一个 Emacs 软件包,用于在字符上方渲染帽子,从而可以从缓冲区的任何位置快速索引单词。
用起来是这样的:
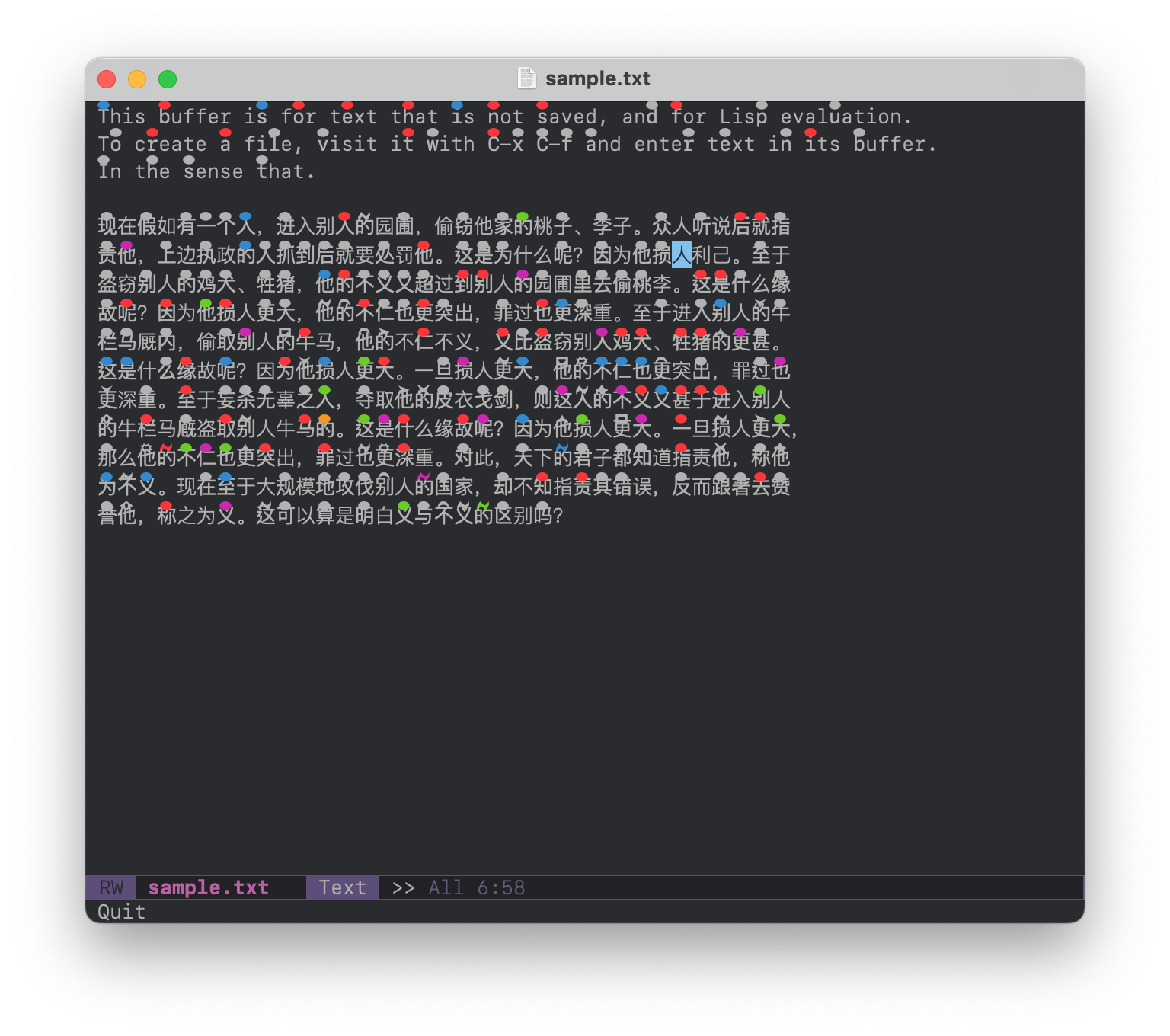
估计对中文无效。
常驻显示的话我也招架不住啊
作者业余爱好可能是打鼓
是为了语音控制,老实讲,我还真想看看怎么做到这件事的…
这个帽子并不是circumflex,是个硬编码的svg
我说的是那个灵感项目
这个有点厉害,用局部发音操作整个单词,语音版的avy
哈哈哈哈哈哈
Hello, I am the author of this package!
