0.序
本文为项目"步步为营, 零秒精通Emacs"的第四章"Emacs as a Notebook by Org"
一本书读过之后, 当再次拿起来的时候, 仿佛读新书一样;
读了, 看了, "劳民伤财"投入大量时间与精力, 但是记不住怎么办?
本文试图解决这个问题, 以SICP的第四章(Metalinguistic Abstraction)为例
论述分为六个部分:
- 启动-绘制大纲, 拿着地图阅读;
- 过程控制, 利用org-clock以及标签, 在控制过程的同时, 为后续的复盘预备第一手的线索;
- 阅读管理, 正文阅读阐述如何应用标签提高阅读效率, 并为后续查询参阅提供好用的数据结构;
- 案例与习题, 讨论怎样索引和处理书中的案例与习题;
- Org的撒手锏;
- 收尾, 总结探讨提高技术水平的同时, 稳扎稳打从每次阅读中提升英语能力.
- 附录: 参看书目
1.启动-绘制大纲
关于大纲目录的重要性, 引用王垠在"如何成为一个天才"中的一段话:
如果你看过John Nash 的传记《A Beautiful Mind》,就会发现他与其他人的不同.Nash看书只看封面和开头,把这书要讲的问题了解清楚之后,就自己动手解决. 最后,他完全依靠自己的"头脑暴力"创造出整本书的内容.
