介绍
做为一个游戏开发者,日常用到的技术点非常多;做为一个技术爱好者,总是各类知识充满好奇。 但是呢,知识也太多了吧!笔记总结记了一大堆,真用到的时候,记哪儿了,记了啥,完全想不起来啊。
相当长的时间里,会为“如何记录”、“如何记住”、“如何整理”、“如何查找”、“如何使用”知识而烦恼。 其实一直在找答案,调整和改进,下半年针对知识的学习和使用效率方面,对自己做了一个全面的观察。 最近终于形成了一套比较有章法的知识收集、管理和使用流程。给它起个名叫“知识消化系统v1”。
整个知识消化系统中,最核心的是emacs这个文本编辑器。如果没听说过,或不了解的话可以先不管它是什么。可以先不管它,把关注点放在“知识消化系统”本身上面。
笔记 - 打造便捷的知识仓库
在讲到笔记之前,先看看这个问题: 从水果店买一些苹果回家,该怎么带回去?
- 如果只有一个或两个苹果,用手拿就可以了
- 如果有十几个,用用袋子提
- 几百个几千个的话,就要用车运了 这个问题,是为了说明一个前提:同样的问题,如果某个条件的数量级不同,其答案可能不同。
“如何记笔记”这个问题,也是类似的。如果我们记笔记,唯一要求是把一些看到的内容,写在某个地方。 解决的办法是,找一个笔记本/打开一个文件,把内容填进去,合上笔记本/保存文件。 但是笔记不可能只有一条。只有一条笔记时
- 有数十条笔记时,我们开始思考如何分类
- 有数百条笔记时,我们开始思考如何检索
我目前的笔记条目数,是:4535条。目前可以很好地解决“分类”和“搜索”的问题。
笔记的分类
还记得某天,打开Evernote。花了半天时间整理了200条笔记,为它们建立了笔记本,分类放进去。 这样的事情做过几次之后,发现时间花得很不值得。 花半天时间归类200条笔记,笔记列表看起来是舒服了,但是以后真的会逐个笔记本,逐篇笔记翻看吗? 半天时间花完,记住了哪些笔记内容呢? 仔细想想,会发现归类的意义并不大。