I have uploaded a small demo for how I use this with voice control.
I’m curious whether the rendering works with Chinese, I have not tested that. I also wonder to what extend this technique is applicable to non-phonetic languages? Further, the hat placement makes use of the fact that word boundaries are clearly divided by spaces and punctuation, a feature not shared by Chinese. I think it could be made to work for Chinese, but it would probably require a lot more engineering than for phonetic scripts with word dividers.
Best regards
你好,我是这个软件包的作者!
我上传了一个小演示,展示了我如何使用语音控制。
我很好奇这个渲染是否适用于中文,我还没有测试过。我也想知道这种技术在多 大程度上适用于非拼音文字?此外,帽子符号的放置利用了单词边界由空格和标 点符号明确分隔的特点,而中文不具备这一特性。我认为它可以适用于中文,但 可能需要比有单词分隔符的拼音文字更多的工程工作。
此致

For Chinese characters, an additional layer of escape may be needed. Fortunately, Chinese characters can also be expressed through Pinyin with tones, although the result may not be entirely accurate due to the large number of homophones in the Chinese language.
Surprised, how do you find such a Chinese Emacs forum?
支持中文工程量应该不小(我折腾过类似的事),而且我怀疑可能实际并没有中文用户会用这个功能,所以花费大量时间精力实现这个功能也就没多少意义了。母语还非中文的人就更没有必要了
(Splitting up the message into two, as I’m not allowed to mention more than two users in one post)
(将消息分成两部分,因为我不能在一条帖子中提到超过两个用户。)
Perhaps the radical could also be used for indexing? But I must admit that I am not familiar enough with written Chinese to make any statements about what would be a good solution. Do you use pinyin with avy?
You have a large country, there must be many programmers suffering from repetitive stress injury. Those who have gone over to voice control might have some grasp of what method of indexing would fit the Chinese language with respect to voice control.
也许部首也可以用于索引?但我必须承认,我对书面中文不够熟悉,无法对什么 是一个好的解决方案发表意见。你使用拼音和avy吗?
你们国家很大,一定有很多程序员患有重复性压力损伤。那些转向语音控制的人 可能对适合中文的语音控制索引方法有一些了解。
Github can display statistics about what websites people looking at the repository came from. I saw a spike of visitors from emacs-china, so I thought I would take a look.
Github 可以显示查看仓库的人来自哪些网站的统计数据。我看到来自 emacs-china 的访问量激增,所以我想来看看。
I suspect you are right, this system pretty heavily leverages core features of latin writing systems. Also, as I do not regularly interact with Chinese script, I would not get much opportunity to try it out in practical situations. However, if somebody of Chinese origin thinks they could build something useful with this, I would be interested in hearing what their ideas are and what parts of the library would need to be modified to allow their ideas to be realized.
我怀疑你是对的,这个系统很大程度上利用了拉丁书写系统的核心特性。此外, 由于我不经常与中文文字互动,我不会有太多机会在实际情况下尝试它。不过, 如果有中文背景的人认为他们可以用这个构建一些有用的东西,我很乐意听听他 们的想法,以及需要修改库的哪些部分来实现他们的想法。
It seems you are using a simple tokenizer function to place hats while the package itself does not handle voice control commends. there is already a binding in Emacs that calls external NLP functions to tokenizer Chinese text (and any other languages supported by the backend, which can be Apple NL framework or WinRT or icu), if you could modify the code to all use a custom function that accepts a string and returns possible break points as array, specifically emt--do-split-helper, that could make integration with existing code a lot easier
I have pushed code to the develop branch that allows changing the
tokenizer and normalizer. The variable
hatty--tokenize-region-function may be set to a function that will
tokenize a given region of the buffer.
hatty--normalize-character-function can also be set to change when
two characters are deemed equal. For example, by default it
normalizes A to a, so that they are treated as the same character.
