个人接触"文学编程"的路径是 Jupyter → ein → 被点拨 (文学编程)
一个微末的实用案例, 管理个人书架
虽然对work with codes很简单, 却实实在在困扰我好久,
因为存放书籍的文件系统与笔记系统是两个完全隔离的体系, 如果在文件系统中的更新全部同步到笔记中, 是海量的人工工作量.
work with codes 的解决方案
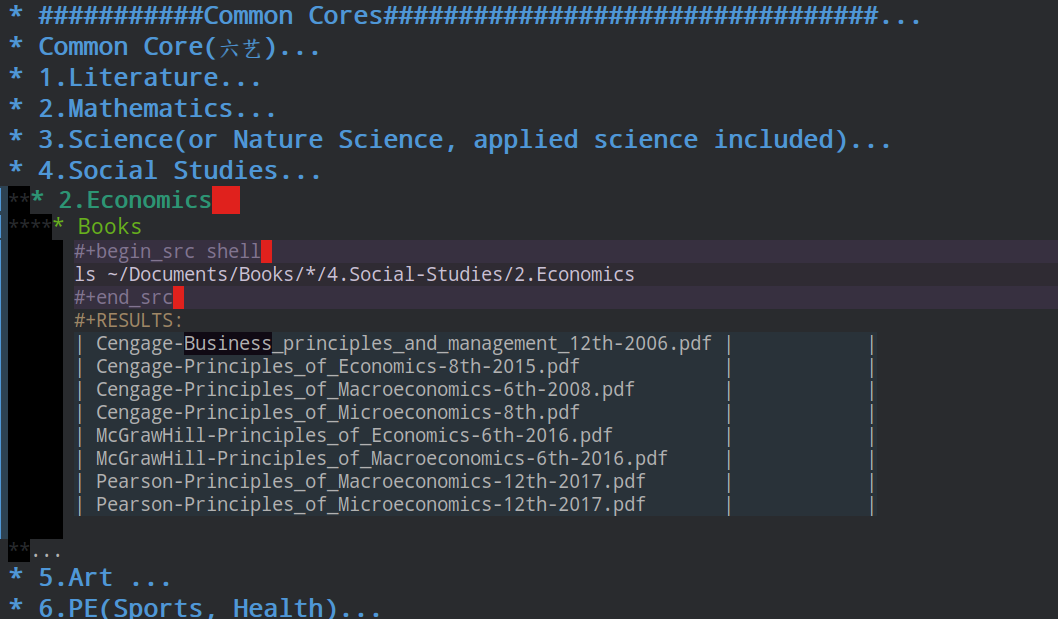
** 2.Economics
*** Books
#+begin_src shell
ls ~/Documents/Books/*/4.Social-Studies/2.Economics
#+end_src
#+RESULTS:
| Cengage-Business_principles_and_management_12th-2006.pdf | |
| Cengage-Principles_of_Economics-8th-2015.pdf | |
| Cengage-Principles_of_Macroeconomics-6th-2008.pdf | |
| Cengage-Principles_of_Microeconomics-8th.pdf | |
| McGrawHill-Principles_of_Economics-6th-2016.pdf | |
| McGrawHill-Principles_of_Macroeconomics-6th-2016.pdf | |
| Pearson-Principles_of_Macroeconomics-12th-2017.pdf | |
| Pearson-Principles_of_Microeconomics-12th-2017.pdf | |
分类按照美国的common core的教学大纲分为六个类别, social studies下有 1) politics 2)economics 3)behaviors and relations 4)history 5)geography 五个子类.
