最近应邀在做一个爬虫项目,主要是爬取 去哪儿/南方航空 的一些数据,后面可能涉及自动下单订票(关联上支付宝这些)
第一步 (Mission Complete):
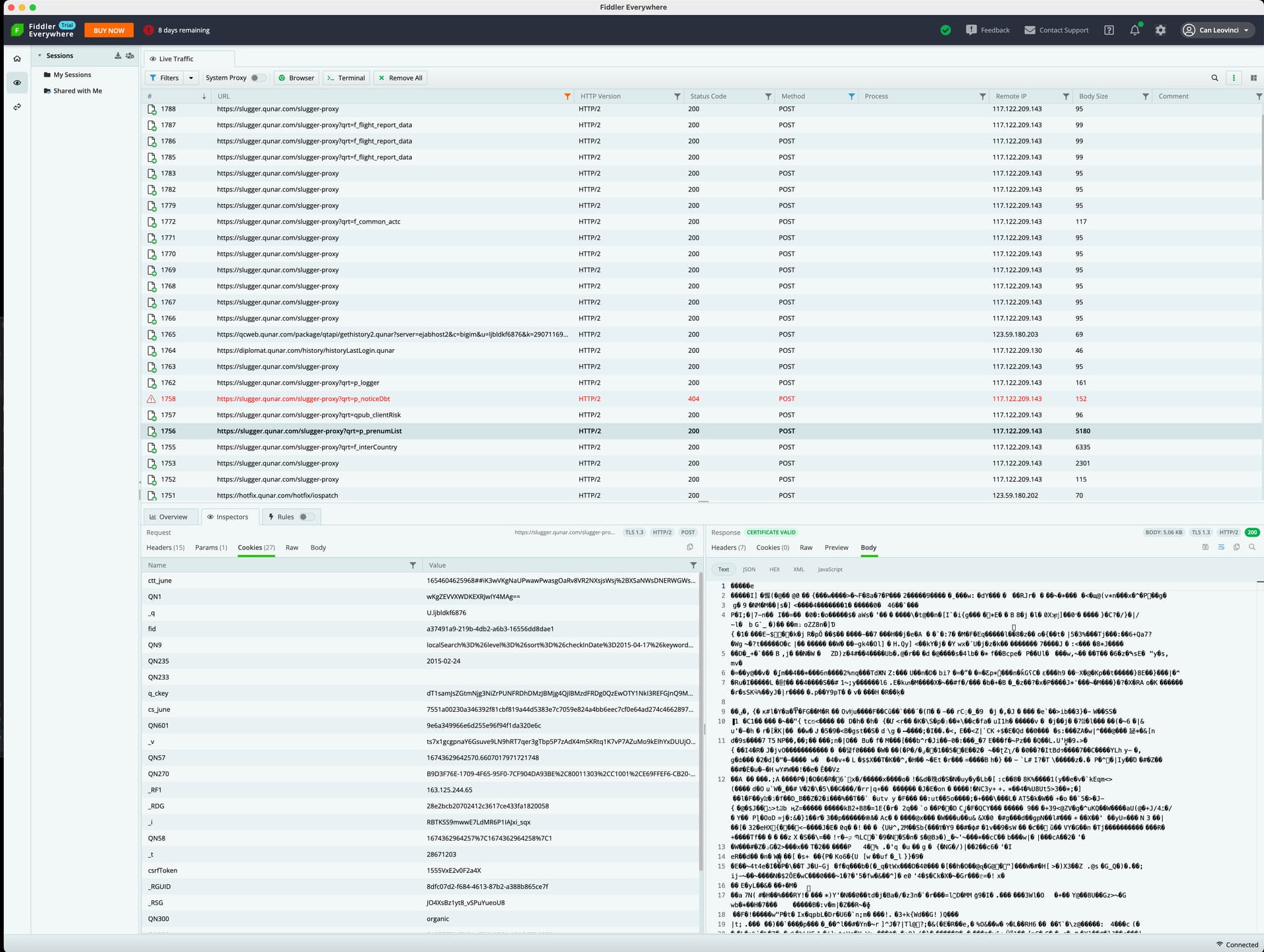
爬取到他们的数据再解析,用Fiddler,以前用过Charles,但是这个好像更好用
第二步 (Learning):
解析他们的数据,现在遇到的难点是,那些数据大都是二进制binary(少数JSON)?
What should I do?
既然是二进制就是为了防爬吧?估计没有希望了,但是伙伴给我掩饰他们在用的服务已经做到了,他就是想自己弄来取代他们,所以是有希望的?
该如何破呢?
Lee
2
这些网站本身有二进制解析的 javascript 代码实现吗?
