原来如此,这样就能解释function与普通值之间的区别了,但是为什么这样做呢?
为了让 宏 编写起来更容易,
1 个赞
从以前的文献来看, scheme 选择 lisp-1 是为了让 lisp 更简单,更加适用于递归, 但 lisp-1 相应的也增加了编写宏的难度, common lisp 选择 lisp-2, 虽然让语法稍显丑陋,但降低了宏编写的难度, 只是抉择的侧重,没有对错之分
2 个赞
(define fun-123 () (print 1))
(setq x "123")
(funcall (intern (concat "fun-" x)))
;; => 1
Scheme 要做这个一定要 eval,但 funcall 效率 是 eval 的几十倍。
这是黑科技, 除非是必须这么搞,否则不要搞这种东西, 容易自残
Real Man doesn’t afraid use of BLACK TECH(e.g. goto).
After all, Lisp is the biggest BLACK TECH.
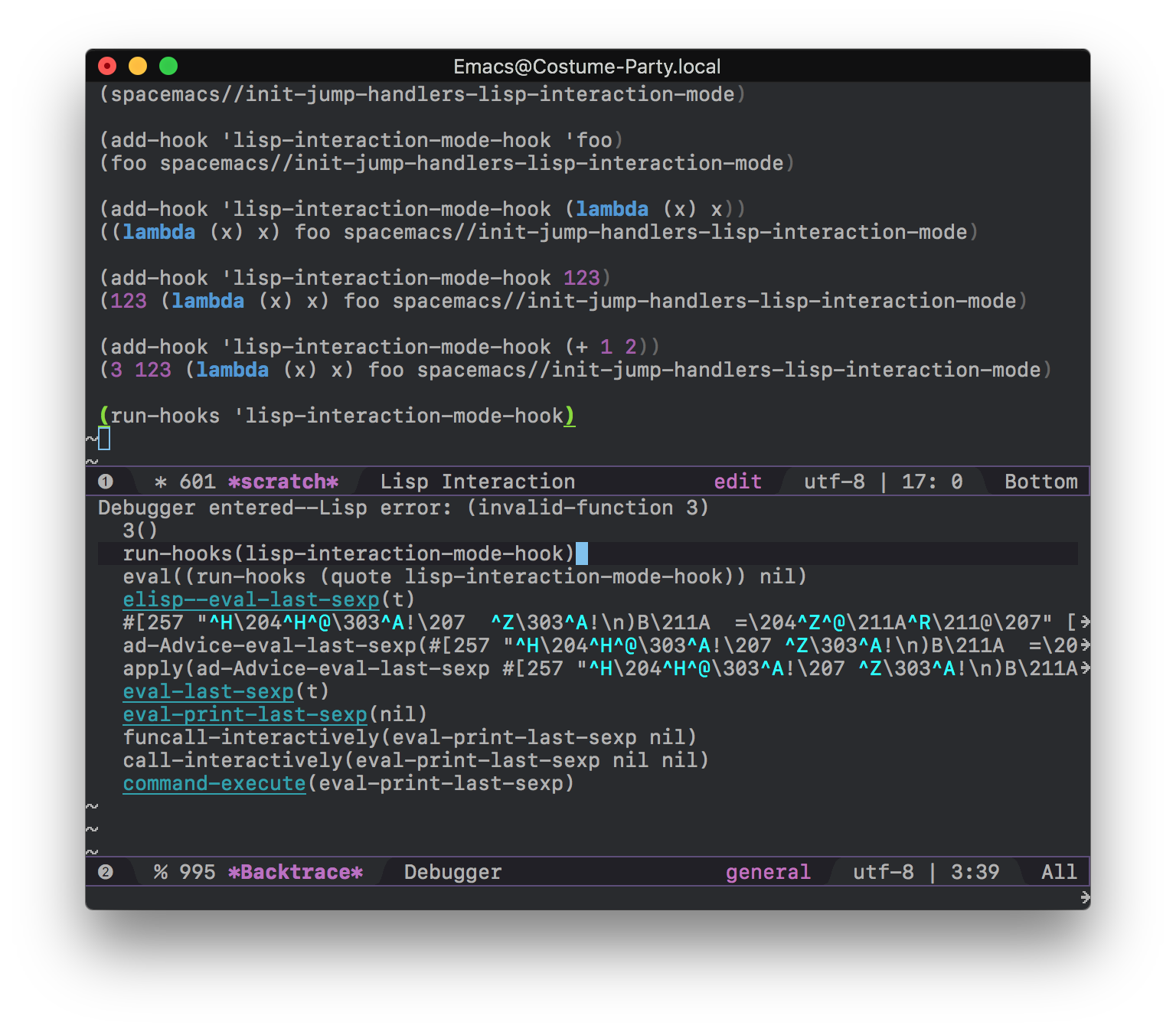
这个本来就不是函数名: ((lambda () (message “ffff”)))
当eval 上面表达式的时候, 从左到右执行上面表达式的各个子表达式,首先遇到的是lambda表达式,这个表达式执行的结果是它本身对应的函数,执行完后,最后执行总体表达式,就是调用这个函数
而且 add-hook 也不建议使用 lambda
原来如此 
我感觉不能这么理解, 它有名字,但名字就是这个lambda代表的函数对象。 就是 “我=我”
1 个赞
Syntax Expansion
((lambda (x) (+ x 1) 2)
;; =>
(funcall (function (lambda (x) (+ x 1)) 2) ;; => 3
(+ 1 2)
;; =>
(funcall (function +) 1 2) ;; => 3
((intern "+") 1 2)
;; =>
(funcall (function (intern "+")) 1 2) ;; => Err: (INTERN "+") is not a function name我感觉,粗略的理解,这样倒是可以,但如果仔细从 lisp 的调用规则来分析, 你这么比较,就不太合理了。
Scheme 當然不是这樣,Common Lisp 大致是这樣的。Emacs Lisp 和 Common Lisp 有区別。
This implementation of eval varies depends on different dialog of Lisp
我觉得就这块内容, 应该仔细学习研究一下 lisp 的 eval 规则,就好比学算数首先学习运算法则一样, 一旦理解了 eval 规则,以及极少量的人为规定,你就很容易的理解 lisp,不要想当然的用别的语言的规则来理解 lisp
我的意思是,你没有从 lisp 的 eval 规则推导,只是做一种类比而已。。。。
我看大家的讨论,感觉大家或多或少的都对 lisp eval 的基本规则有一些曲解,也许这是你们从其它编程语言里面带过来的,我还是建议大家复习 eval 的基本规则,理解lisp从基本规则推导。。。。。
哪裡有得看?
另外一个东西大家要注意的是: lisp 里面描述的许多东西,都是表面上看不到的,而是内存里面的东西,比如: lisp 说函数, 一般是指 函数对象,而我们经常讲的函数,是函数定义,是lisp文本, 函数的定义 eval 之后才是函数对象呢。
从 common lisp 的教材里面看是最简单的, 多翻基本书,比较的看最好。