天才的能力或许难以企及, 天才的方法却可学可至. 一本书拿过来, 先看封面和目录, 纸笔绘制出来; 目录便是大纲结构, 投入10~30分钟的时间在大纲结构上, 展开"头脑风暴", 如果你在写这本书, 将会如何展开, 根据既往经验与充分想象, "编造"出来大致脉络, "编造", 无拘无束的"编造". 益处有四:
- 梳理和回顾你的经验和知识结构;
- 编造的过程会滋生阅读的欲望, 因为某些部分造不出来;
- 当拿着"我"的思想与"作者"的思想对照之时, 阅读的过程已变为求证的过程;
- 两个思想互相碰撞, 有共鸣有拍案, 不仅会事半功倍的提高阅读效率; 还能更深入的掌握书中的精妙之处.
退一步, 如果一点想法都没有, 半句话也编不出来, 那最好将背诵下来, 待到"厕上枕上马上", 从脑子里拿出来慢慢反刍咀嚼, 驱动潜意识这种神奇的力量开始工作.
纸笔绘制的方法有助于记忆, 而且可以放在手边作为地图参阅.
用emacs-org参阅大纲结构:
方法一: C-n S(shift)-tab
控制目录显示的深度,比如C-2 S-tab显示到2级目录,
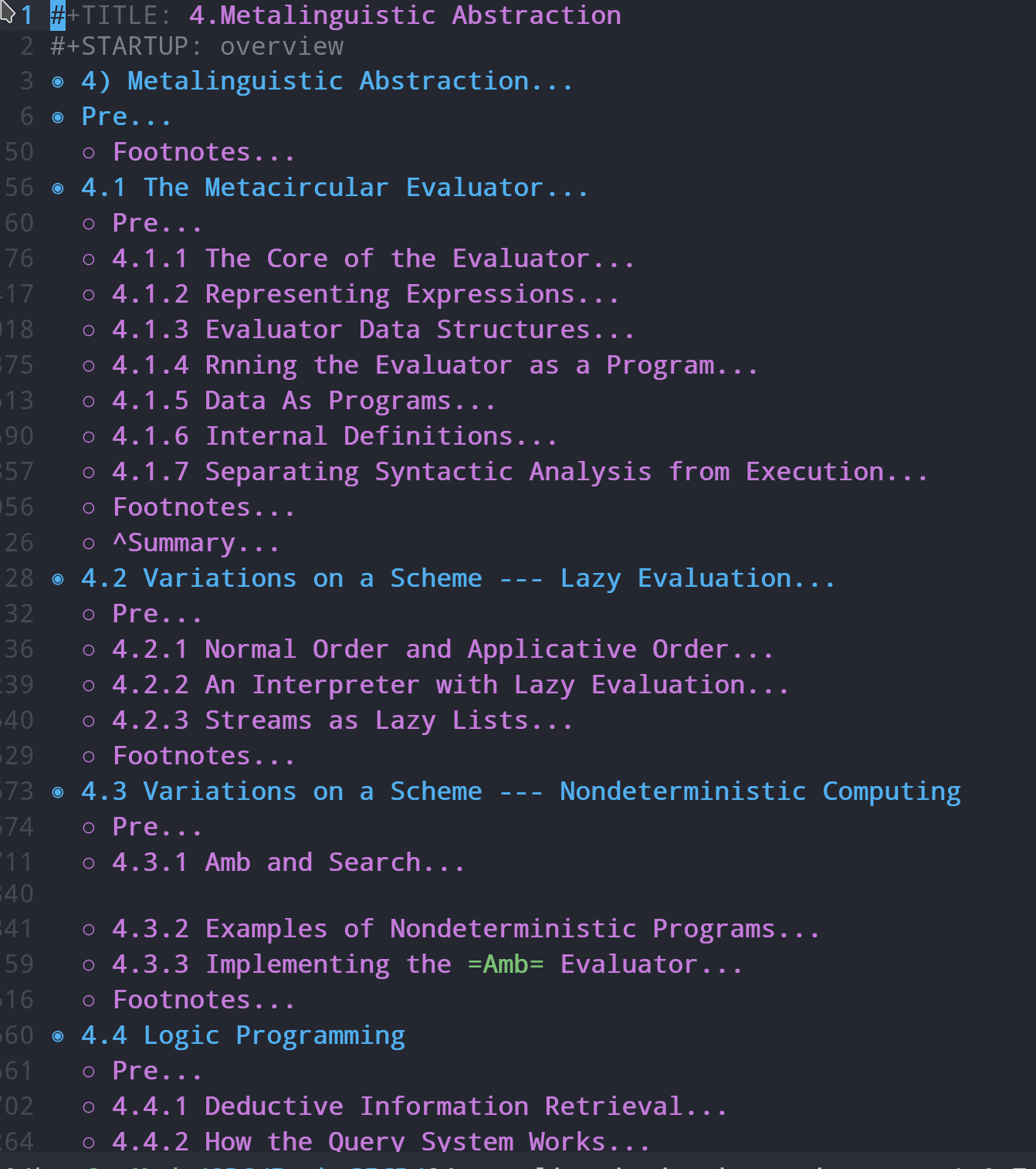
方法的优点是可以自定义控制目录显示的深度
方法二:
直接应用S-tab或者C-u Tab轮巡 ,
,-> OVERVIEW -> CONTENTS -> SHOW ALL --.
'--------------------------------------'
重复操作一次则显示在不同的结构
方法三:
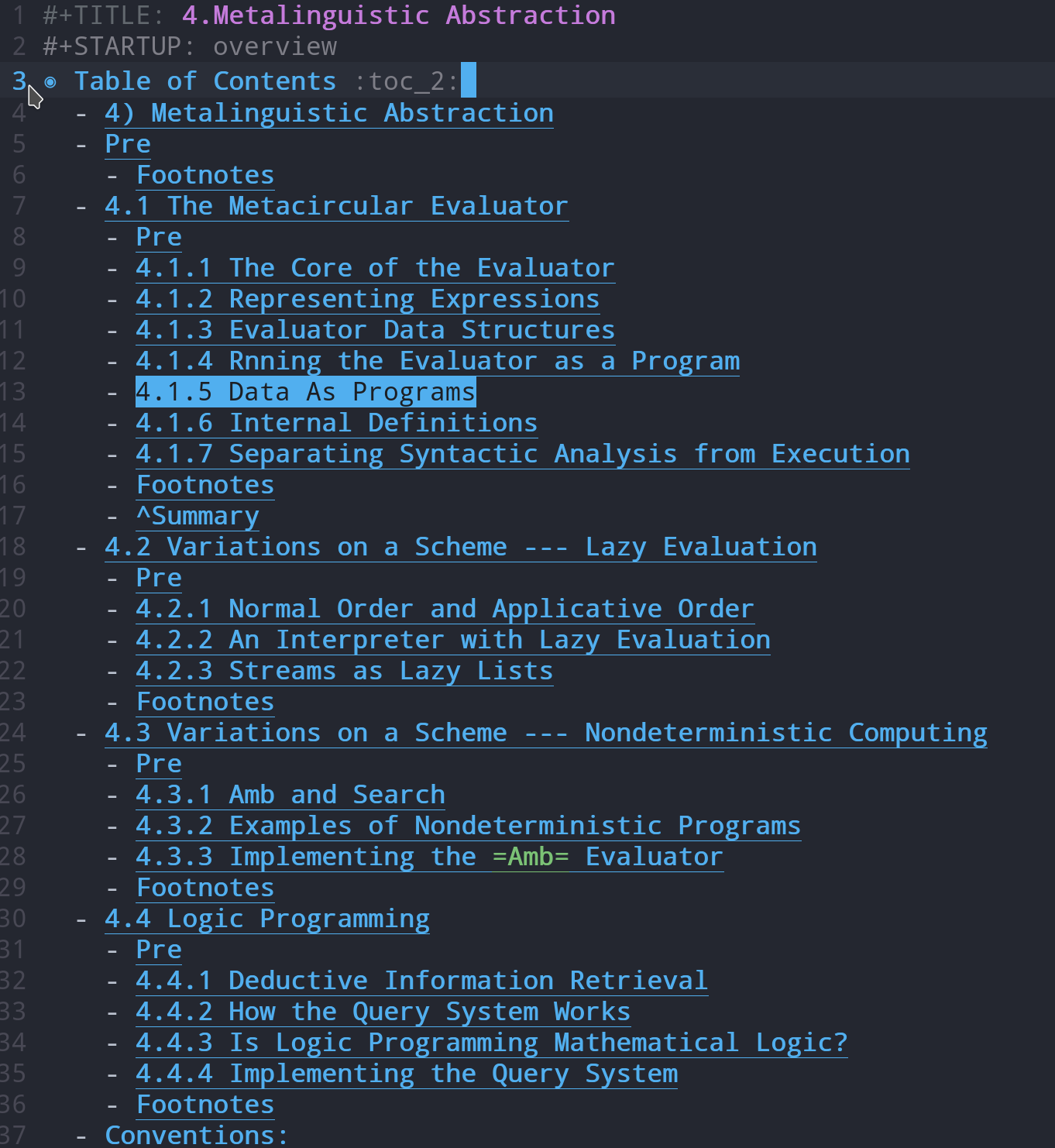
TOC结构, 安装doom-emacs后, 在任意位置, 应用:toc:便能自动生成目录
方法四
推荐的方案,纸笔绘制, 放在手边参阅.

2.过程控制
Clock-in and Clock-out
当前章节下调用 M-x org-clock-in,
- 一方面可以计时,
- 再者则随时提醒当前所处的位置和任务, 及时跳转到其他的buffer中, 也会看到, 比如从4.4.1 Deductive Information Retrieval中激发了clock-in, 则即使在这篇文章的编辑页面, 依然能看到当下的任务, 随时提醒你回去执行.

- clock-in置顶当前任务, 为后文"阅读管理"添加标签提供便利.
随手建立todo任务
比如阅读过程中,发现svg的图片格式在black模式下, 认读需要眼睛对到屏幕上仔细得瞧个清楚, 因此设置任务将inline的图片逐步去掉, 修改成文本格式.
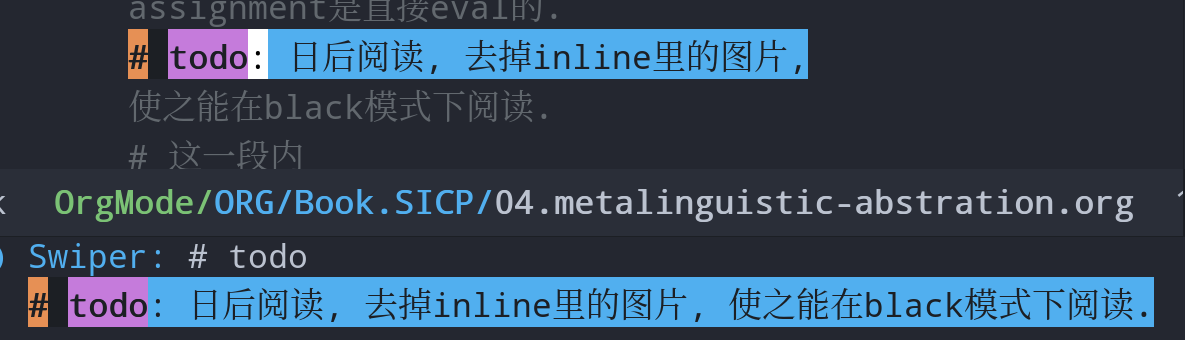
任务完成后变更todo为done
提出问题
过程控制中最重要的一点, 初次阅读的时候, 有困惑的地方, 不理解的地方, 尤其是与你在第一步"编造"和"想象"的内容不一致的地方, 标注成"问题?",
因为是自己的笔记, 只要稍微有一丝疑问, 马上标出来,
我觉着这是宝贵的财富.