If pinyin is used for lookup, this variable should be changed.
See both variables for documentation.
我已将代码推送到 develop 分支,该代码允许更改分词器和规范化器。变量
hatty--tokenize-region-function 可以设置为一个函数,用于对缓冲区中的
给定区域进行分词。hatty--normalize-character-function 也可以设置以更
改两个字符何时被视为相等。例如,默认情况下它将 A 规范化为 a,以便
它们被视为相同的字符。如果使用拼音进行查找,则应更改此变量。
有关文档,请参阅这两个变量。
我看到这个图第一个想到的不是语音驱动,而是给英文文章标记单词。。。。。。
It is a bit too CPU intensive if without native completion… And for whatever reason movement is slow when text mark is active, so it is unlikely that I’ll use it very soon, but it kind of works using emt--do-split-helper, as a proof of concept:
A few things to know for anyone want to get hands on implement the feature:
hatty--tokenize-region-default more or less works like a sequence partitioning algorithm,
while the tokenizer use by EMT ignores punctuations.
即,hatty--tokenize-region-default 返回的结果是连续的,
I think that’s the reason the special hats on punctuation does not work in this demo.
The one time use code I wrote to test these:
(defun test-tokenizer (beg end)
(mapcar (lambda (x) (cons (1+ (car x))
(1+ (cdr x))))
(emt--do-split-helper (buffer-substring beg end))))
(setq hatty--tokenize-region-function #'test-tokenizer)
I think this design works and no additional changes on your side would be needed (except improving the performance). hatty--normalize-character-function actually is not required to be changed for Chinese, but better keep it since it might be useful for other languages, perhaps mixing Simplified/Traditional Chinese would have require this.
因为本身这包不提供语言识別和移动命令,只是一个能按颜色索引 buffer 内容的 API
Nice!
On my machine, the majority of the CPU load comes from generating the SVGs. I could probably optimize it a bit by caching, but for my purposes it is fast enough to not really be noticeable. Have you compiled Emacs with rsvg? I know another user on macOS had some severe slowdowns, and it turned out that he did not compile it with rsvg.
Alternatively, it could be an issue with EMT performance. hatty tokenizes the visible buffer whenever a command has been executed and the user has been idle for 0.2 seconds (to avoid reallocating rapidly while typing). Not sure how fast the EMT roundtrip is.
With respect to hatty--normalize-character-function, it will be if
we’re performing lookup with e.g. pinyin. In this case, we would like
to treat homophones as the same normalized character to avoid
collisions. I suspect there are some bugs lurking in my code if one
tries to do this, but for now I will focus my efforts elsewhere until
someone needs this feature.
