这块发现不少问题,而且很可能就是造成emacs速度慢的一个重要原因(其实也不只是windows版本。linux很多操作也是直接走的系统调用)。
在w32heap.c中,可以看到和内存管理相关的一些函数。
主要有两类,如下
mmap_*
heap_*
比如heap_alloc的实现如下
static void *
heap_alloc (size_t size)
{
void *p = size <= PTRDIFF_MAX ? HeapAlloc (heap, 0, size | !size) : NULL;
if (!p)
errno = ENOMEM;
return p;
}
mmap_free的实现如下(mmap_alloc的代码比较长,不过就是去调的VirtualAlloc)
void
mmap_free (void **var)
{
if (*var)
{
if (VirtualFree (*var, 0, MEM_RELEASE) == 0)
DebPrint (("mmap_free: error %ld\n", GetLastError ()));
*var = NULL;
}
}
在这两类函数加上断点之后可以清楚地看到。如下的情况
这意味着几个结论
1 我们平时直用的kill buffer之类的操作,底层是直接调用了VirtualFree函数,这种操作是非常低效的。都不如CRT的free,因为free本身是有提供空闲内存链表,不用每次都进行系统调用,要快很多。更不用说和mimalloc之类的库比
2 大的内存块是走的VirtualAlloc,小的是走的HeapAlloc(比如在垃圾回收操作里面执行的free)(这里没有仔细看过还不确定,不过也不影响结论),都是走的windows api,效率低
3 在w32heap.c的255行有段注释和官方文档 Building Emacs (GNU Emacs Lisp Reference Manual) 都有提到unexec这种方法以后会被弃用,现在默认使用的方法是不依赖于固定堆地址的。
提高速度的方法:
把现在emacs里面,所有分配,释放内存的操作全部接入到mimalloc里面,包括垃圾回收的清扫阶段也没必要gc自己去管理释放后的内存。
补充:
仔细想了下,gc这块好像还不能直接引入,得等把emacs gc的算法详细研究清楚才行。原因是,如果gc清理的时候是直接扫描整个堆,就必须先分配一个大的堆块。不过对于走mmap_系列函数,比如buffer相关的,接入mimalloc还是有好处
7 个赞
win api要这么差劲其他程序也会卡卡的,内存分配一般都不是性能问题所在
你可以了解下malloc free的实现。
win api主要负责申请内存资源,但是申请之后怎么管理内存她不负责,这些一般是由malloc free这一层来负责,他们的底层也是系统api。但是会用自己的数据结构做内存管理。
现在emacs直接用win api。还没做缓存,肯定会慢。至于其他程序为啥不卡,因为他们不是直接调的win api。都是用的malloc free 
这里写代码测试速度
#include <iostream>
#include <stdio.h>
#include <mimalloc.h>
#include <stdlib.h>
#include <chrono>
#include <windows.h>
int main() {
auto start = std::chrono::high_resolution_clock::now();
// 这里是你想要测量的代码
for (long i = 0; i < 10000000; ++i){
// void*p = mi_malloc(i);
// mi_free(ip);
// void*p = malloc(i);
// free(p);
void*p = VirtualAlloc(NULL, i, MEM_COMMIT, PAGE_READWRITE);
VirtualFree(p, 0, MEM_RELEASE);
}
// 获取结束时间点
auto stop = std::chrono::high_resolution_clock::now();
// 计算花费的时间
auto duration = std::chrono::duration_cast<std::chrono::microseconds>(stop - start);
std::cout << "Time taken by function: "
