yibie
1
这是一次重大更新,增加了许多新特性,同时也改善了老特性。值得单独开一贴发出来。
更新记录
- v0.4 (2024-11-04)
- 注意! 新版本第一次运行时, 一定要执行
M-x org-zettel-ref-migrate 升级哈希表里的数据结构
- 新功能: 为源文件提供可视化管理面板
org-zettel-ref-list (详细见 基本用法 → 管理源文件) :
- 可视化: 提供参考文献管理面板
- 多栏目列表: 以列表的方式展示当前的参考文献, 目前有 Title, Author, Keywords 等关键栏目
- 重命名: 在该面板上可按照 AUTHOR__TITILE==KEYWORDS.org 的格式重命名文件
- 排序: 点击栏目名, 可以按照以字母顺序为列表里的内容排序
- 过滤: 按照条件过滤源文件条目, 可以按照 Author, Title 或 Keywords 来过滤. 当前只能过滤 1 个条件.
- 升级
org-zettel-ref-db.el 哈希表的数据结构
- 升级
org-zettel-ref-clean-multiple-targets
- 修复:
- 恢复不小心删除的自定义配置项
org-zettel-ref-debug
- 提醒
- 由于存储源文件和概览文件之间映射关系的哈希表升级到 2.0, 以下函数废弃:
- org-zettel-ref-check-and-repair-links, org-zettel-ref-maintenance-menu, org-zettel-ref-refresh-index, org-zettel-ref-rescan-overview-files, org-zettel-ref-status.
新功能演示
管理源文件
- 启动面板

M-x org-zettel-ref-list
提醒: 以下命令, 均在面板界面中执行.
- 重命名源文件 (“r”)

M-x org-zettel-ref-list-rename-file
按照 AUTHOR__TITLE==KEYWORDS.org 的固定格式进行重命名.
