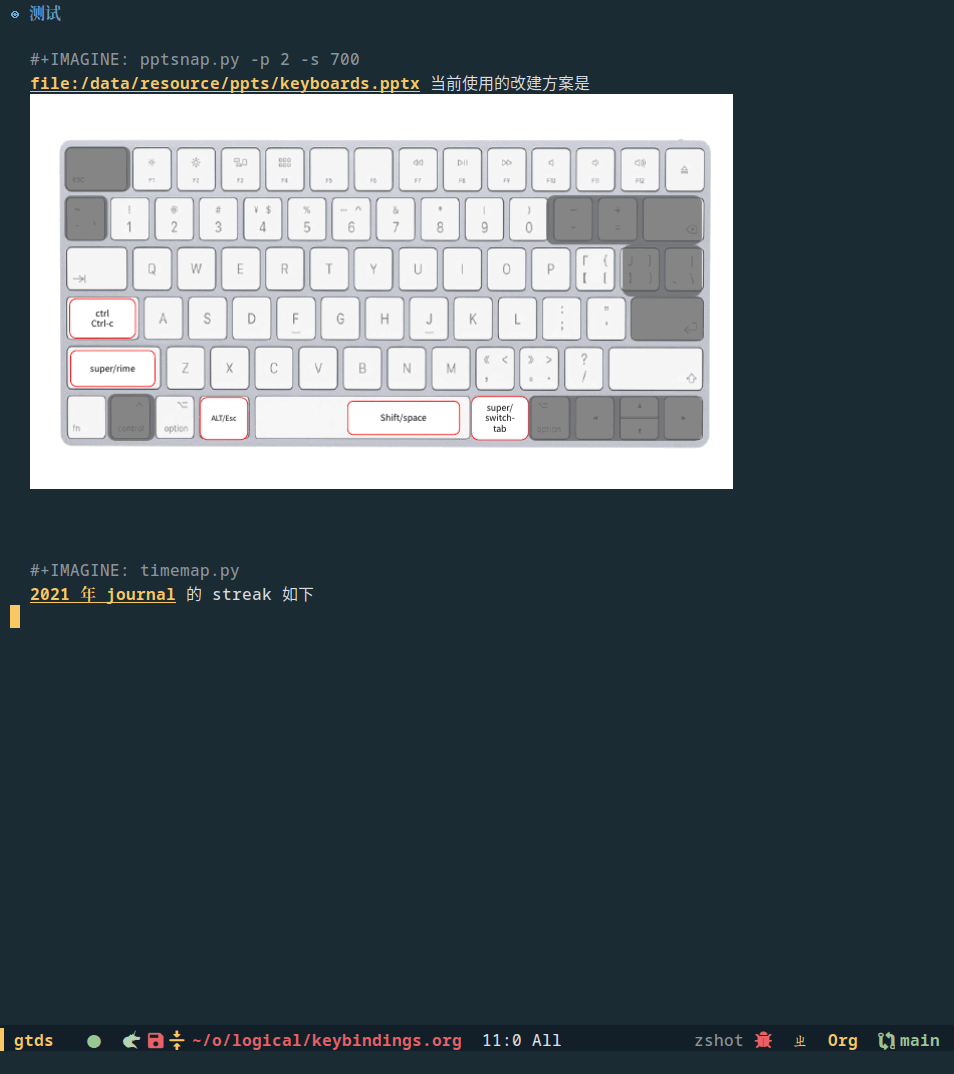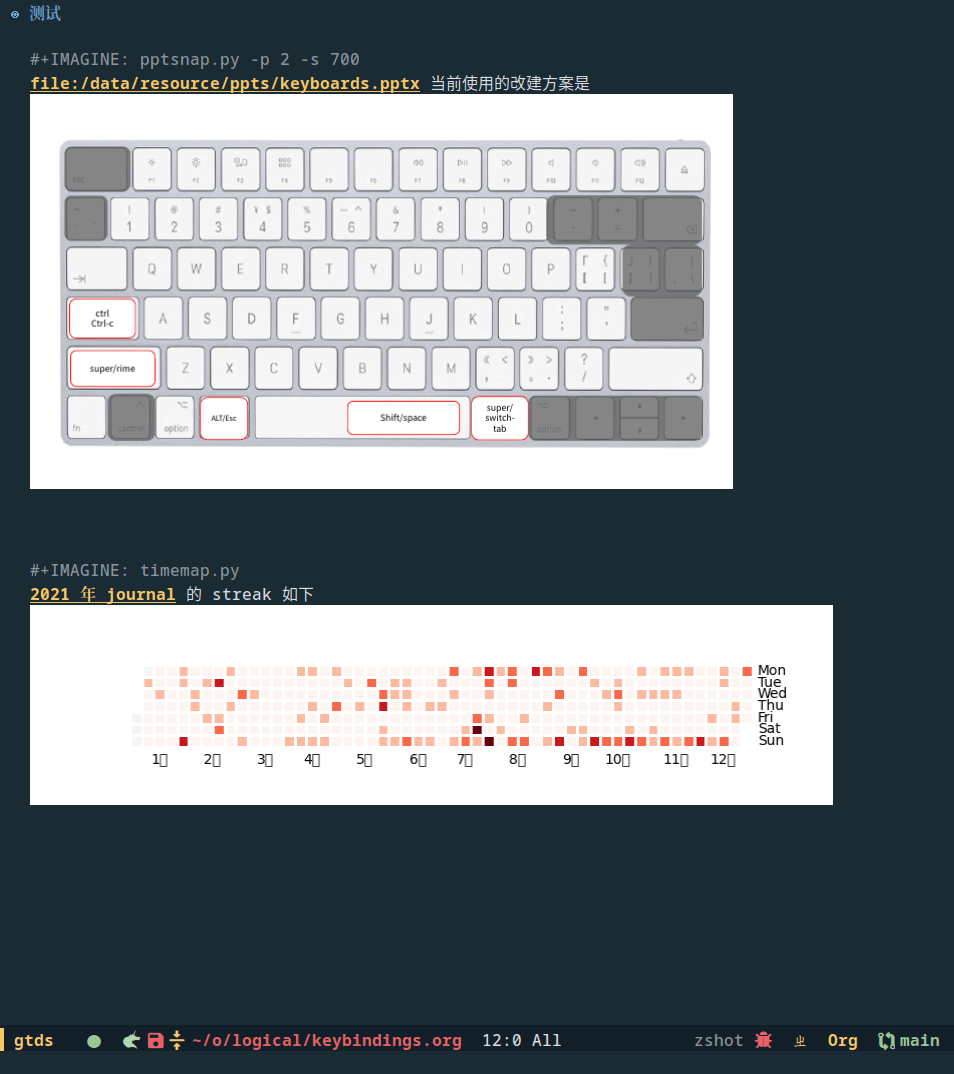
之后发现既然解析 ppt 都是用外部程序,那么只要预先编写一些常用的可视化脚本,org 里任何对象都可以图片可视化了,比如以下对记日记的频率信息显示成 github streak 形式,我日记里都是用 [2022-09-04 Sun 10:32] 形式的时间戳来记录时间,因此就是搜集所有时间戳再 plot 出来,这依赖 python 的 calmap,pandas 包
最初的想法参见
pdf 也适合这种需求场景,比如某一页 pdf 是个示意图或者大表格,做笔记的时候引用这一页时还能显示图片,想看上下文点进去就打开 pdf。
这么一说,我又觉得这类功能或许应该抽象成一个通用的框架,更像是协议性质的,增加一种 org link 的语法,比如叫做 filepreview
那么在配置文件里,只需要对不同后缀(格式)的文件设置一个转成图片的命令和命令参数,比如以下设置:
(setq filepreview-preview-command
'(("\\.ps" "convert %s.ps %s_hash.png")
("\\.pptx" "convert %s.pptx %s_hash.jpg -page %d")
("\\.pdf" "convert %s.pptx %s_hash.jpg -page %d -rotate 90")
("\\.mm" "convert %s.mm %s_hash.jpg")
)
(setq filepreview-cache-folder ~/org/.previewcache)
以上 convert 语法都是伪代…
但是发现重新添加一种 org link 会很麻烦,比如还要考虑 export 的格式问题,因此用类似 GitHub - nobiot/org-transclusion: Emacs package to enable transclusion with Org Mode 的方式, org-transclusion 是把一个虚假的 文本 block 插入到当前位置(实际插入一个链接), org-imagine 是把虚假的图片插入到当前位置(实际插入图片链接),但 org-imagine 比 org-transclusion 简单多了,因为完全不需要考虑同步编辑的问题,另外这种直接插入以 hash 命名的图片链接的方式是参照 ob-jupyter。
如果了解 org-babel, 这个包可以类比成是预编写好的 jupyter block,只是处理的对象是 org 元素,当前只实现了对 file: 和 pdf: link 的解析,满足了我自己的需求,后续看实际情况考虑是否加入其他对象,例如可视化表格,文本段落等。
欢迎有兴趣的朋友试用,也可以编写自己的可视化脚本,因为可视化是一件比较个性化的活动,除了某些固定格式的文件的 preview (这里还涉及 preview 的大小、是否要裁剪等偏好),大部分场景下如何可视化还是要以自己的需求来发挥想象,这也是叫做 org imagine 的原因。
详细说明见
15 个赞
谢谢, 我是 ubuntu 用户, pptsnap.py 里是用 libreoffice 和 pdftoppm 把 ppt 转成图片的,这两个 ubuntu 基本自带了,原本以为 python 可以处理,这样只要 pip 安装包就可以跨平台了,但没有发现 ppt 转图片的 python 工具(ppt 渲染似乎是个复杂的工作,需要 office 类软件专门处理)。因此如果在 win 或 mac 系统,可能要修改或者扩充这个脚本里转格式的部分。
1 个赞
很不错的package,希望支持系统环境变量的程序。
opened 12:07PM - 04 Sep 22 UTC
closed 01:14AM - 06 Sep 22 UTC
I want to use drawio to auto export png file.
