没有全面测试,仅考虑到两点发现:
-
rg 支持 GBK 等中文编码,grep/ag/ack 不支持
$ rg --encoding gb18030 宝玉.妙玉 Red_Mansions_Anasoft_A_CHS_GBK_txt.txt 2261: 宝玉和妙玉陪笑道 # 能搜索 Raw Bytes [1] 的也不算支持 $ LC_ALL=C grep -P '\xB1\xA6\xD3\xF1..\xC3\xEE\xD3\xF1' Red_Mansions_Anasoft_A_CHS_GBK_txt.txt | iconv -f GB18030 宝玉和妙玉陪笑道 -
对于 UTF-8,rg 和 grep 的正则表达式中
.支持中文字符,ag/ack 不支持$ grep 宝玉.妙玉 Red_Mansions_Anasoft_A_CHS_UTF8_txt.txt 宝玉和妙玉陪笑道 $ rg 宝玉.妙玉 Red_Mansions_Anasoft_A_CHS_UTF8_txt.txt 2261: 宝玉和妙玉陪笑道 $ ag 宝玉.妙玉 Red_Mansions_Anasoft_A_CHS_UTF8_txt.txt $ ack 宝玉.妙玉 Red_Mansions_Anasoft_A_CHS_UTF8_txt.txt # ag/ack 需要三个 . (在 UTF-8 中汉字一般占 3 Bytes) $ ag 宝玉...妙玉 Red_Mansions_Anasoft_A_CHS_UTF8_txt.txt 2261: 宝玉和妙玉陪笑道 $ ack 宝玉...妙玉 Red_Mansions_Anasoft_A_CHS_UTF8_txt.txt 宝玉和妙玉陪笑道
Links