我也是准备摸索一下网页版
因为现在客户要下的订单优惠只有在app才能够享受到(而且是VIP用户)
这些数据看起来像是做了加密,分析下js看看怎么处理的?app的话得逆向分析app把
Lee
5
无论是网页端的,还是移动端的,针对这类数据,都需要了解它是怎么解析的,最后都要看代码是怎么实现的,加油吧,除此之外,我不清楚还有什么手段了。(说明:不是爬虫大佬)
我试过爬取京东/阿里的拍卖数据,没有看过代码,就看了他们的HTTP请求,分析他们的参数和得出的数据,他们大都就是JSON格式返回数据,而现在的app大多是二进制(好像)
建议试试从网页版js入手,跟js比app容易好多咯,app的话Android比iOS容易,不过一般APP都有混淆了,再高一点的我估计会把代码放静态库里。
1 个赞
wsug
8
我来分析一下,得到一个二进制文件,先要判断文件是什么类型的,某此内容不方便公开分享,要加密后才能分享,通常就是打个压缩包zip或者多压缩几层在分享,不需要具有编程知识。
二进制文件来源处没有给出文件是什么类型,除了靠猜以外,也可以通过二进制文件的内容来判断文件的类型。我用过php的 mime_content_type()函数,就是根据文件的内容返回文件的mine类型,知道二进制文件的mime类型后,可能你改个后缀名就能得到文件内容了
1 个赞
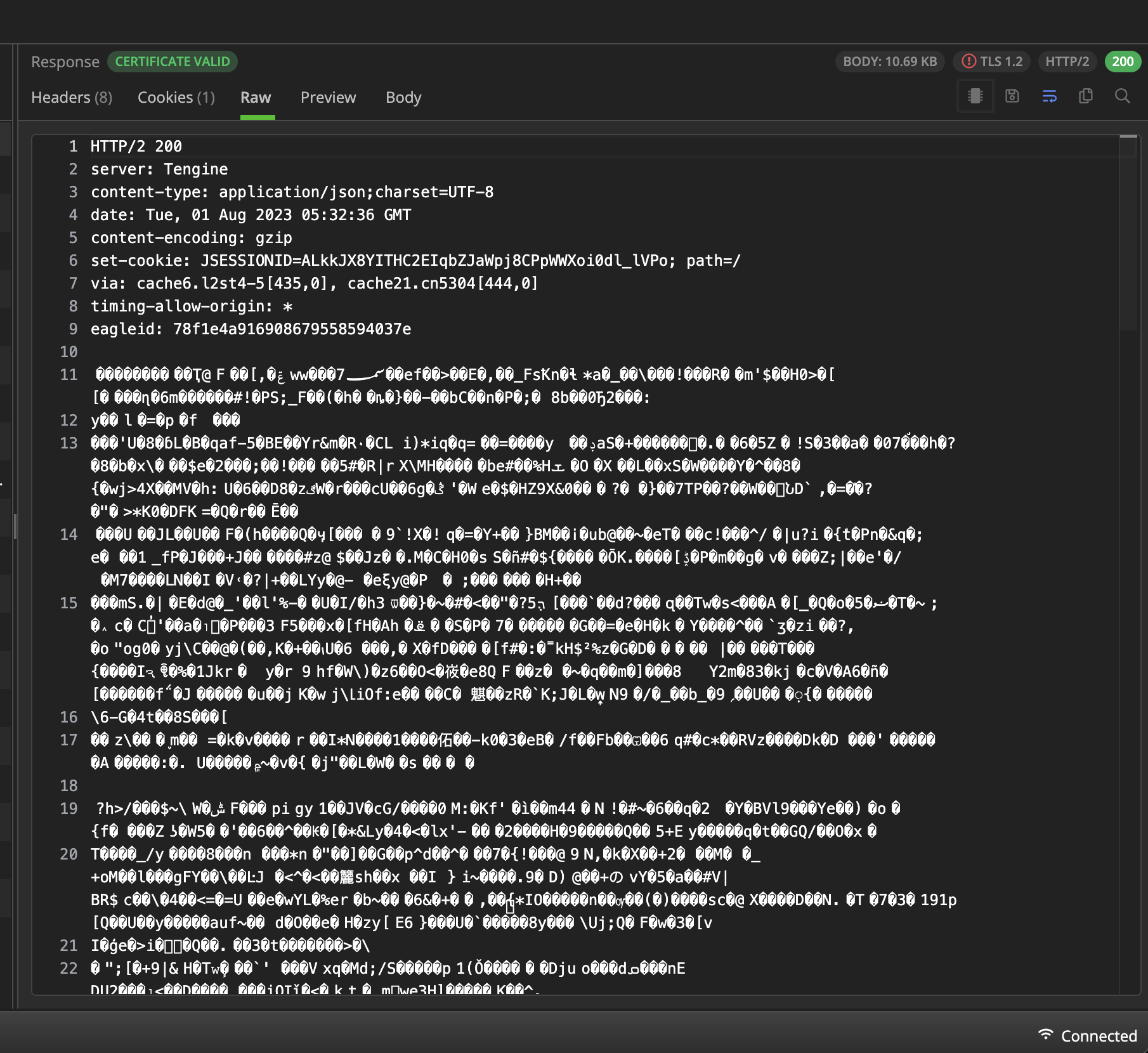
看样子是先用自己内定的算法加密 (类似base64, 但是不公开的算法), 在用 gzip 压缩, 这可能就很难破啊~~
解压(gzip)前:
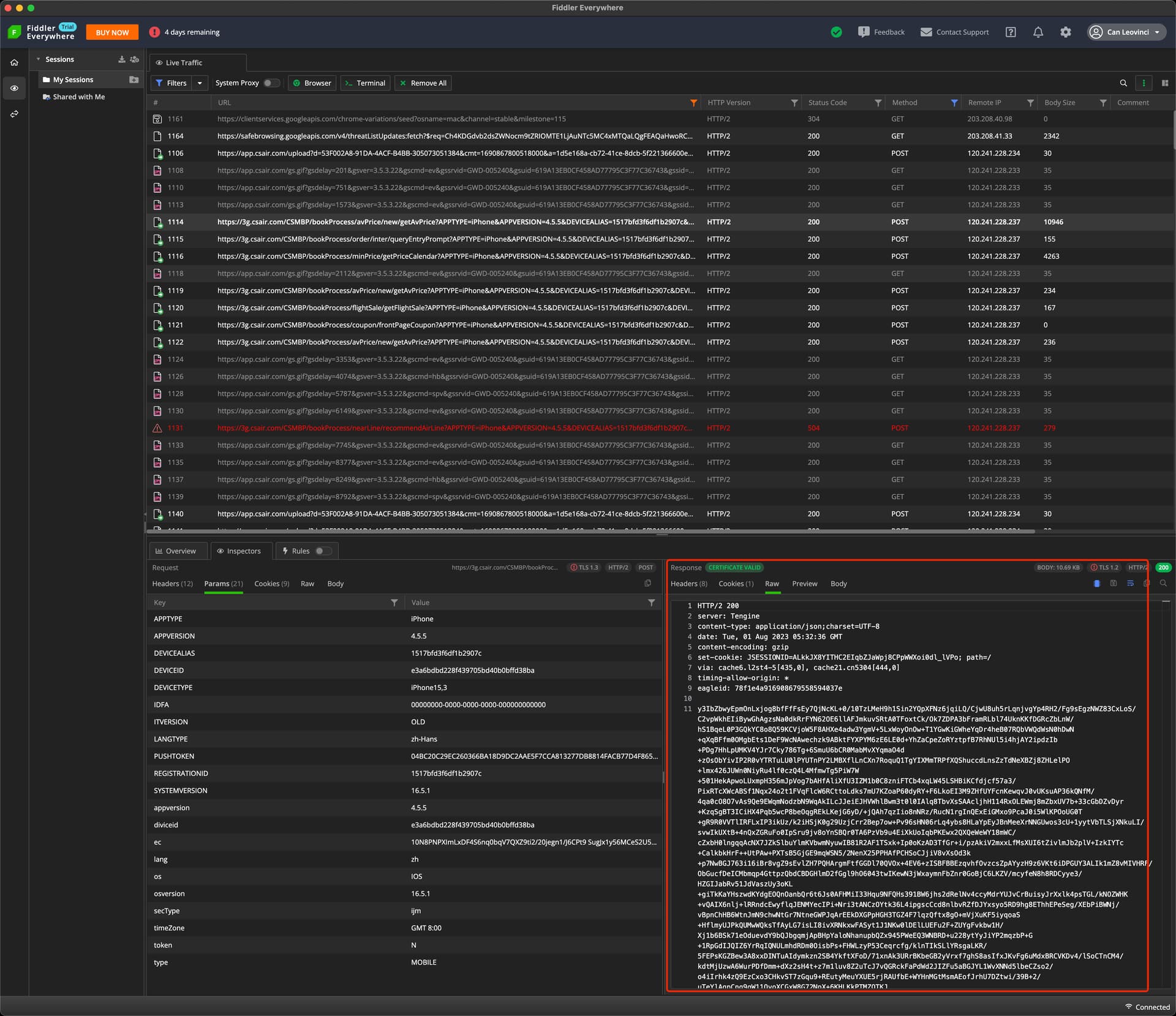
解压后: