将(a,b,c)替换为\((a,b,c)\),前一个中的逗号,括号都是中文标点,后一个都是英文标点。evil 的替换表达式怎样写才能得到后一个呢?(没有限制,一次替换不行,两次也行。但是直接替换逗号是不行的,因为文中其它的中文逗号并不想换掉)
自己试出来一种解决方案,比较笨,欢迎大家跟帖给出更好的办法
:s/(\(-?[a-z]\),\(-?[a-z]\),\(-?[a-z]\))/\\((\1,\2,\3)\\)/g
另外,在输入替换命令的时候,如果前面输错了想改正,怎样移动光标呢?我按 C-b 总是直接跑到行首了,没有办法向前移动一格吗?
这就是你想解决的问题?还是仅仅是一个例子。比如 (a,b) 应该处理吗?
没用过 Evil,不明白什么意思。
是想解决的问题,(a,b)如果能处理当然更好,我的解决方案只是考虑了三个分量的情形。
就是按下 : 然后输入的正则表达式,有点像 bash 里的 sed。
可以把 a,b,c,...,z 分成两组
(let ((s "a,b,c"))
(string-match (rx (group (0+ (and (in "a-z") ","))) (group (in "a-z")))
s)
(list (match-string 1 s)
(match-string 2 s)))
;; => ("a,b," "c")
替换的时候再特别处理第一个分组,比如
(defun foo (string)
(replace-regexp-in-string
(concat "("
"\\(" "\\(?:[a-zA-Z0-9]+,\\)*" "\\)"
"\\(" "[a-zA-Z0-9]+" "\\)"
")")
(lambda (s)
(concat
"("
(save-match-data
(replace-regexp-in-string "," ", " (match-string 1 s)))
(match-string 2 s)
")"))
string))
(foo "(a)")
;; => "(a)"
(foo "(a,b)")
;; => "(a, b)"
(foo "(a,b,c)")
;; => "(a, b, c)"
1 个赞
大神出手就是不一般,原来根本没注意原来 replace-regexp-in-string 中的 REP 参数还可以是函数,学习了!这相当于链式反应了啊,我记得好像 font-lock 的染色表达式也有类似的用法。
:%s/(\([a-z,]+\))/(\1)/g+
其实这样就可以了, 可以匹配括号内任意多的元素。
vim 的替换功能是 ex 命令, 所以 Emacs 里的 evil 插件也是对应的 ex 命令。
(define-key evil-ex-completion-map (kbd "C-b") 'backward-char)
1 个赞
中文逗号也要替换为英文的
谢谢,解决了我的一个疑问。我对 vim ex 不太熟悉,不清楚为什么 spacemacs 默认会把 C-b 绑定到 move-beginning-of-line 上,得去看看 evil ex 默认的按键绑定是什么了。
至少 Vim 的默认行为就是这样。
严格来说不算函数,rx会返回一个字符串。
写那么长的正则命令不是好主意,并且你这个还限定了只能处理 (a,b,c)。
假设数据是理想的:(a,b,c,...z),不存在嵌套,也不存在只有半边中文括号的情况。可以分两步来进行处理:
-
提取括号中的内容,为了不影响其它文本,因该设置边界:
s/(\([^)]*\))/(\1)/g ^ ^ | | | | 起 止 -
在上边的分组捕获过程当中,再插入一个操作:仅处理分组内容
s/,/,/g
vi 正则恐怕没办法完成这种操作。
1 个赞
今天翻 best of vim tips,想起来这个贴子。
附上 vim 的解决方案:
%s#(#\\((#g | s#,#,#g | s#)#)\\)#g
很简单很优雅。记住这个技巧,很多场合都能用到。
ps: 你们没事不要整天黑 vim 
1 个赞
还能这么玩。
我以为 vi 正则表达式最多也就只能把多个命令写成一行而已:
:%s/aaa/bbb/e | %s/111/222/e
UPDATE
再次确认了一下,这个骚操作并不能达到楼主的要求,也不符合我在 11楼 提出的设想:
%s#(#\\((#g | s#,#,#g | s#)#)\\)#g
^^^^^^^^
只作用于 `(...)` 中的内容
所以跟 :%s/(\([^)]*\))/(\1)/ge | %s/,/,/ge 作用是一样的,会把 (...) 之外的内容也替换掉:
,(a,b,c), ====> ,(a,b,c),
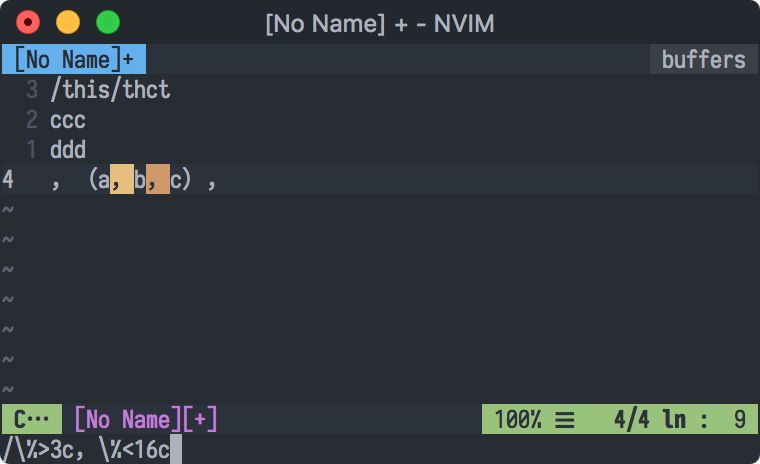
@twlz0ne 在上一个基础上修改了一下。
假设原文本为这个:
,(a,b,c),
%s#\%>3c,\%<16c#,#g | s#(#\\((#g | s#)#)\\)#g
相比分组什么的,还是要简单好理解很多。
看了会 vim 的正则,还得多学习。补充一个零宽和分组的:
%s~(\zs\(\w\+\),\(\w\+\),\(\w\+\)\ze)~\1,\2,\3~g
尽管简化不少,依然很丑陋。主要是需要各种 escape。
坑多,还深。