1 个赞
我主要拿来记工作日志,保证记录下来的过程都是可复现的。下面是一段最近处理数据的记录(做了适当删改以免泄漏公司、工作信息):
先把 excel 转 csv
#+BEGIN_SRC shell
cd ~/work/proj1
ls 数据xlxs/*.xlsx | while read line;do to_csv.py -i $line -o ${line%%.xlsx}.csv --header;done
ls 数据xlxs/*.xls | while read line;do to_csv.py -i $line -o ${line%%.xls}.csv --header;done
#+END_SRC
中间有个 excel 是有两个表单的,导致转换出错,但我去看又只有一个表单,后来才知道有一个表单被隐藏了。在表单那里右键然后「取消隐藏表单」就看到了……
大致扫了几眼 excel,发现里面的某些列在不同文件里不太一样,所以写了个脚本 cli.py 来统一转成 json
#+BEGIN_SRC shell
cd ~/work/proj1
mkdir json/
ls 数据xlxs/*.csv | while read line;do venv/bin/python cli.py to-jsons -i $line -o json/$(basename $line | sed -e 's/csv/jsons/g');done
#+END_SRC
保险起见,还是看下各个产生的 json 文件中的 key 的数量是否是一样的
#+BEGIN_SRC shell
cd ~/work/proj1
ls json/*.jsons | while read line;do echo $line $(cat $line | head -n1 | jq "keys[]" | wc -l);done
#+END_SRC
#+RESULTS:
| json/2017_1.jsons | 42 |
| json/2017_2.jsons | 42 |
| json/2017_3.jsons | 42 |
| json/2018_1.jsons | 38 |
| json/2018_2.jsons | 38 |
| json/2018_3.jsons | 38 |
| json/2019_1.jsons | 40 |
| json/2019_2.jsons | 40 |
| json/2019_3.jsons | 40 |
嗯……列数不一样啊……
两两比对的话太麻烦了,我先假设 key 的数量一样的文件中的 key 的集合都是一样的。
逐步试探
#+BEGIN_SRC shell
cd ~/work/proj1
ls json/2017*.jsons | while read line;do head -n1 $line | jq "keys[]" ;done | sort -u | wc -l
#+END_SRC
#+RESULTS:
: 42
OK,至少对 2017 年的数据,假设是成立的。
<2019-06-01 六 15:00> OK,确认这个假设在 2018 年、2019 年的数据上各自都成立。
2018 年的只有 38 个 key,2019 年的 40 个,猜测可能 2018 年的相比 2019 年的是少了几个 key?
#+BEGIN_SRC shell
cd ~/work/proj1
ls json/2018*.jsons json/2019*.jsons | while read line;do head -n1 $line | jq "keys[]" ;done | sort -u | wc -l
#+END_SRC
#+RESULTS:
: 46
我错了…… 46 这明显是有问题的……
看下 2018 和 2019 的数据,有哪些不同的 key
#+BEGIN_SRC shell :results output
cd ~/work/proj1
echo "2018中不存在而2019中存在的key:"
diff --unchanged-group-format="" --changed-group-format="%> " <(head -n1 json/2018_1.jsons | jq "keys[]" | sort -u) \
<(head -n1 json/2019_1.jsons | jq "keys[]" | sort -u) | tee
echo
echo "2019中不存在而2018中存在的key:"
diff --unchanged-group-format="" --changed-group-format="%< " <(head -n1 json/2018_1.jsons | jq "keys[]" | sort -u) \
<(head -n1 json/2019_1.jsons | jq "keys[]" | sort -u) | tee
#+END_SRC
#+RESULTS:
#+begin_example
2018中不存在而2019中存在的key:
"二线转至三线次数"
"二线转至一线次数"
"三线转至二线次数"
"三线转至一线次数"
"一线转至二线次数"
"一线转至三线次数"
2019中不存在而2018中存在的key:
"二线处理时长(分)"
"三线处理时长(分)"
"退单次数"
"一线处理时长(分)"
#+end_example
多四列,少六列,整体上表现为少了两列。
可以看到,我用 source block 记录下了处理过程中几乎所有的操作,同时通过对 source block 求值来执行实际的操作,从而尽量减少离开 org-mode 到别的环境(如终端)中的行为。
1 个赞
感谢分享, 开脑洞. org mode的文学编程模式, 好像能够启发各种奇思妙想.
