4.案例与习题
SICP习题过多, 目前的处理方法是建索引, 梳理思路.
org可以给代码块,图片等命名, 格式为 #+name
例如书中的案例:
#+name: case-4.1.2-self-evaluating
(define (self-evaluating? exp)
(cond ((number? exp) true)
((string? exp) true)
(else false)))
"#+name:" + "case-" + 小节序号"4.1.1" + "函数名"
书中的案例分散在各处, 刚上手开读, 不太可能过目不忘, 而读下文回想上文,巨耗脑力;
如果持续使用C-s随机跳转, 思路会搅得杂乱无章;
解决的方法是命名代码块, 自定义索引.
梳理思路
建立索引后, 可以从mini-buffer中查看局部的框架
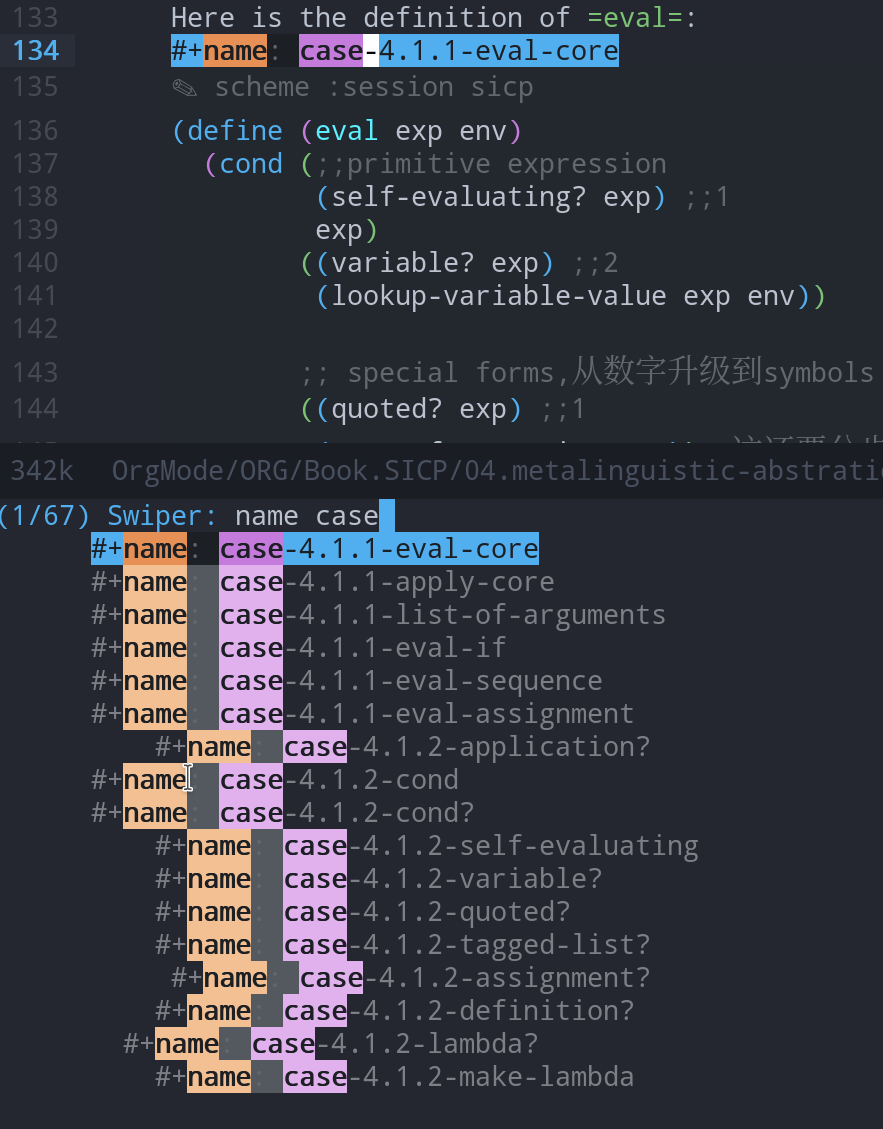
也可以调用grep查看, 尤其是复盘的时候, 可以只看着grep的清单, 尝试重新构建出来.