- 编辑/添加关键词 (“k”)

M-x org-zettel-ref-list-edite-keywords
可独立为源文件添加一个或多个关键词.
- 删除源文件

删除单个文件 (“d”) M-x org-zettel-ref-list-delete-file
 删除多个文件 (“D”)
删除多个文件 (“D”)
在列表里按下 “m” 标记多个文件, 然后执行 M-x org-zettel-ref-list-delete-marked-files
如果标记的文件不对, 按下 “u” 即可清除标记状态, 按下 “U” 可以直接清除所有标记状态
- 使用过滤器
简单过滤 (“/ r”): 使用 Author, Title, Keywords 作为过滤条件, 每次只能应用一个过滤条件 M-x org-zettel-filter-by-regexp
复杂过滤 (“/ m”): 可应用多个 Author, Title, Keyowrds 的过滤条件作为条件
3 个赞
yibie
2
开始一个新的实验和探索,添加多彩标注功能,现在 Bug 还很多:
1 个赞
yibie
3
很大一部分的问题,还是来自 Pandoc 本身转换格式处理得其实并不干净。但作为最大的开源第三方库,似乎并没有特别应该指摘的地方。莫非我要 Fork 一个 Pandoc 版本?
yibie
4
新的笔记样式出来了,改变很大。用 icon 提示不同笔记的类型,使用自动编号,以及可以在每条笔记的下方,手动添加内容。
令我感到最得意的,是实现了摘录图片~
4 个赞
yibie
6
org-zettel-ref-mode 0.5 发布:
- v0.5 (2024-11-12)
- 升级:标记与笔记系统重大升级 (升级之后变化见 #Demo)
- 与 org-mode 自带样式解耦
- 笔记 ID 自动编号
- 自动高亮所标记的内容
- 概览 headline 下的内容不会被清理
- 标记图片,将标记的图片同步到概览笔记
- 必须运行
org-zettel-ref-add-image 命令,将图片添加到概览笔记
- 使用前需要设置