可以获得 pdf 的链接,在 org mode 中点击直接打开对应的 pdf
1 个赞
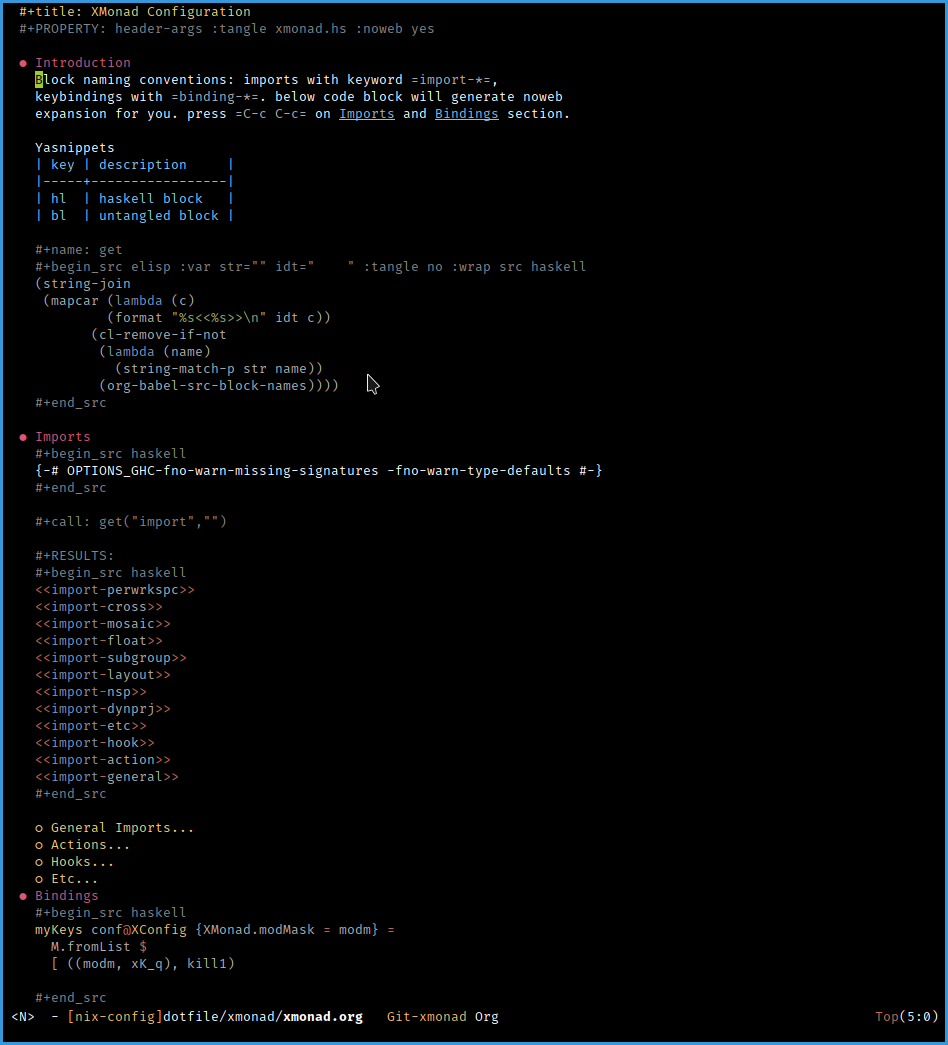
我用nix来管理我的配置文件,以下是xmonad的例子.
由于xmonad的配置模式使得其import和binding还有各种函数非常离散,难以管理和维护.
在org-mode中可以用代码生成代码,把相关的section放在一起.方便管理与更新.
3 个赞
wsug
6
文字编程拿来写点elisp感觉还可以,其它语言稍微复杂一点的就写不下去了,特别是遇到要重构时太难,我觉得这就是在一种语言里写另一种语言,体验当然不会好。
html是超文本标记语言,Markdown是轻量级标记语言,xml是可扩展标记语言,org又是什么标记语言这个感觉并没有明确的定义。
感觉比文学编程更有用的是把org当作html来用,可以在保留org-mode中所有文本编辑的功能的基础上实现一些html前端的功能,我已经在实践了,其实现方式已知的就是 自定义链接 和 在链接中运行elisp代码 。
在org-mode中实现一些前端的功能,包括画图,虽然理论上可以做到,但实际做起来感觉实在太难了