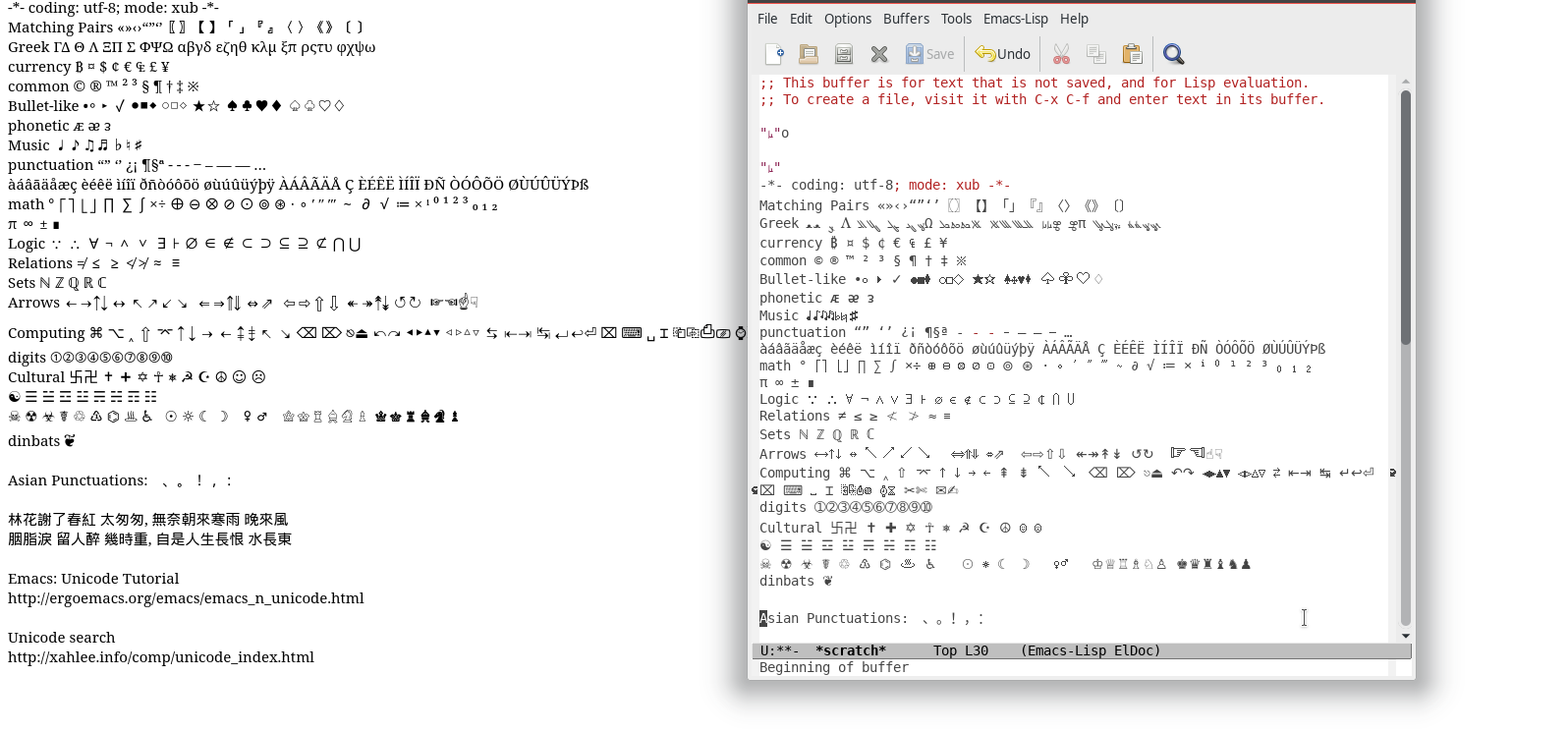
我相信这是一个重要的问题。
目前的各种编码方式乱七八糟,语言对它的支持也各式各样,像python用起来就很省心不要太操心编码问题,而C语言就要折腾各式各样的编码问题了。
我查了emacs-lisp的文档,发现有三个概念: string , unibyte 和 multibyte。
我英语不好,读了半天也没能理解到底是什么意思。
我还找到了一篇文章:http://www.tuicool.com/articles/BZzENf 很尴尬,我又没看懂:joy:
在我浅薄的知识里,我觉得字符串应该有以下几种可能的形式:
- 由一个个的单字节构成,是字节串。类似python的bytes,需要结合一种具体的编码才能确定里面的内容。
- 构成元素是一个个的多字节。每一个多字节代表实际上的一个字符,类似python的str类型。
还希望有大神具体讲解下emacs-lisp对unicode的具体支持。
。。。。
String,字符串,基本上大部分语言都有的概念。emacs-lisp的字符串概念和别的语言没有什么区别。
现在 emacs 默认支持 unicode(UTF-8),不需要什么额外配置。el文件里面直接可以上。
倒是以前用GBK的需要另外指定编码。
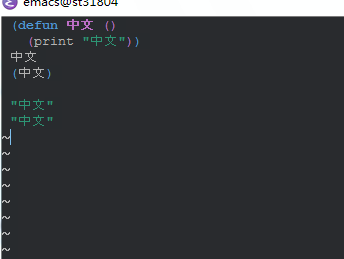
看了下URL里的文章,首先就提到现在Emacs内部的所有字符都是UTF-8,其他编码都是先转换然后再处理的。
Proper string comparison requires normalization.