org-zettel-ref-overview-image-directory 配置项
- 概览笔记的样式升级:
- 笔记的标题现在显示笔记的 ID
- 使用 org-mode 的 Headlines 样式
- 笔记的图标前缀,区分笔记类型
- 新增自定义配置项 (自定义标记文本类型与高亮样式,见 #高级功能):
org-zettel-ref-highlight-types 定义/添加标记的类型与高亮的样式org-zettel-ref-overview-image-directory 定义概览笔记的图片保存路径
- 无痛升级,沿用过去的习惯命令
- 注意:在执行 org-zettel-ref-mark-text 时,请不要选择 note 类型,和 image 类型
- 如需要添加快速笔记,请继续使用过去的命令 org-zettel-ref-add-quick-note
- 如此设计的缘由,是需要为快速笔记和图片笔记提供高亮样式
现在看起来是这样的:
3 个赞
yibie
7
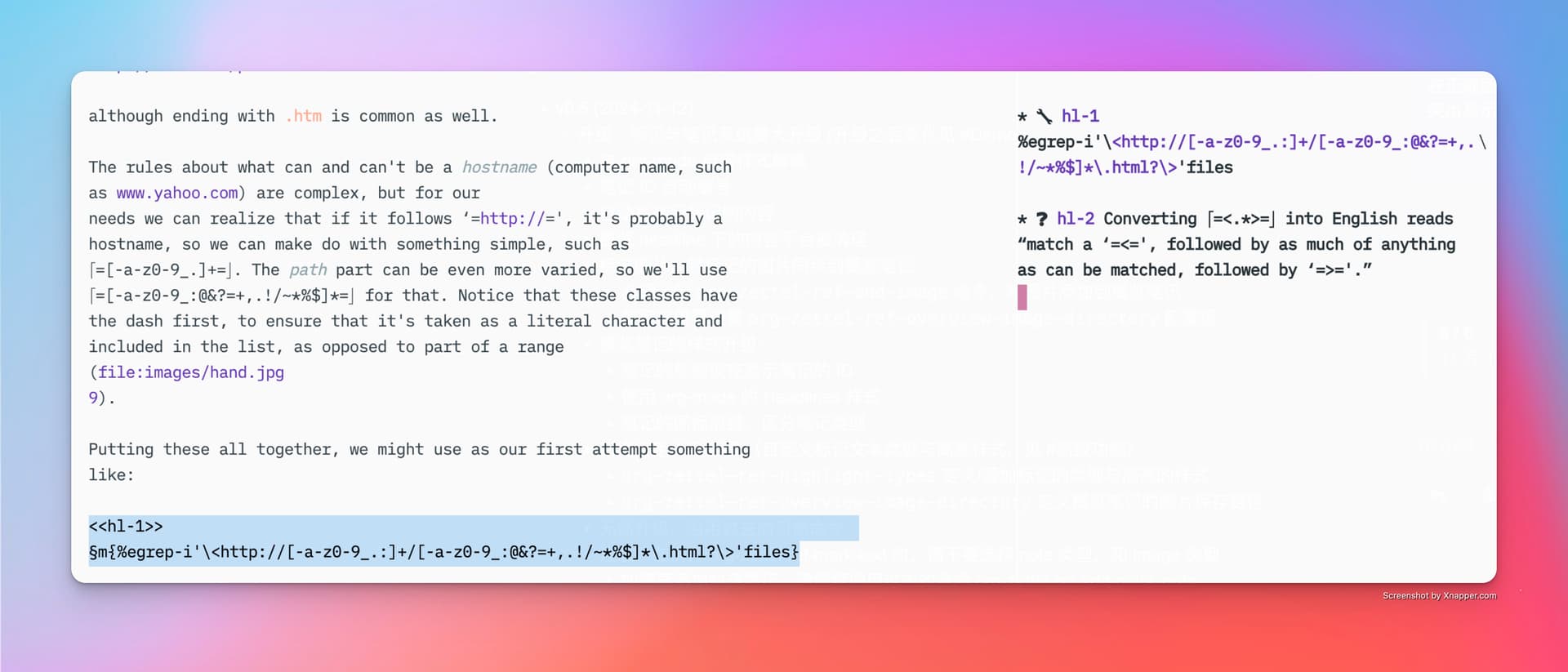
新的标记系统,可以应对复杂的正则表达式,完整捕捉正则表达式作为笔记
yibie
8
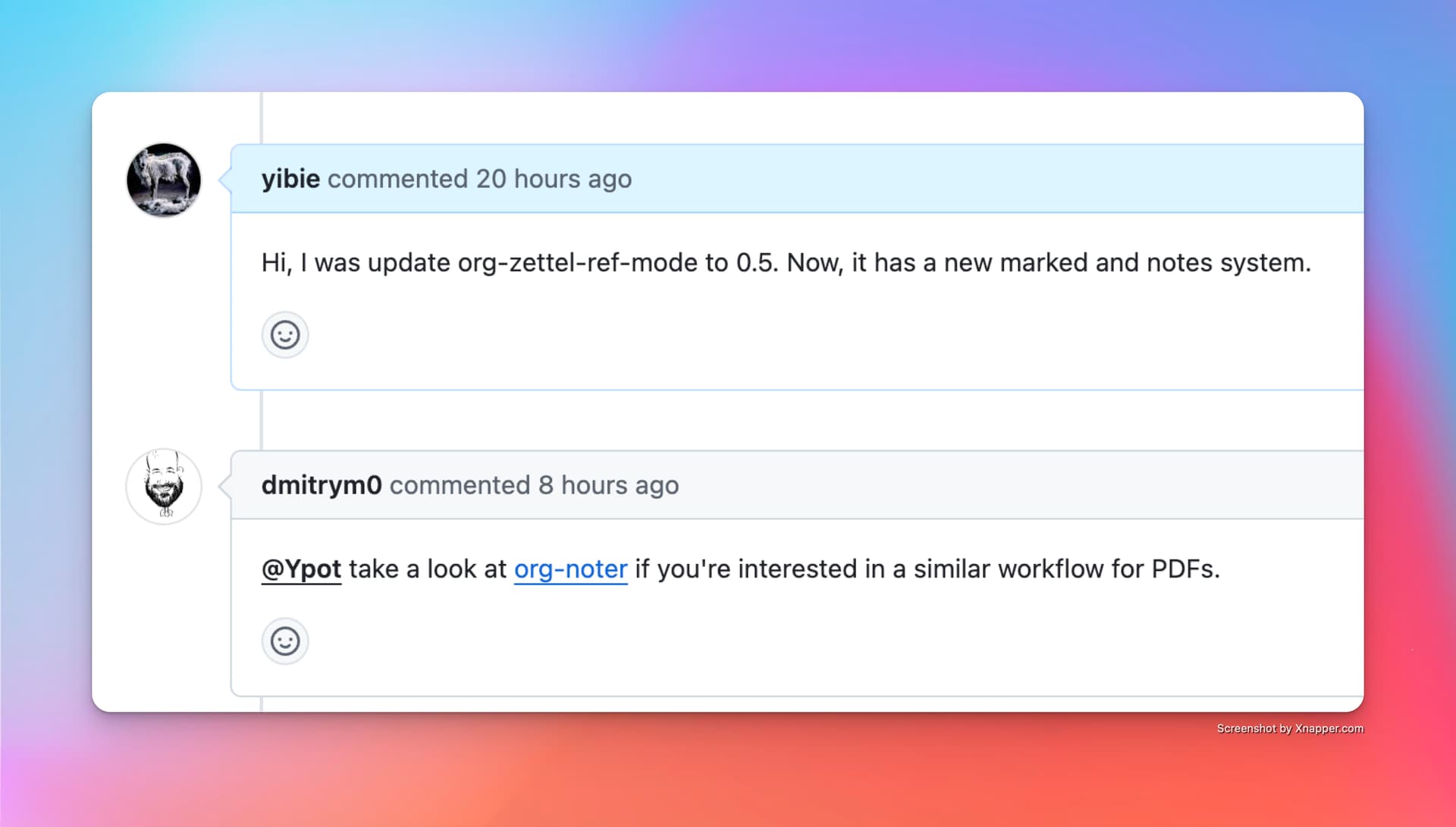
lol,如今的 org-noter 负责人到我的 issue 里宣传 org-noter 了
他还向我提了个 issue
yibie
11
做一个小迭代,恢复 convert-to-org.py 转换 epub 到 org 时,同时导出图片的功能。增补 README 里关于相关设置的说明。
1 个赞
yibie
14
第一点我试一试看看,理论上应该可以的,我学习一下命令行获取网页内容的方法。
关于第二点,你可否展开谈谈,你弄乱这个 Layout 的情形?
1 个赞
命令行扒网页只用 wget 就行了吧。我自己就是 wget 扒下来 html 放在 temp_convert 里面,其实自己来操作的话也只是多一步的事情。
指的 layout 就是这样的 layout,左边是原文,右边是笔记。因为我导入的原文很多都是网页,每个文章都不长,所以会经常切换,然后就会变成