一方面, 如果不标注, 过5分钟, 会忘记刚才在想什么
另一方面, 当一年后在读这本书的时候, 可以了解当时的水平, 当时的思考脉络.
问题统一设置成 问题? 的格式, 如此, 不仅是在正文的行首, 或者和在代码的内部, 都能方便查到; 又不会多余查到正常使用的"问题"这个词汇.
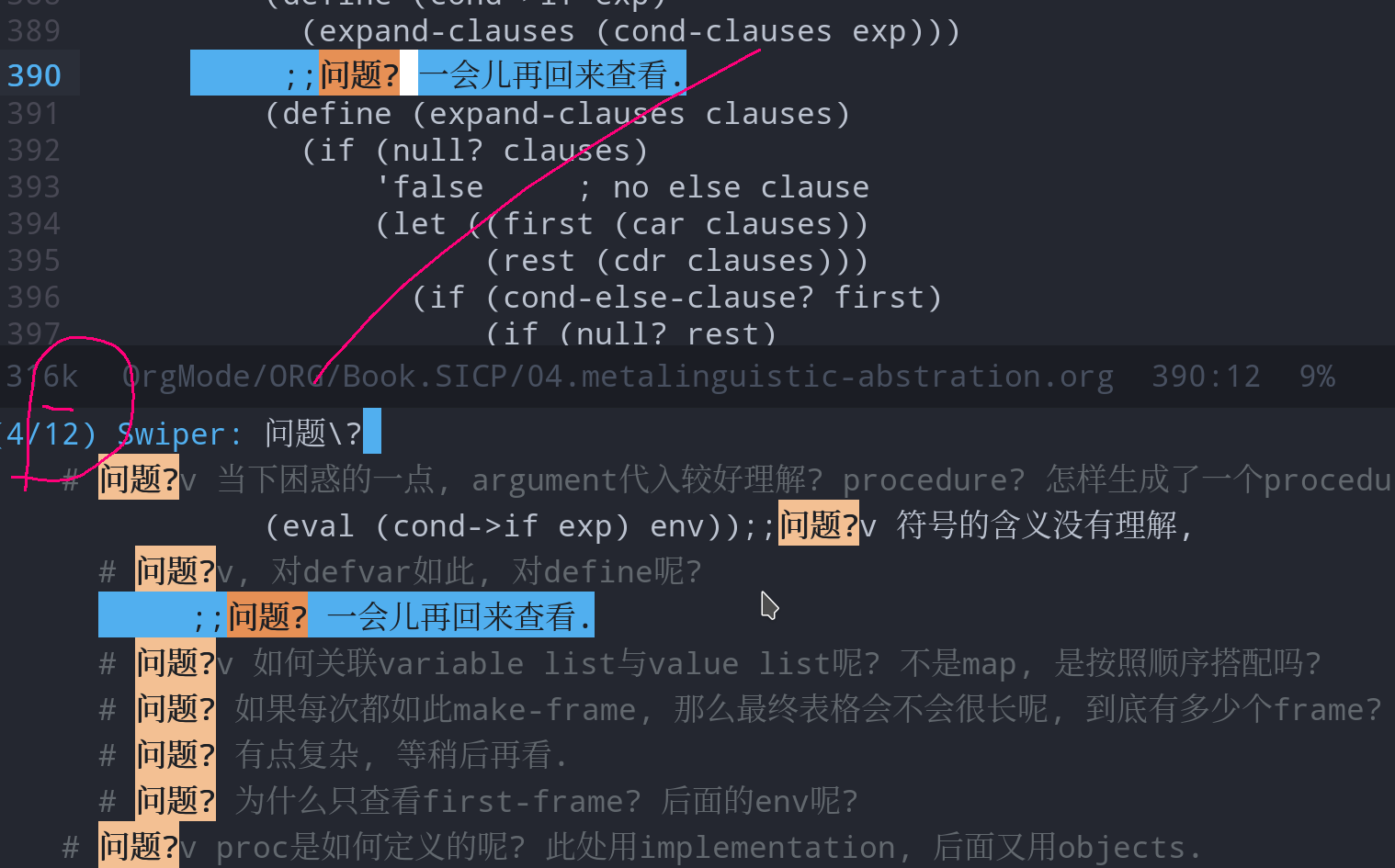
问题解决后, 在后面标注v,v当做是对号.