然后一些UTF-8的字符可以用不同的编码表述,Emacs并不会自动识别,比较的时候要先转换。
(string= "nai\u0308ve" "na\u00EFve")
;; => nil
(string= (ucs-normalize-NFD-string "nai\u0308ve")
(ucs-normalize-NFD-string "na\u00EFve"))
;; => t
不过如果不处理欧洲的一些语言的话似乎用不到这些。。
编码问题我是清楚的,只是不了解emacs-lisp这门语言对其支持的具体细节。
感谢回复 。主要问题在于我在使用emacs-lisp进行编写扩展的时候,发现关于字符串对中文支持的一些奇怪的行为。
比如说,我在使用web-server这个插件时,如果将GET请求的数据(带中文)回显给浏览器,一切正常显示。
但是如果我用emacs-lisp的print函数将其输出,则会发现输出的是一串乱码。
这迫使我将搞清楚emacs-lisp具体是如何区分这些东西的。
比如说,我找到了几个函数string-to-multibyte,string-to-unibyte等等,这不免让人疑惑,unibyte和multibyte是什么?它们底层是如何表示字符串的?而emacs-lisp又是如何理解它们的?
根据你的问题我继续讲那篇文章。
Emacs ,如你所说,有那两种数据类型,unibyte multibyte 。
简单来说,unibyte 是原始码,在内部用整数来表示,比如a就是1,b就是2(只是比如,实际大概不是这样。),这样不管有多少种字都不怕(似乎这种编码是动态分配的)。这是用来定义数据的(我发的图片中白色的“中文”),因为Emacs自己不需要知道这是什么意思。字节前用反斜杠区分。实际上这类数据几乎不用处理。离开Emacs后就自动转化成对应的字符编码。
multibyte 就是直接用UTF-8了,用在String里,做些文字处理,比如统计字数。
但是有些字符不在Unicode 里面呢!比如一些生僻字。Emacs在UTF8 中额外加了些字符,利用unibyte 表示。
至于你提到的print问题,大概是没指定好对应的编码而已。其实解决这问题用不到这些知识。
2 个赞
我的那个问题找到答案了,使用的decode-coding-string函数。
上一段demo:
(let (s1 s2 s3)
(setq s1 "测试")
(setq s2 (encode-coding-string s1 'utf-8))
(setq s3 (decode-coding-string s2 'utf-8))
(print (length s1))
(print (length s2))
(print (length s3))
(print (string= s1 s2))
(print (string= s1 s3))
)
2
6
2
nil
t
可以看见,还真的和python3挺像的。没encoding的长度为2,说明把每一个汉字作为一个基本的字符单元。encoding后长度为6,说明储存的是其utf8编码后的字节串。
最后弱弱的吐槽一句,作为一个 Emacs 论坛,为什么不能用org格式写帖子。
org的一部分功能在Emacs以外的地方没有什么用。然后org的默认行为对于中文支持不是很好。
After I pasted "λ" into my emacs(from my grandpa’s os):

More:
I realized my emacs have some problems with Unicode(other editors like sublime3 display them correctly), esp for lowercase greek symbols. Ditto for emacs -Q.
In xah lee’s site, I found
(set-language-environment "UTF-8")
(set-default-coding-systems 'utf-8
But still, don’t work.
What’s strange is on my laptop, these symbols always work fine with or without -Q.
Then I found this thread:
(require 'unicode-fonts)
(unicode-fonts-setup)
profile:

problem solved. I went to project page:
As the manual warns, the choice of font actually displayed for a non-ASCII character is “somewhat random”.
IIUC, vanilla emacs’s support for Unicode is not good enough and sometimes some more configurations is necessary, that’s why the package
unicode-fonts exists.