怪我没说全,只记录遇见次数是否掌握这个功能 
遇见单词这个功能还行。
可以添加一个功能:“查词计数”(只需要将查过的词与相关的上下文保存起来就可以了)。这个比较容易实现。不过上下文中的位置信息可能会总变,不好保存
由于遇见单词中的上下文都是网页,emacs里面跳转链接倒是可以,但添加新词还需要到浏览器里面。获取查询次数可以融合进“查词计数”里面,但没有上下文总觉得缺点什么。
前些天有个帖子讨论过渐进式总结,查询过的单词可以算是总结的一个方面。
原来是这意思。
现在 fanyi.el 没有对查询的单词做持久化,你的意思是也跟遇见单词一样提供一个加号可以把它加到一个单词集里?
这个想法确实不错,而且在逻辑上也不太重,不过这样的话 fanyi.el 慢慢地开始有了一个背单词 app 的雏形了. ![]()
我怎么感觉这个像是 org-capture 的功能。
在最新的 fanyi.el 里提供了简单的生词本功能 (通过 bookmark 实现)。
在 fanyi buffer 里 C-x r m 创建对应当前单词的 bookmark, 然后 C-x r l 来查看所有的 bookmark. 于是这样就偷懒把单词持久化的功能交给 bookmark 来处理了,计划通!
用bookmark虽然简单,但单词多了,bookmark list 就会变长,影响使用 bookmark.
1 个赞
可以和anki结合一下,用org文本记录生词就可以了。
 充分体现了有舍也有得,所以这只推荐轻度使用“生词本” 。
充分体现了有舍也有得,所以这只推荐轻度使用“生词本” 。
还是用sqlite做存储吧,org-roam也是用sqlite。
不需要org的capture,记单词的capture。
不太想搞存储啊,主要是这个 sqlite 依赖太大了。
1 个赞
最近 fanyi.el 集成了 org,主要是可以在 org-mode 里
-
C-c C-l,然后可以选择
fanyi形式的链接 (前缀就是fanyi:),然后会通过历史搜索纪录来补全。 - 在 fanyi buffer 里也可以通过
org-store-link来存储类似fanyi:the-query-word的链接,当然这后面也可以通过 C-c C-l 来插入。 - 如果在
[[fanyi:happy][desc of happy]]上按 C-c C-o 的话就会直接调用 fanyi 来搜索
当然这个 org 集成不是默认就开启的,需要用户显式地
;; 目前没有单独打包,从 melpa 安装 fanyi 的时候就会有了
(require 'ol-fanyi)
不然 fanyi.el 默认就依赖 org 就太影响加载时间了。
初步在 fanyi.el 里支持了句子(使用的是 https://libretranslate.com/ 的实例)。
libretranslate 对于中文的翻译效果不怎么好,近期看看能不能把 youdao/bing 的句子翻译给集成了了。
1 个赞
好奇,为啥不考虑谷歌翻译呀
 因为服务器上连不上啊
因为服务器上连不上啊
谷歌翻译不是有支持不挂代理也能访问的api嘛,
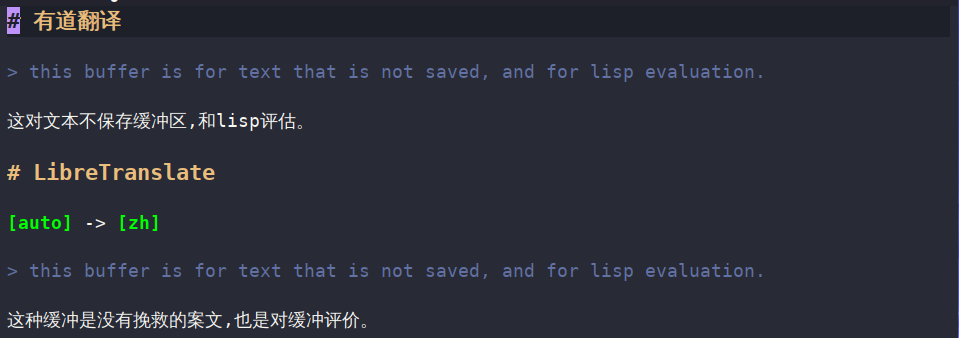
比较麻烦的一点是要计算 token,不是很想引入这种复杂度(懒)。
这样的翻译还是不要了吧!这个时候查例句或许更合适。
我也感觉可有可无,主要是内容太少了
项目已加入 https://hacktoberfest.digitalocean.com/ , 贡献 PR 可以获得 hacktoberfest 积分 ![]()
目前是打算集成
1 个赞