另外从"分类"本身来说,其实无法准确定义笔记的类别,有的笔记同时覆盖了"A"和"B"两个类别。 归入"A"就无法再归入"B"了。比"分类"更好的整理方法是"标签"。
但是,明明有比"标签"更好的整理方法啊,就是----“不整理”。笔记的类别,应该由它自己的内容定义。 获取笔记真正定义的方法是:“全文检索”。
一个无法避免的问题是,用什么软件来记笔记? 支持"全文检索"的笔记软件很多,相信大家都在不同的笔记软件中辗转过,这个支持markdown,那个支持代码高亮,还有一个支持在线协作。 如果你去搜索类似“笔记软件”甚至“技术”+“笔记”之类关键词,你很难看到emacs。 它有门槛,但有条件的同学,务必尝试下emacs。它提供给你的是满足你对笔记软件的“一切”需求的可能性。
知识消化系统的笔记,本质上是“文件系统笔记”,即把笔记记录在一个个文本文件里。
疯了吧… (请耐心继续看)
笔记不做分类,我们通过“搜索”来解决“分类”的问题。
笔记的搜索
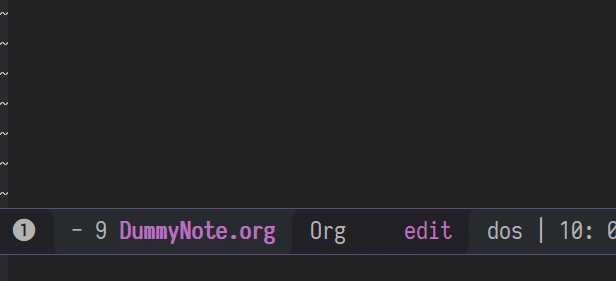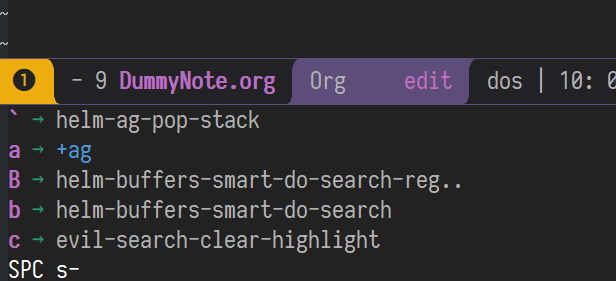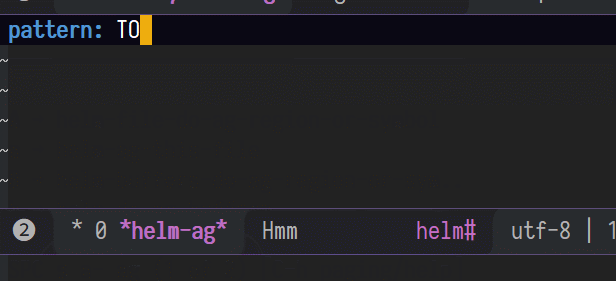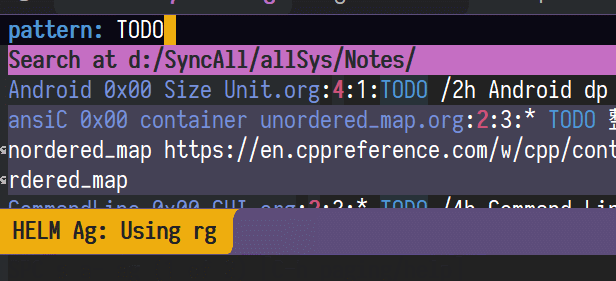
说到笔记中最最重要的功能,必然是搜索了,看图
全文检索

简单的命名和内容规则