其实自己注意一下别破坏了其实就行,但还是觉得可以有一个命令立即调出图 1 这样的 layout。
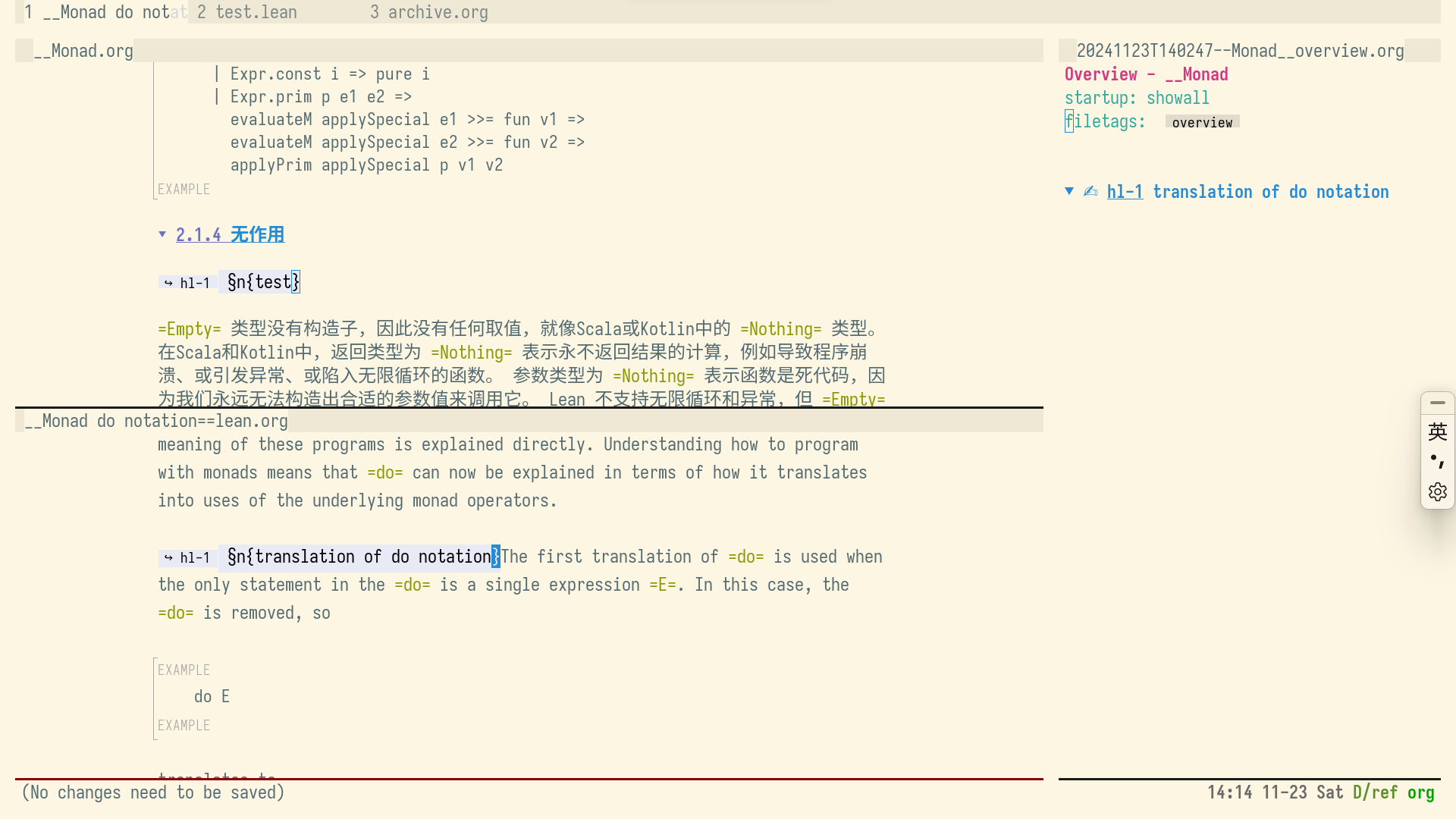
随后我还发现一点,如果先后对文章 1 和文章 2 打开了 org zettel ref mode 之后,再对文章 1 进行操作的时候,文章 1 的笔记会同步到文章 2 的 overview 上面。
上面的文章是 Monad 下面的文章是 Monad do notation;右边的笔记是 Monad 的,但是 Monad do notation 的笔记会同步到 Monad 的 overview 上。
我觉得这和阅读习惯有些关联。如果我主要是看电子书的话,就不会频繁地在很多文章之间切换了。现在的话如果要切换,就需要关掉再打开 org zettel ref mode,有一些不便
1 个赞
yibie
16
理解你的需求,确实和习惯有关。我现在设想的解决方法是:
当原文切换时,overview 部分会自动关闭。这样子,你可以重新唤出对应的 overview。
可能和你设想的自动切换 overview 会有点出入。
主要是,因为不见得所有搜集来的资料有摘要和笔记的价值,所以我觉得应该保留这份让用户挑选形成overview 的自由。让我再沉淀一下,确定一个比较合适的方案。
然后关于批量下载网页,我想思考这个流程怎么才能算方便。实际上我自己使用 MarkDownload 直接将网页保存为 MD,保存到 temp_convert 文件夹。
我想了解,你为什么会喜欢用直接用命令行保存网页呢?这么做有什么独特的优势?
对,目前的机制逻辑是,当文章和 overivew 处于同一个 windows 下时,文章的摘要和笔记会自动同步到同一个 windows 下的 overview 中去。
因为不见得所有搜集来的资料有摘要和笔记的价值,所以我觉得应该保留这份让用户挑选形成 overview 的自由。
我觉得这说的也很有道理
wget 应该没什么优势,我只是知道 wget 而没用 markdownload 而已。我会尝试一下后者