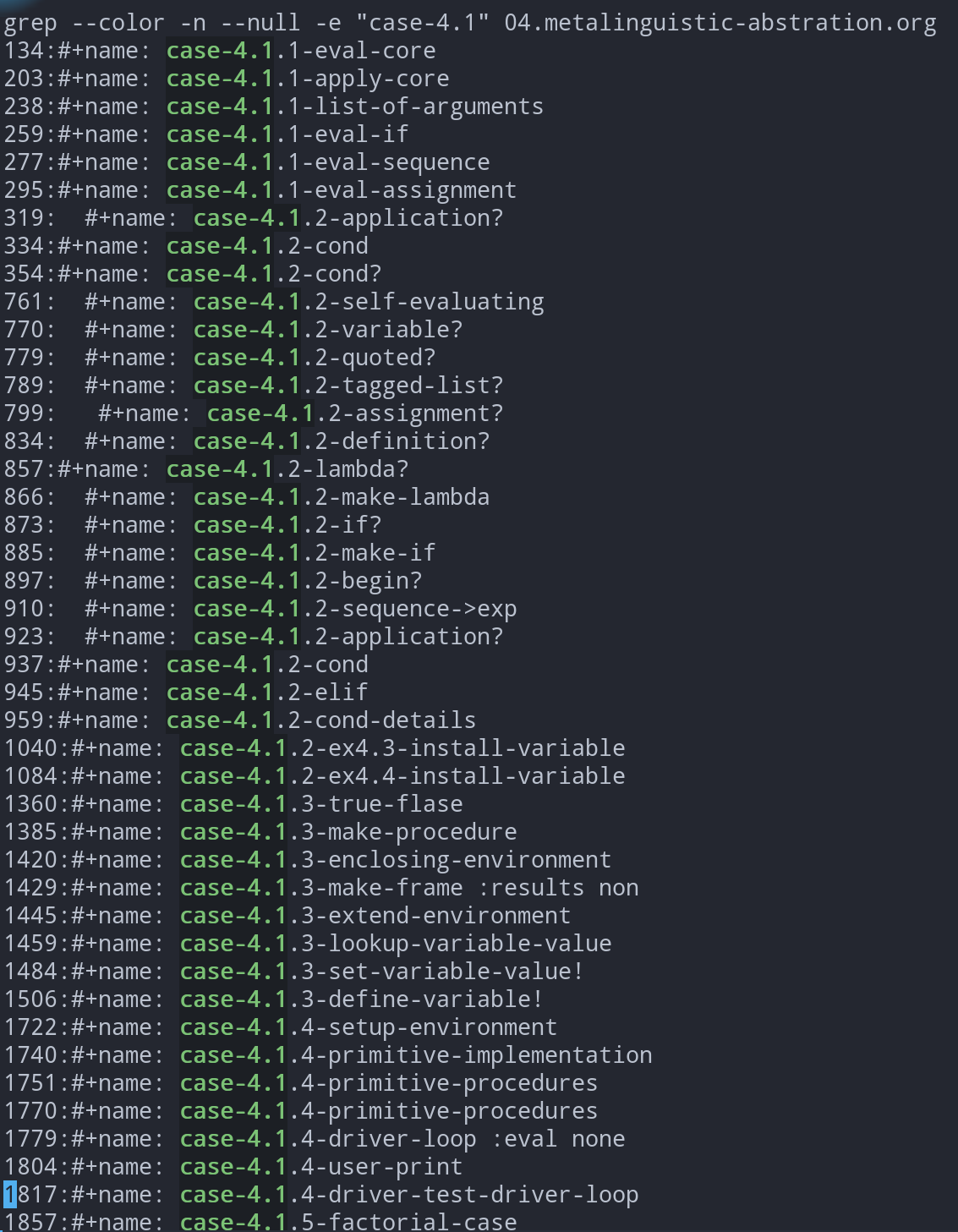
跳转查询
比如当读到`define analyze`的时候突然忘记了`self-evaluating`的定义
(define (analyze exp)
(cond ((self-evaluating? exp)
(analyze-self-evaluating exp))
((quoted? exp)
(analyze-quoted exp))
((variable? exp)
(analyze-variable exp))
((assignment? exp)
...
