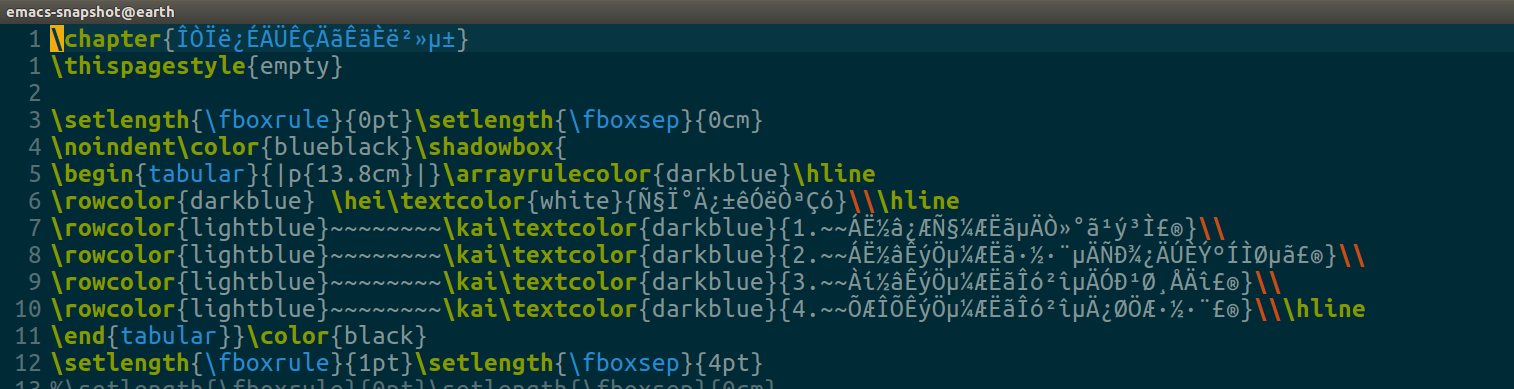
我下了几个latex写中文书的模板(地址),用emacs打开后,发现中文部分显示为乱码,如下图:
网上查到了Emacs打开文件乱码的解决办法, 具体做法是:
-
M-x describe-coding-system查看使用的编码方案: - 换成正确的编码方案:
M-x revert-buffer-with-coding-system
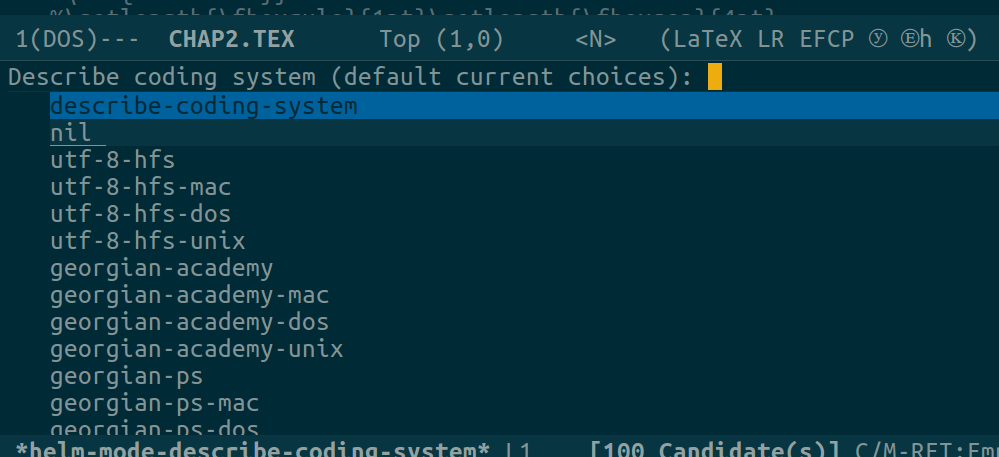
可是我试了几种编码方式(跟utf-8相关的几个都试了,见下图),都不能正常显示中文。
我下了几个latex写中文书的模板(地址),用emacs打开后,发现中文部分显示为乱码,如下图:
网上查到了Emacs打开文件乱码的解决办法, 具体做法是:
M-x describe-coding-system 查看使用的编码方案:
M-x revert-buffer-with-coding-system
可是我试了几种编码方式(跟utf-8相关的几个都试了,见下图),都不能正常显示中文。
模板的下载链接里提到要用UTF-8编码打开,我觉得我已经这么做了呀。
会不会跟操作系统有关?我用的是ubuntu,而这些文件是win下生成的?
试试 GBK?
感谢! 用GBK 成功解决!
能稍微解释一下吗?
根据经验,这乱码看起来像 GBK。(水木 BBS 的GBK 在 UTF-8 的终端下显示就是类似这样。)
估计上传文件的时候被网站强制转码了。或者这文件就是在 windows 下生成的。
下次遇到乱码可以用 file 命令查看编码。
确实是这个编码,但是怎么把文件编码方式改回去呢?
Emacs打开文件乱码的解决办法 这里说可以
“C-x f 编码方式”,“C-x C-s”
用其他编码保存文件来彻底解决问题。
但是我试了一下,怎么不行呢,重新打开文件又乱码了! 一个个文件去修改编码方式太费劲了,可不可以把这些文件批量地转换编码方式?
你需要 (RET 为回车键)
C-x RET r (即 revert-buffer-with-coding-system 命令)
输入 “GBK” 回车C-x RET f (即 set-buffer-file-coding-system 命令)
输入 “utf-8” 回车C-x C-s 保存或者在文件开头添加 %% -*- coding: utf-8 -*- 然后保存
如果有很多文件,可以用命令行的 iconv 处理
这个年代,GBK 编码的文件就不应该存在… 写Python时被这种格式坑过… 

Unicode 中文字不够全,没有录生僻字异体字,一些不同的字还占了同一个码位。