- rg (ripgrep) GitHub - BurntSushi/ripgrep: ripgrep recursively searches directories for a regex pattern while respecting your gitignore
- GNU Grep Grep - GNU Project - Free Software Foundation
- ag (the_silver_searcher) GitHub - ggreer/the_silver_searcher: A code-searching tool similar to ack, but faster.
- ack https://beyondgrep.com/
- 红楼梦文本 http://www.speedy7.com/cn/stguru/gb2312/redmansions.htm (标识成 GBK 的,实际是 GB18030)
[1] 在 Emacs 中用 C-u C-x = (what-cursor-position) 查询字符的编号,或用:
(defun unicode->other-encoding (char coding)
(mapconcat
(lambda (x) (format "%02X" x))
(encode-coding-char char coding)
" "))
=> unicode->other-encoding
(unicode->other-encoding ?宝 'gb18030)
=> "B1 A6"
Emacs Lisp 的字符对应的数字就是其 Unicode Codepoint。
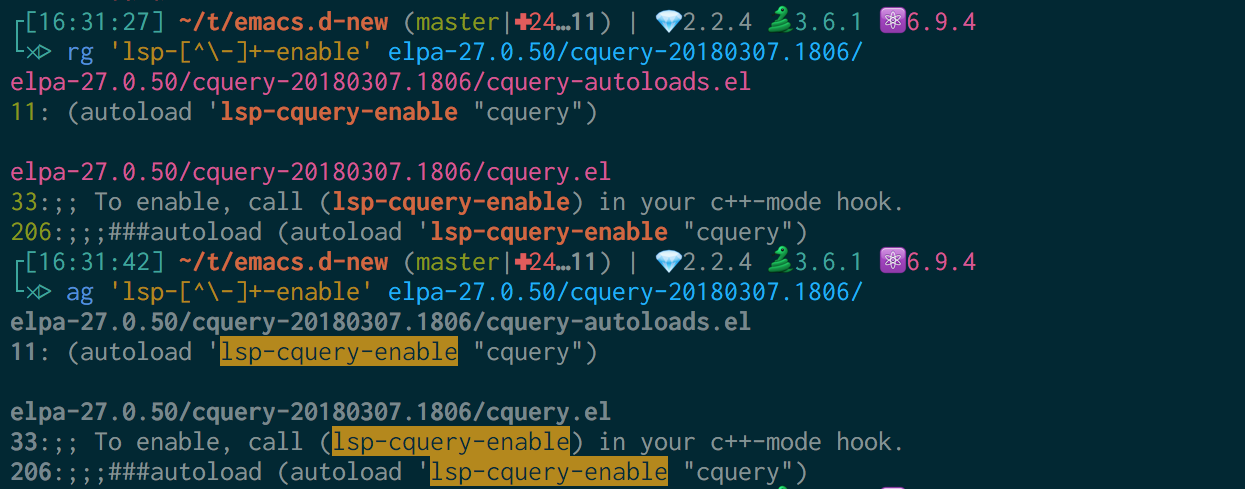
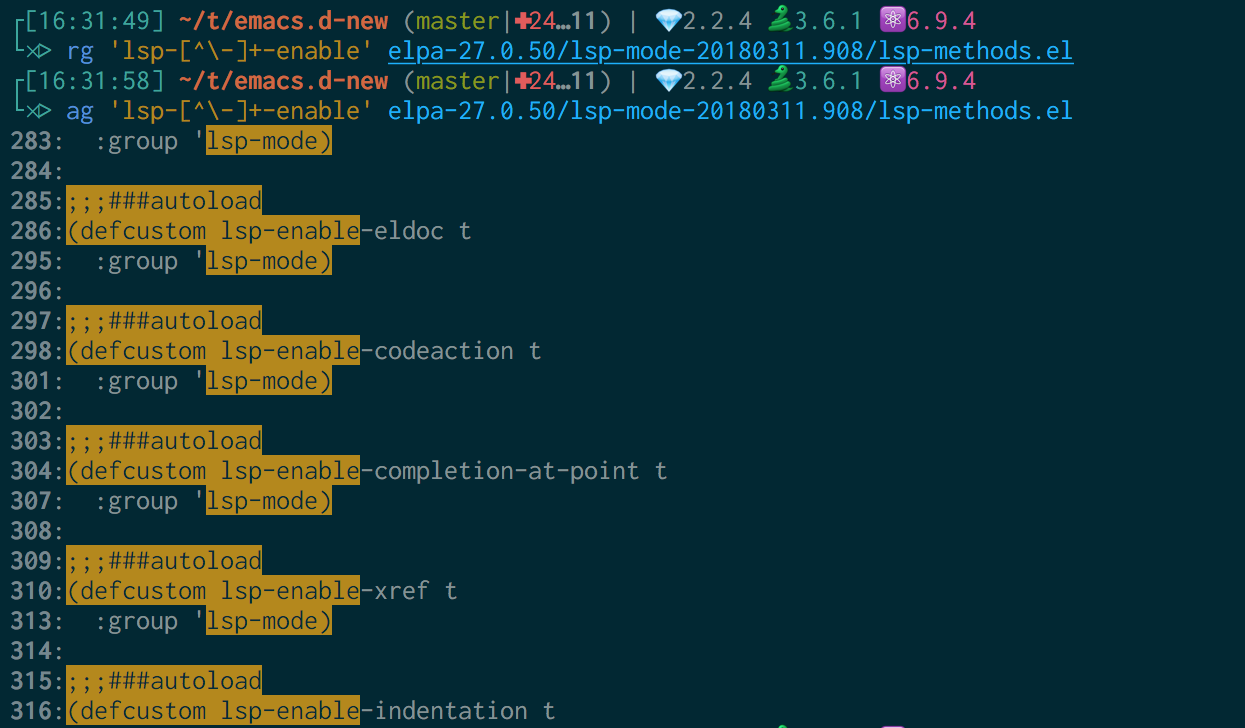
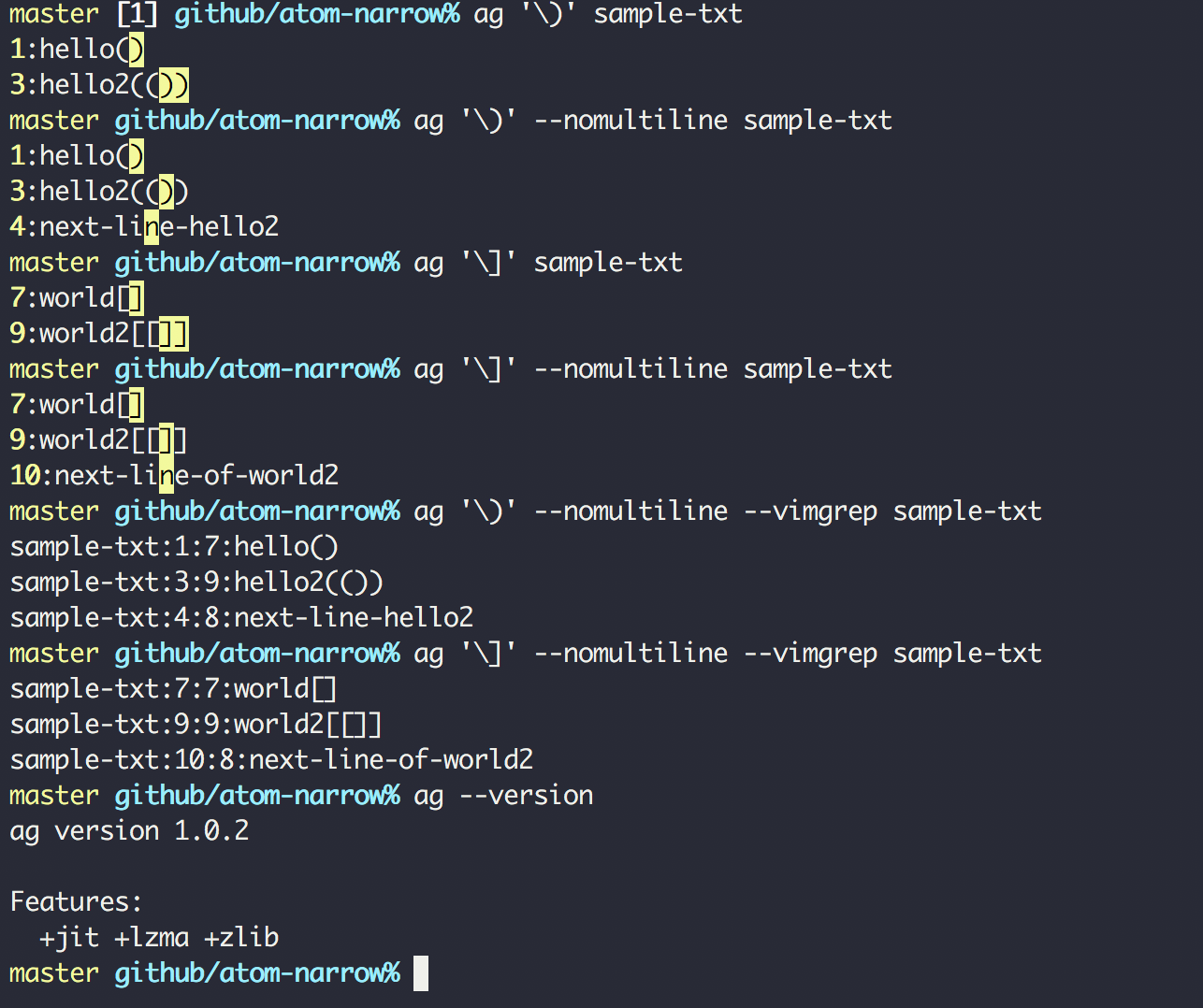

 求解
求解