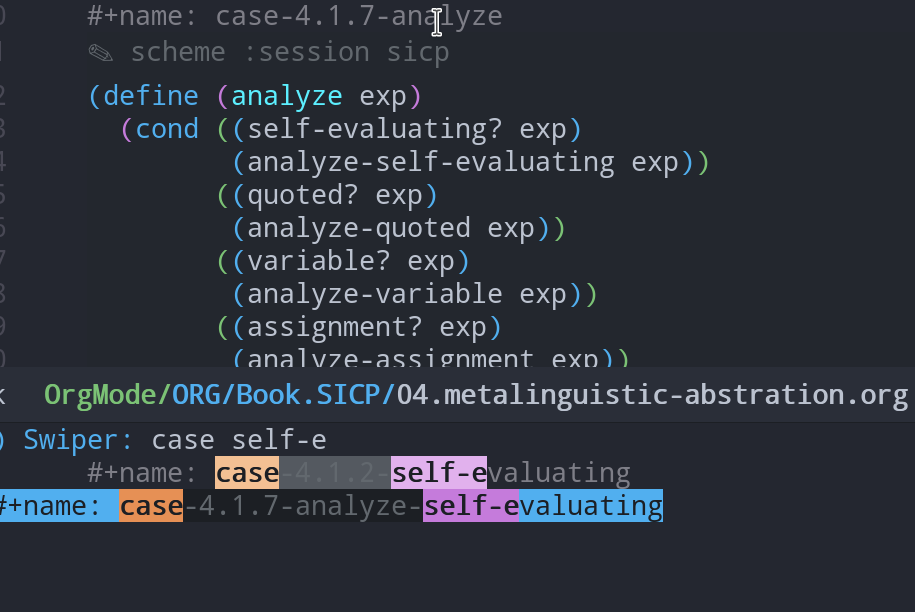
从结构中能清楚地看到"目标位置"是在大纲目录下的4.1.2中,
如果直接搜索"define (self-eval", 则第一眼看不到大纲.
mini-buffer内的中操作:C-n C-p
如果点进去去查看细节, 结束之后按键 C-u C-@
可以重新回到 (define (analyz) 这个起始位置.
习题
如果直接查看"Exercise"

大概能了解到有80个习题和粗略的进度(标注[X]),
但也仅此而已, 看不到一道习题隶属哪个章节,
没有整合进大纲结构中.
可以给习题解答的代码设置name, 比如
#+name: case-4.1.2-ex4.4-eval-or
(define (eval-or exps env)
(cond ((null? exps)
#f)
((true? (eval (first-exp exps) env))
(eval-or (rest-exp exps) env))
(else
#f)
此时在查看"case-4.1.2"的时候, 习题与案例连成一体, 都在"4.1.2 Representing Expressions"之下.