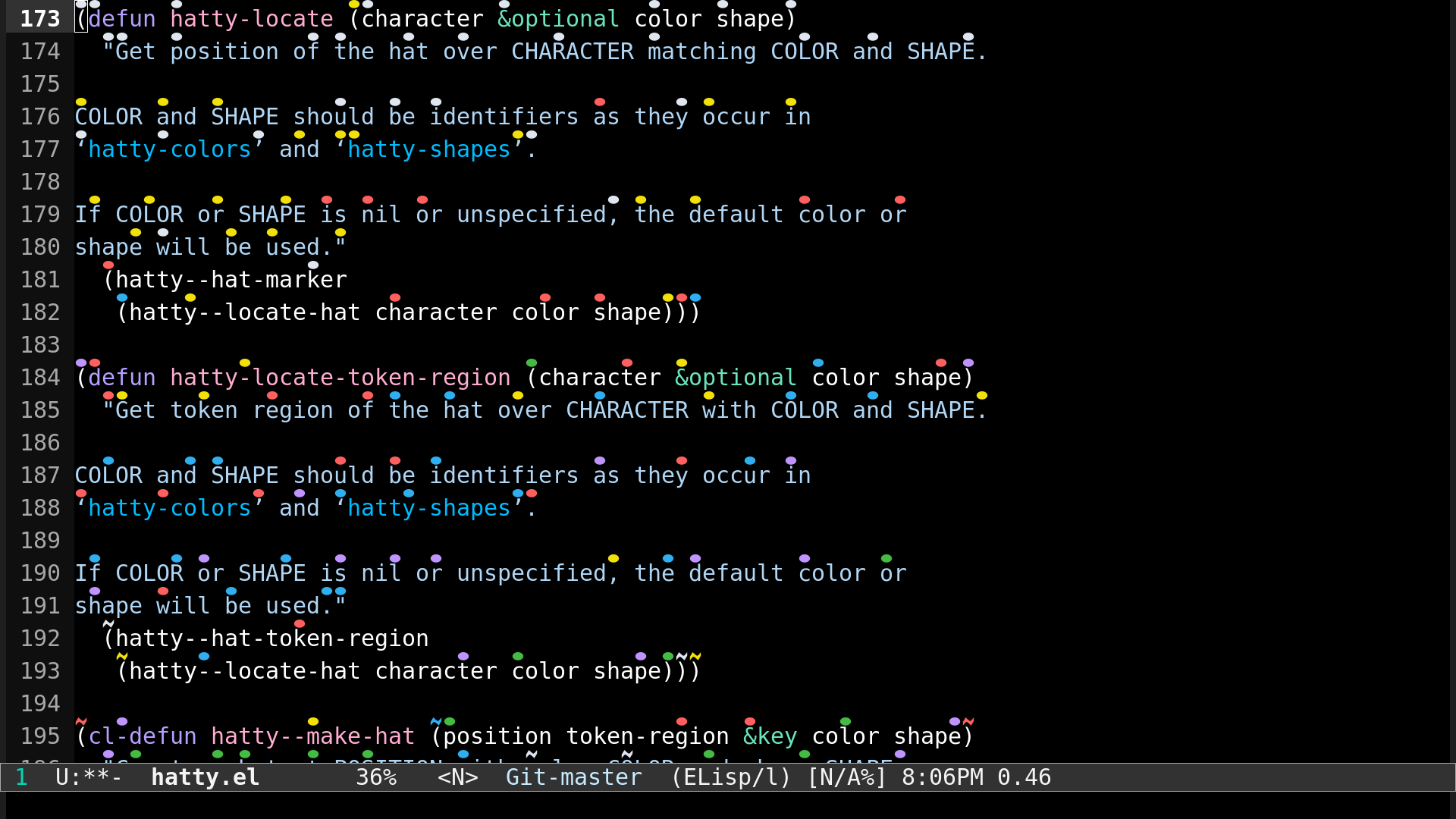
By the way, it does not look like hatty properly manages to add extra line space between your lines, causing overlaps with the glyphs. Contrast with the attached image.
不错!
在我的机器上,大部分CPU负载来自于生成SVG。我可能可以通过缓存来优化一下, 但就我的需求而言,它的速度已经足够快,几乎察觉不到延迟。你有用rsvg编译 Emacs吗?我知道另一个macOS用户遇到了严重的速度问题,结果发现他没有用 rsvg编译。
另外,这也可能是EMT性能的问题。hatty会在用户执行命令并空闲0.2秒后对可 见缓冲区进行分词(以避免在输入时频繁重新分配)。不确定EMT的往返速度有 多快。
关于hatty--normalize-character-function,如果我们使用拼音等进行查找
时,它会起作用。在这种情况下,我们希望将同音字视为相同的规范化字符,以
避免冲突。我怀疑如果尝试这样做,我的代码中可能隐藏着一些bug,但目前我
会把精力放在其他地方,直到有人需要这个功能。
顺便说一下,看起来hatty没有正确管理行间距,导致字形重叠。对比一下附带 的图片。
![]()