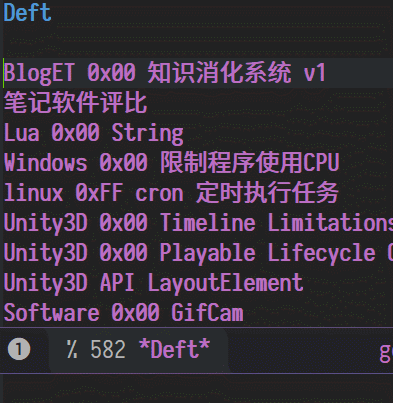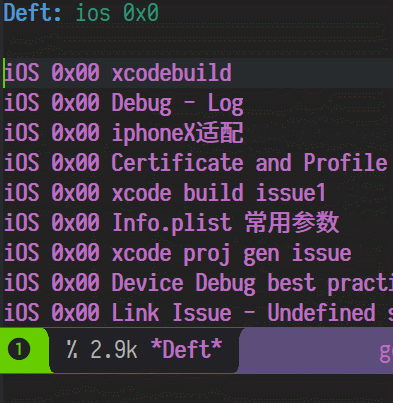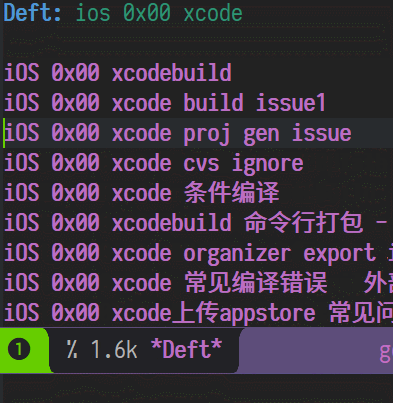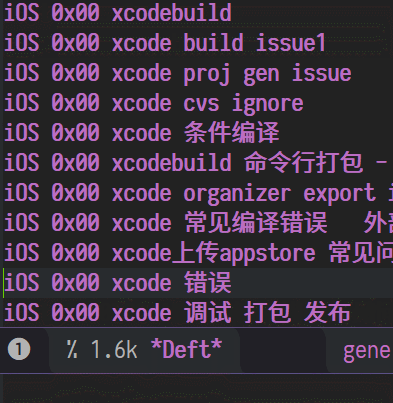 通过文件名来实现传统的"分类"
通过文件名来实现传统的"分类"
Anki - 辅助脑
Anki是一个基于“遗忘曲线”的卡片记忆工具。 如果说,笔记的目的是对知识进行归纳提取连接成知识网, Anki类工具的目的则是辅助记忆知识的最小单位–知识条目 比如: 一个单词、一个术语、一个概念 技术的海洋里,这样的知识条目太多太多。 一个很常见的情况是,花很多时间研究一门技术,过了两个月,就变得模糊了。一年之后再用起来,相当于重新学一遍。 为了不repeat your self,我们需要Anki
在我的知识消化系统中,先把知识录入笔记,将其中不可再分的知识条目标注出来,快速导出给Anki
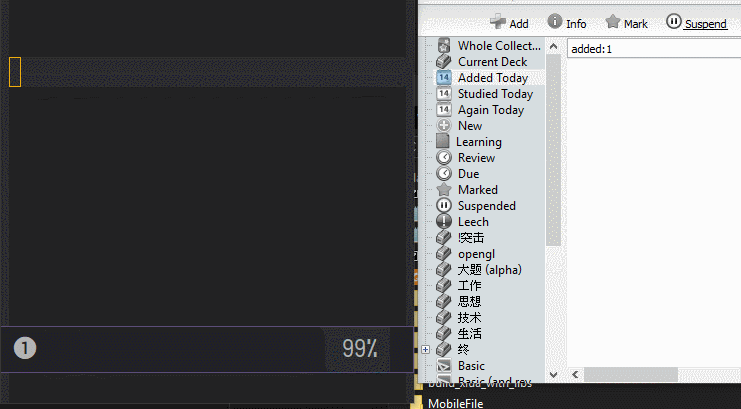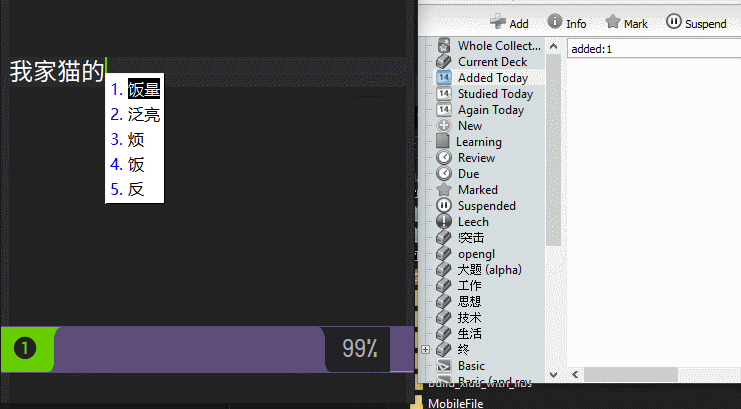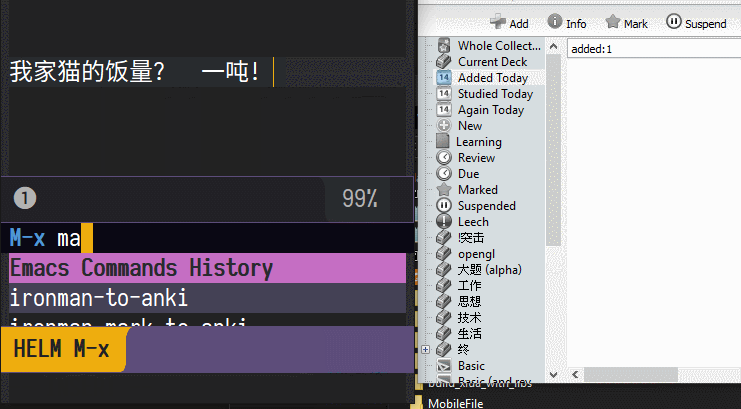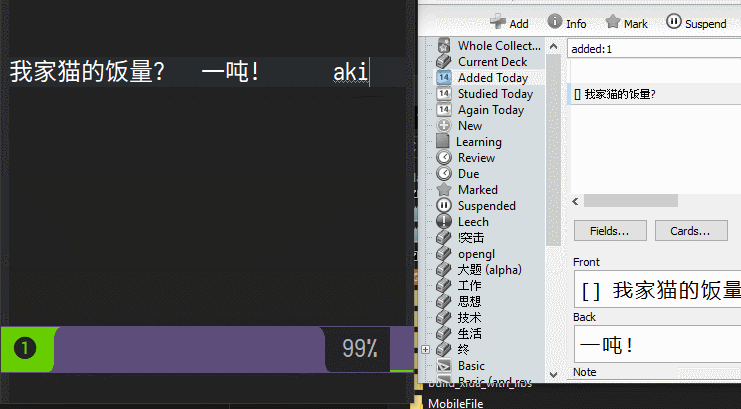
Chrome Page Note
浏览网站时,总会遇到一些庞大繁杂的技术文档,精彩的论坛讨论。 突然,你看到一个页面中的内容,似曾相识。再读一遍很花时间,于是你开始在笔记中搜索关键词来确认这件事。 找到最后,也不确定自己到底有没有记录。
针对这个问题,我们需要“Page Note”,即记录页面笔记。 Chrome Store里,有两个Page Note类插件。其完善程度并不高,而且无法与知识消化系统整合啊。 所以自己做一个:
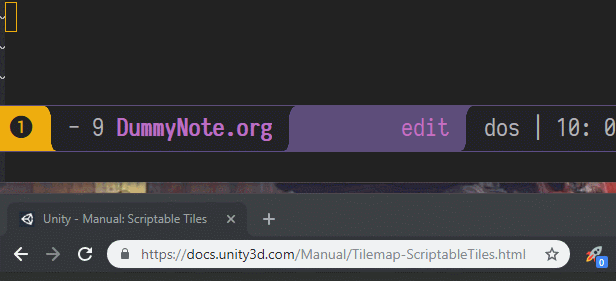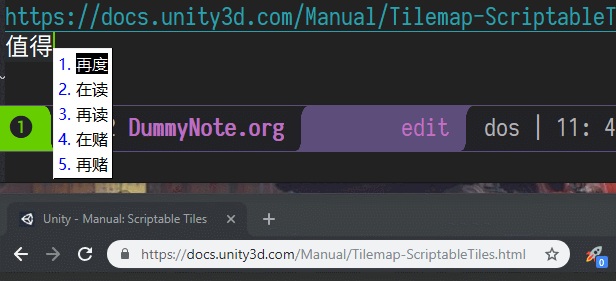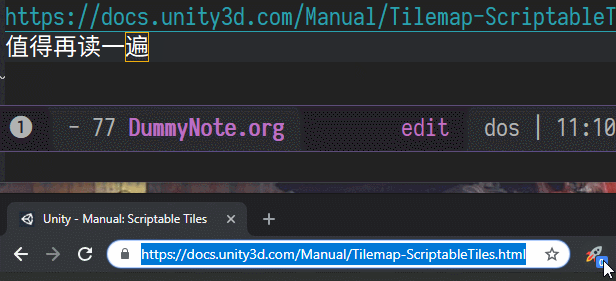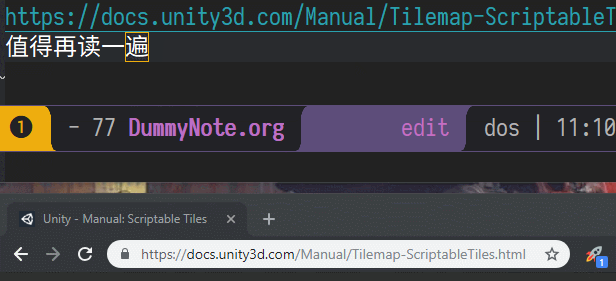
- 整理页面知识时,把url一起存在笔记里。
- 当打开一个页面时,会在笔记中查询url的关键部分,如果找到了,在chrome上标记一个数字,页面被多少笔记引用了
TO-DO - 探索和兴趣
日常会遇到很多想要尝试的技术或深入挖掘的情况。可以工作太紧张,琐事又太多,怎么办呢? 可以用"知识消化系统"管理兴趣类TO-DO。
所谓的兴趣类TO-DO,很难给出优先级和重要性。如果一定要给,也都是“低”吧。工作类的TODO,我不在笔记里管理。 这里也注意一下量级的问题, 我目前的TO-DO数量是396个。
曾经我用taskwarrior管理TO-DO,它有一个review功能,可以进行逐条TO-DO的review,更新状态之类的 但是很快就发现,清理探索性TO-DO的速度远远跟不上它们增加的速度。这种情况下review它们成了一种负担
目前对探索性TO-DO的处理方法是: 有空就在手机上翻翻,发现当下想做,而且时间允许,那么就开始这个TO-DO 没有流程负担,可以更专注于 也可以利用碎片时间,给TO-DO补充参考资料等等
材料
- Emacs (with: SilverSearcher deft-mode)
- Anki (with: Anki-Connect)
- Chrome (with: Chrome Extension)