my draw.io is installed on system… , `executable-find` will found it.
example:
```
#+IMAGINE: draw.io.exe -x -f png -o test.png test.drawio
```
1 个赞
谢谢,我刚开始有考虑过用系统命令行,但有些接口的细节没想清楚,用命令行确实更灵活,不需要自己写脚本来包装,我这几天扩展一下
我是在看到你这个package后才想到能不能把drawio自动导出图片,然后查了下drawio还真的支持在命令行导出图片。
我现在的用法是自动添加drawio文件和对应的图片两个链接,画好图后,手动导出图片的。
1 个赞
我刚做了一次提交,应该支持系统命令了,解释如下,可能会有些小 bug,欢迎指出🙏🏻
1 个赞
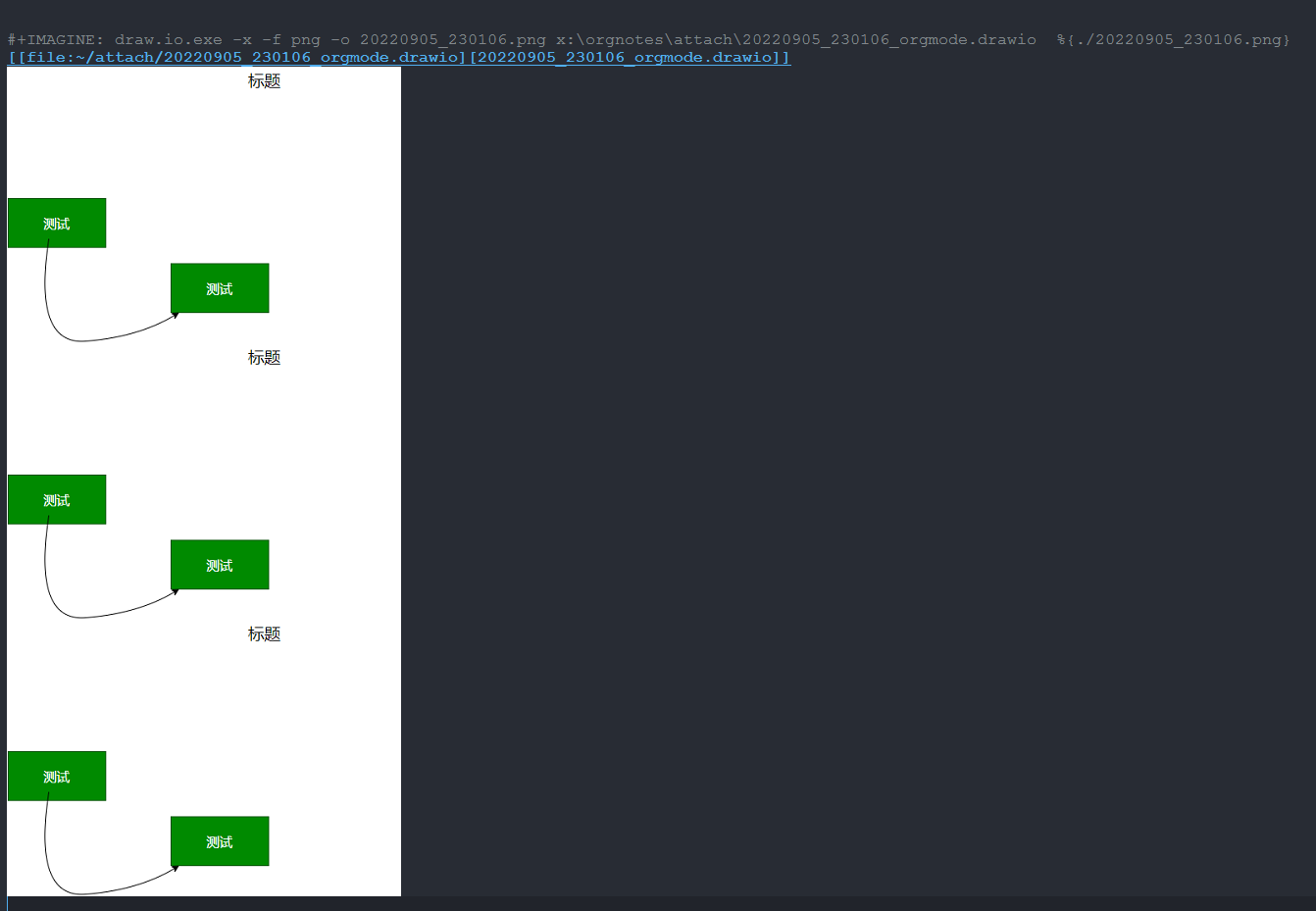
不知道怎样指定导出图片的路径?
上面这个png在当前org文件所在目录下生成了,但是
[[file...png]] 的链接是drawio命令行自动输出,正确的应该是
[[file:20220905_230106.png]]
通过%{./xxx.png} 参数可以显示图片了,不过发现另一个问题,多次执行
org-imagine-view 后会添加多个图片链接。
2 个赞
你这里的写法可以改成以下形式,更精简
#+IMAGINE: draw.io.exe -x -f png -o %{%o.png} %f
%o.png 会替换成 org-imagine 自动生成的文件名(包括时间戳),当然除非确实想自己取名并维护这个图片文件,
那么还可以用以下写法
#+IMAGINE: draw.io.exe -x -f png -o %{./20220905_230104.png} %f
每次执行生成一个新图片链接是设计上的安排,因为有些场景会需要多个图片,比如每天对 drawio 文件执行一次 org-imagine-view,这样可以保存每天的设计的快照。如果不需要的话,就是手动删除一行的成本,或者马上执行一次 undo,因此不对图片链接进行覆盖。
当积累的图片快照多了,可以执行 org-imagine-clear-cache 来删除那些没有被当前项目目录里的 org 文件引用的图片文件,前提是这些文件都在 org-imagine-cache-dir 里,默认是 ./.org-imagine/ 目录,用 %o.png 的话自动就保存在这。(这个命令依赖 projectile 和 grep)