<< duration.count() << " microseconds" << std::endl;
}
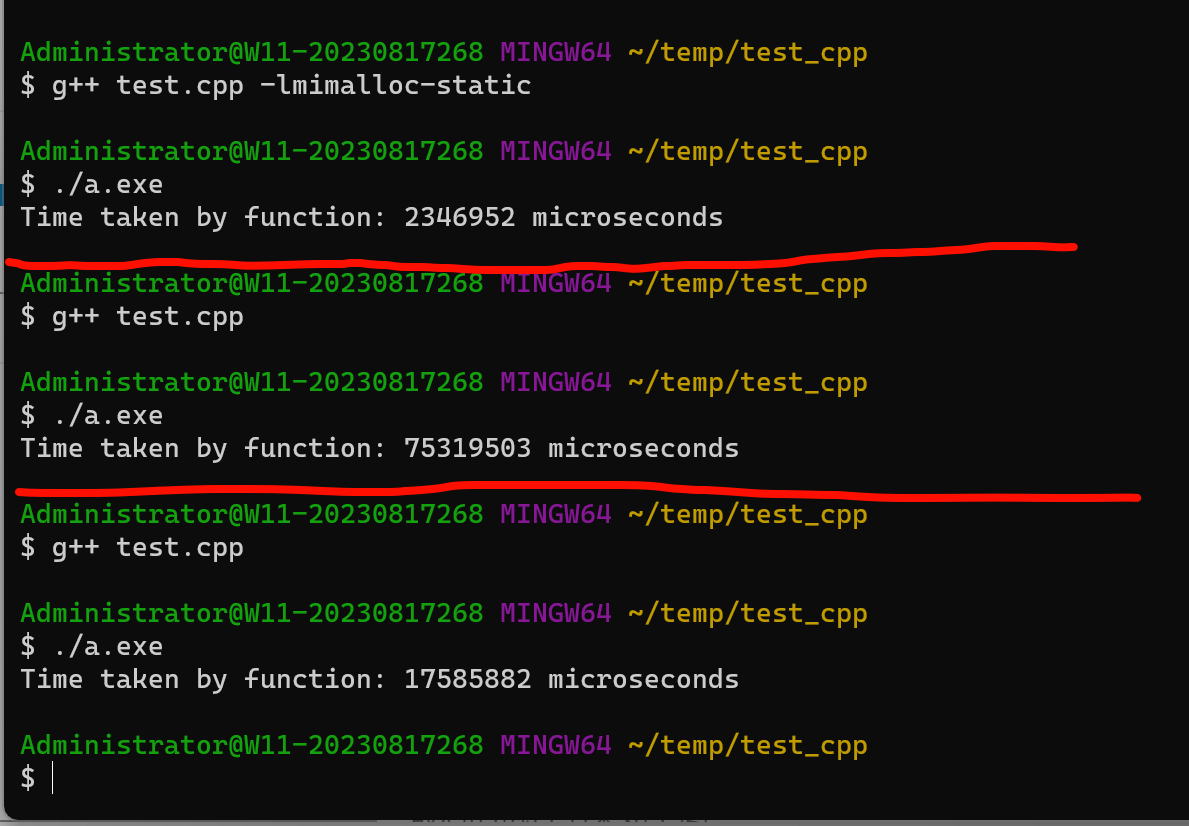
环境是msys2,编译mimalloc版本的时候得链接下-lmimalloc-static
最后的执行结果如下图,第一个是mimalloc,第二个是malloc,最后是win api
mimalloc在这种单线程的情况下,速度比其他两个快一个数量级,多线程情况下就更别说了。
不过他也有缺点,就是内存占用更多,她为什么快,一部分原因就是预分配了内存。不过也不算太多。而且现在都是大内存,不缺这点。
1 个赞
你可以试试替换内存分配看看效果,但emacs也不是内存密集分配释放型程序,替换成mimallc效果不会太明显,另外rust在win上貌似就是直接用的heap api,也没见多少人说一定要用minalloc之类的替换默认的内存分配
我刚才试过了替换buffer那块的函数,测试没看出啥不同
感觉除非把gc也给替换了,否则应该效果不大
瓶颈本身就不在 malloc/free 上面。。。
问题来了,瓶颈在哪?不实际分析测试你知道吗?
也只有上面这样实际测试替换过emacs的某个组件后才敢说这个话。
kill buffer 这种操作应该很少发生,很多人甚至到退出 emacs 为止都不会手动去 kill
我的建议是测 font lock 这样每动一次就会运行好几次的功能的 hotspot 在哪里
我实际调试测试了下,她内部不只是kill buffer才调用mmap_free。
很多操作底层都有涉及buffer操作,但是这个buffer和上层用户操作的buffer不一样。
更准确点可以叫internal_buffer。比如下面这些场景。
1 触发了界面的提示,比如鼠标移动到界面上,触发了提示,底层就会触发新建一个buffer
2 load-file之类的操作,内部也会生成buffer,然后很快就释放掉了
其实这两个和用户普通操作的 buffer 完全就是一回事。
当然这个取决于比如用的 LSP 功能大量创建大量 tooltip,就会有影响,正常一次性也不会 load 很多文件
你咋知道我没试过呢?我相信这个论坛里面很多人都或多或少做过某些方面的尝试,只是不一定会说出来。。。
出现卡顿的时候大概看看,大概率还是 gc 或者其他的, 而不是 malloc free 本身。
windows 平台不确定, Linux 下的话,glibc 的 malloc free 本身性能没有那么好,但绝对不算太差,以前用
jemlloc 和 tcmalloc 替换过 glibc 的内存管理,没有什么改进。
一般场景下使用 emacs 时候,内存分配释放,应该还称不上“频繁”。
1 我这里是分析emacs windows的内存管理,尝试在其中的某个步骤能不能提升性能,达到和linux差不多的水平,你扯其他的干嘛,我都没提卡顿,这和gc没关系
2 你说“瓶颈本身就不在 malloc/free 上面”,意思是你知道在哪,但是看你下面的回复根本没提到性能瓶颈在哪,性能瓶颈和卡顿各是一码事
3 你分析过emacs的源码吗?你所谓的用jemlloc和tcmalloc替换glibc对emacs性能有帮助吗?win下emacs是直接走的系统调用,除非你像我上面直接修改emacs源码,否则emacs都不会使用他们。替换了当然没用
2 个赞
层主加油,说实话愿意在 windows 上用 emacs 的 powerful 的用户太少了,这种优化工作想要深入推进的话,楼主可能只能孤独的前行了。
Unix 系统中,现在的 Emacs 只使用 libc 的 malloc;gmalloc 只在 MS-DOS 下和 unexec 前开启。
咦,那为啥,msys2 mingw环境下默认会开启宏使用mmap(win是用API模拟),而不是统一用malloc
另外“Unix 系统中,现在的 Emacs 只使用 libc 的 malloc” 是指所有动态内存都是走的malloc?gc也没有自己管理链表了?
LdBeth
20
当然不是你想的那种"都是走的malloc"。pdump 设计的前提就是 Emacs 把同类数据连续存在 malloc 的內存块上,也就是 Emacs 自行管理內存,指针在 dump 时转成每种类型对应区块的 offset。
因为曾经的 realloc 不给力,频繁 realloc 的 buffer 数据需要使用 ralloc.c 或 mmap。