spacemacs,company m匹配[co[m]pany]-mode,what the hell???
doom-emacs,company m匹配[company]-[m]ode,正常些。但是
iv優先列出arch[iv]-*而把前綴匹配的ivy-*放在後面,???
我以前根據fzf和別的什麼地方抄了一個加到 rofi -sort -matching fuzzy。
後來從https://github.com/llvm-mirror/clang-tools-extra/blob/master/clangd/FuzzyMatch.h 抄+改(大幅簡化並(自認爲:proud:)質量不差)了一份到cquery
這個問題用subsequence filtering + sequence alignment O(n^2) dynamic programming就好了,不要到處堆heuristics,弄出我都看不出主循環在什麼地方的代碼。(fzf也有這個毛病,heuristics散亂堆在各個地方)
但我寫不來elisp T_T
没毛病啊。像我这种经常把 parinfer-toggle-mode 打成 toglg par 的情况下,这是为了保证就算有 typo 也能匹配嘛。
讲道理 ivy不建议用fuzzy search
abo-abo自己不用 所以各方面support都比不过regex-plus backend 速度也慢很多
我用M-x 有些时候带有探索性质,想知道有哪些命令。如果fuzzy matching智能,知道consecutive matching优先级高(以及我列的其他一些heuristics),fuzzy matching并不妨碍的。
1 个赞
今天研究了ivy代碼才發現flx其實還行,我沒有安裝flx所以ivy.el中(defvar ivy--flx-featurep (require 'flx nil 'noerror))爲nil沒有啓用。
https://github.com/abo-abo/swiper/pull/1518 C-x C-f的問題不知何故
二維動態規劃用
(cl-macrolet ((c0 (i j) `(aref (aref miss ,i) ,j))
(c1 (i j) `(aref (aref match ,i) ,j)))
還是挺開心的。以後得研究setf gv.el這些到底是怎麼做出來的
MaskRay:
setf gv.el這些到底是怎麼做出來的
在 common lisp 里 setf 其实是靠 OOP 做的,对于不同数据类型/结构都要定义一个对应的方法才能用。
setf被Stefan Monnier改成gv.el了,原來可能是OOP,現在是getter/setter old-style lens (嗯,Haskell常用的Control.Lens Twan van Laarhoven lens嚴格強於這個)
看了下,是利用 Emacs 加入 lexical-binding 以后可以用 Closure 隐式传指针实現的。
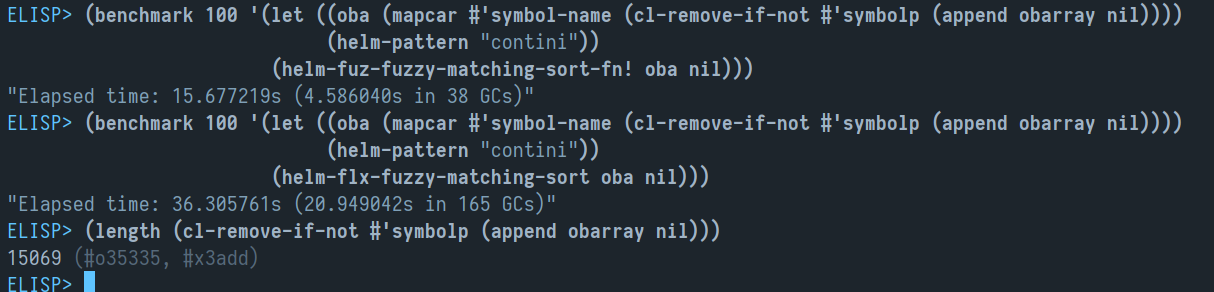
flx好像是O(n),它有预处理的cache。
O(n*m)的算法估计有点呛,elisp太慢了。
它没啥启发式的东西,就靠一个评分函数。
现有的模糊最多能容忍一下transpose charcater
transpose word就跪。。
所以要先要确定一下要实现什么样的模糊搜索。。
我感觉flx够用了。
(defun flx-find-best-match (str-info
heatmap
greater-than
query
query-length
q-index
match-cache)
"Recursively compute the best match for a string, passed as STR-INFO and
HEATMAP, according to QUERY.
This function uses MATCH-CACHE to memoize its return values.
For other parameters, see `flx-score'"
遞歸計算的,沒仔細看用了什麼算法。
這類sequence alignment算法都要保證pattern是text subsequence的,transpose不能容忍
cireu
2019 年7 月 19 日 07:24
12
速度的问题就用dynamic module来解决
用Rust包装主题所提到的subseq alignment 算法成submodule。给Emacs调用,搜索速度刷刷的。
目前只写了helm的,和helm-flx简单做个对比。
5 个赞
用rust肯定速度杠杆的……
只是不太好自动编译安装啊,如果有预编译的binary就好了。另外ivy-fuz.el居然是空的
cireu
2019 年7 月 19 日 07:36
14
WIP
seagle0128:
如果有预编译的binary就好了
预编译binary要怎么托管?另外有自动发布多平台交叉编译binary的托管工具么?
cireu:
WIP
高产哪
很多项目是release到github上的,自动发布的托管工具我也不了解啊,我都是通过CI干的
cireu
2019 年7 月 19 日 13:47
17
committed 01:45PM - 19 Jul 19 UTC
Help fuz integrate with ivy.
已经加入了对ivy的支持,可以参照README.org进行设置,欢迎试用。
用fuz排序我counsel-ffdata读出来的6w条历史记录。在ivy-fuz-sort-limit设置为5000(和flx一样)的情况,比flx流畅到不知哪里去了
2 个赞
et2010
2019 年7 月 19 日 22:53
18
不太了解dynamic module,能不能搞成自动下载预编译binary?
希望能把这个包提交到 melpa,让更多人能用到
你这个库,能否每种系统直接二进制包安装一下?
然后能做成库吗?
比如:
(fuz-match-p “input1 input2 input3” candidate) 返回 t 或者 nil ?
1 个赞
cireu
2019 年7 月 20 日 03:12
20
目前暴露了4个API,两个算法的各两个,一个计算分值,一个返回fuzzy match找到的字符位置,如果没有匹配,都会返回nil
// Output Functions
/// Return the PATTERN fuzzy score about SOURCE, using skim's fuzzy algorithm.
///
/// Sign: (-> Str Str (Option Long))
///
/// Return nil if no match happened.
///
/// (fn PATTERN SOURCE)
#[defun]
fn calc_score_skim(_env: &Env, pattern: String, source: String)
-> Result<Option<i64>> {
Ok(calc_fuzz_score_skim(&pattern, &source))
}
/// Return the PATTERN fuzzy score abount SOURCE, using clangd's fuzzy algorithm.
///
/// Sign: (-> Str Str (Option Long))
///
/// See `fuz-calc-score-skim' for more information
///
;;; fuz.el --- Fast and precise fuzzy scoring/matching utils -*- lexical-binding: t -*-
;; Copyright (C) 2019 Zhu Zihao
;; Author: Zhu Zihao <[email protected] >
;; URL: https://github.com/cireu/fuz.el
;; Version: 1.4.0
;; Package-Requires: ((emacs "25.1"))
;; Keywords: lisp
;; This file is NOT part of GNU Emacs.
;; This file is free software; you can redistribute it and/or modify
;; it under the terms of the GNU General Public License as published by
;; the Free Software Foundation; either version 3, or (at your option)
;; any later version.
;; This program is distributed in the hope that it will be useful,
;; but WITHOUT ANY WARRANTY; without even the implied warranty of
;; MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
show original