运行 org-imagine-view 时遇到错误:
path-no-ext?: Symbol’s function definition is void: f-no-ext
查了一下,似乎依赖 f.el 这个包。
感谢,都是这几个月自己用的过程中攒的需求,这两天有空一并加上了
确实,我自己还没在 emacs -q 下测试过
又发现个小问题:文件名包含空格时执行的命令不正确。
#+imagine: pdfsnap.py -s 600
[[pdf:1 2.pdf::1]]
[[file:pdftoppm version 22.11.0
Copyright 2005-2022 The Poppler Developers - http://poppler.freedesktop.org
Copyright 1996-2011, 2022 Glyph & Cog, LLC
Usage: pdftoppm [options] [PDF-file [PPM-file-prefix]]
-f <int> : first page to print
-l <int> : last page to print
-o : print only odd pages
-e : print only even pages
-singlefile : write only the first page and do not add digits
-scale-dimension-before-rotation : for rotated pdf, resize dimensions before the rotation
-r <fp> : resolution, in DPI (default is 150)
-rx <fp> : X resolution, in DPI (default is 150)
-ry <fp> : Y resolution, in DPI (default is 150)
-scale-to <int> : scales each page to fit within scale-to*scale-to pixel box
-scale-to-x <int>]]
这里文件 1 2.pdf 是存在的,如果将其重命名为 1.pdf 可以正确输出图片。
这个很不错,有点像include 的多协议支持,做成API应该可以扩充到支持很多的场境吗?比如 网页截取、office 文档、视频截屏什么 的