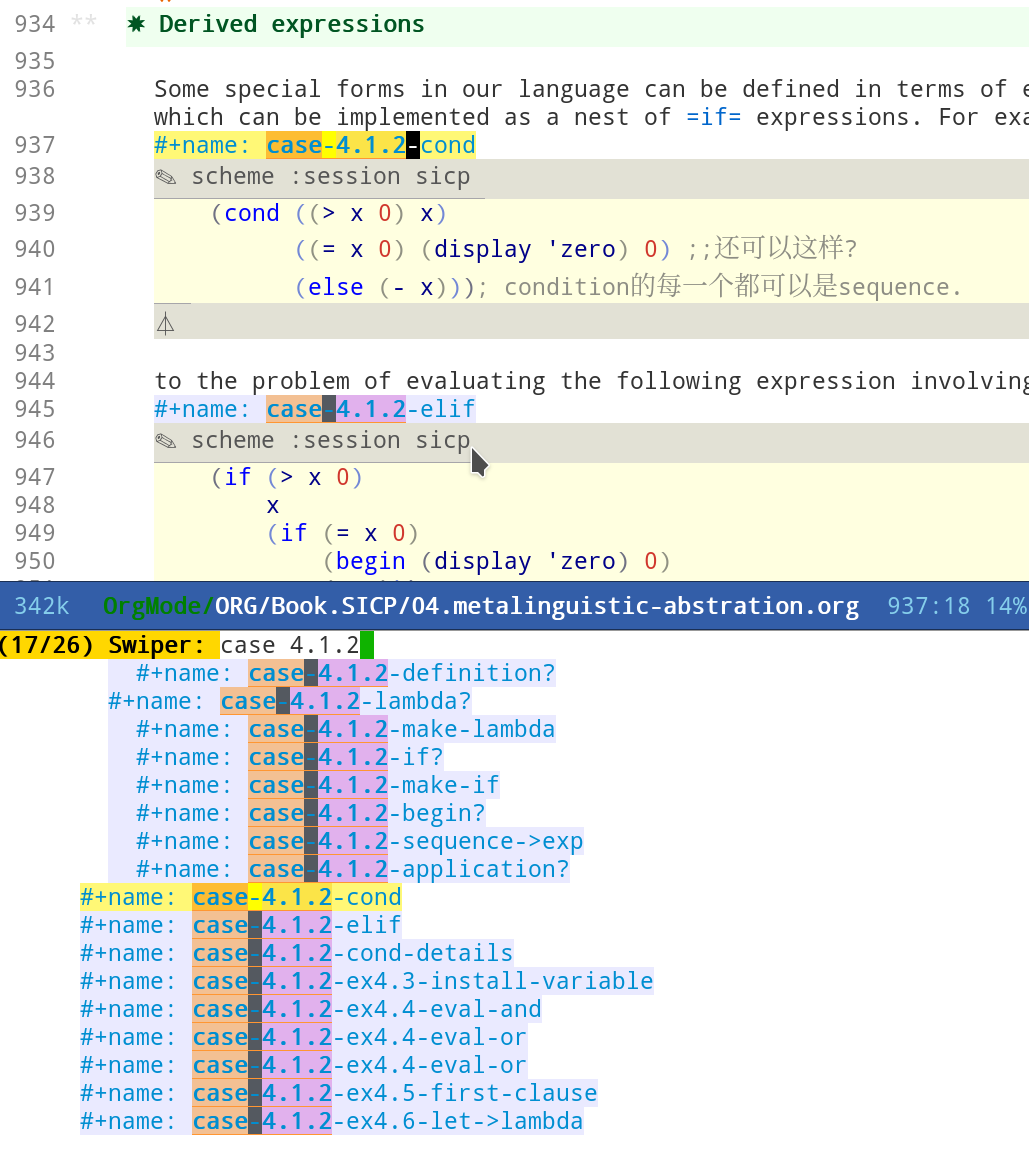
Clock-in
案例与习题命名的格式是"case-4.1.2",
在阅读过程中, 挪用脑力记忆住"4.1.2"这个点位, 或者上下移动光标查看, 不太可取.
在过程控制中, 首要先打开Clock-in,此时可以派上用场. 脑力过于发达可以在大的节点上clock-in比如"4.1", 我是在颗粒度更高的小节点"4.1.2"上clock-in, clock-out.
案例与习题小结
案例与习题是洒落一地的珠子,
初次阅读在代码之间随机跳转参阅, 劳神费力;
建立索引是将珠子串起来, 梳理思路和参阅.
比如本章中的两个基础定义 eval
and apply
分别建立索引"#+name: case-4.1.1-apply-core"和"#+name:
case-4.1.1-eval-core",
便能C-s "case eval core"准确的一步定位.
如果用查询"define (eval)", 则需要消耗点脑力构建regex规则过滤掉其他备选项,
而此时大脑正在全神贯注处理当下问题,
最好不要被分神打扰.