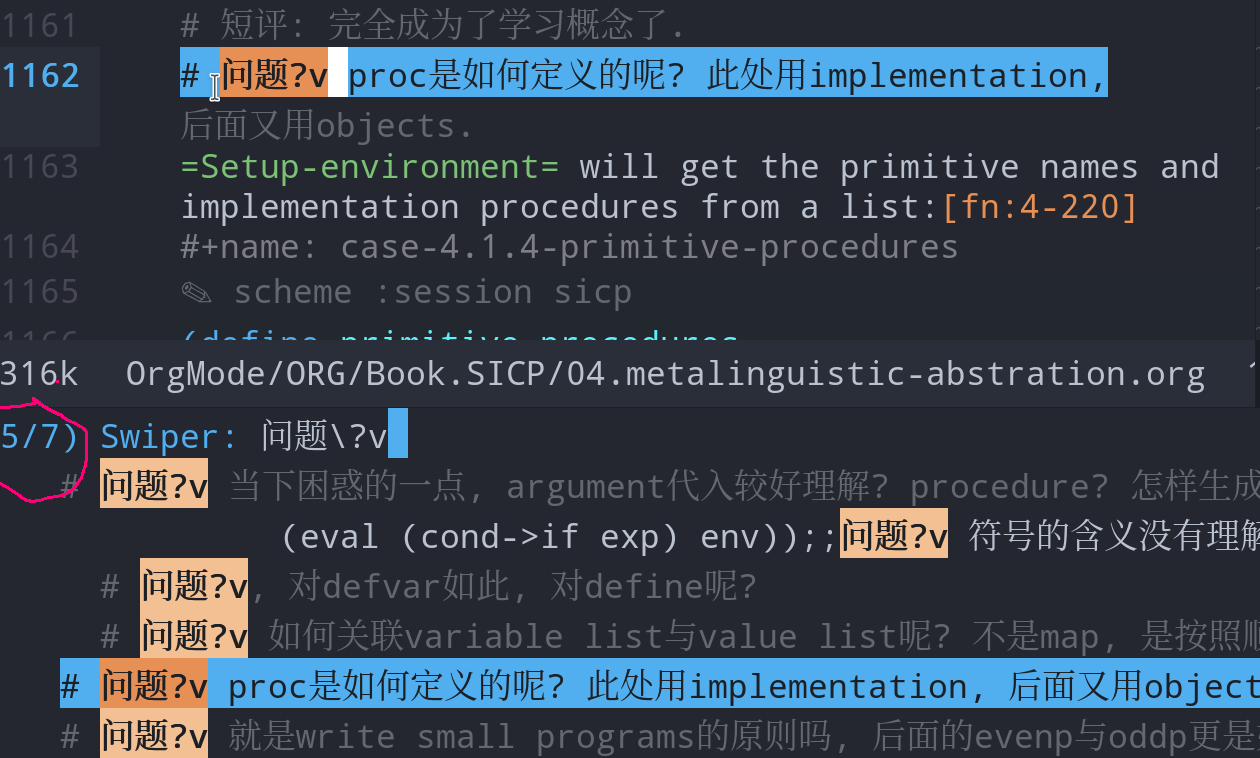
如图, 刚才的12个问题解决了7个, 剩下的可能需要发到stackoverflow上.
过程控制小结:
过程控制使用了todo, 问题标签.
后文的"阅读管理"中探讨,
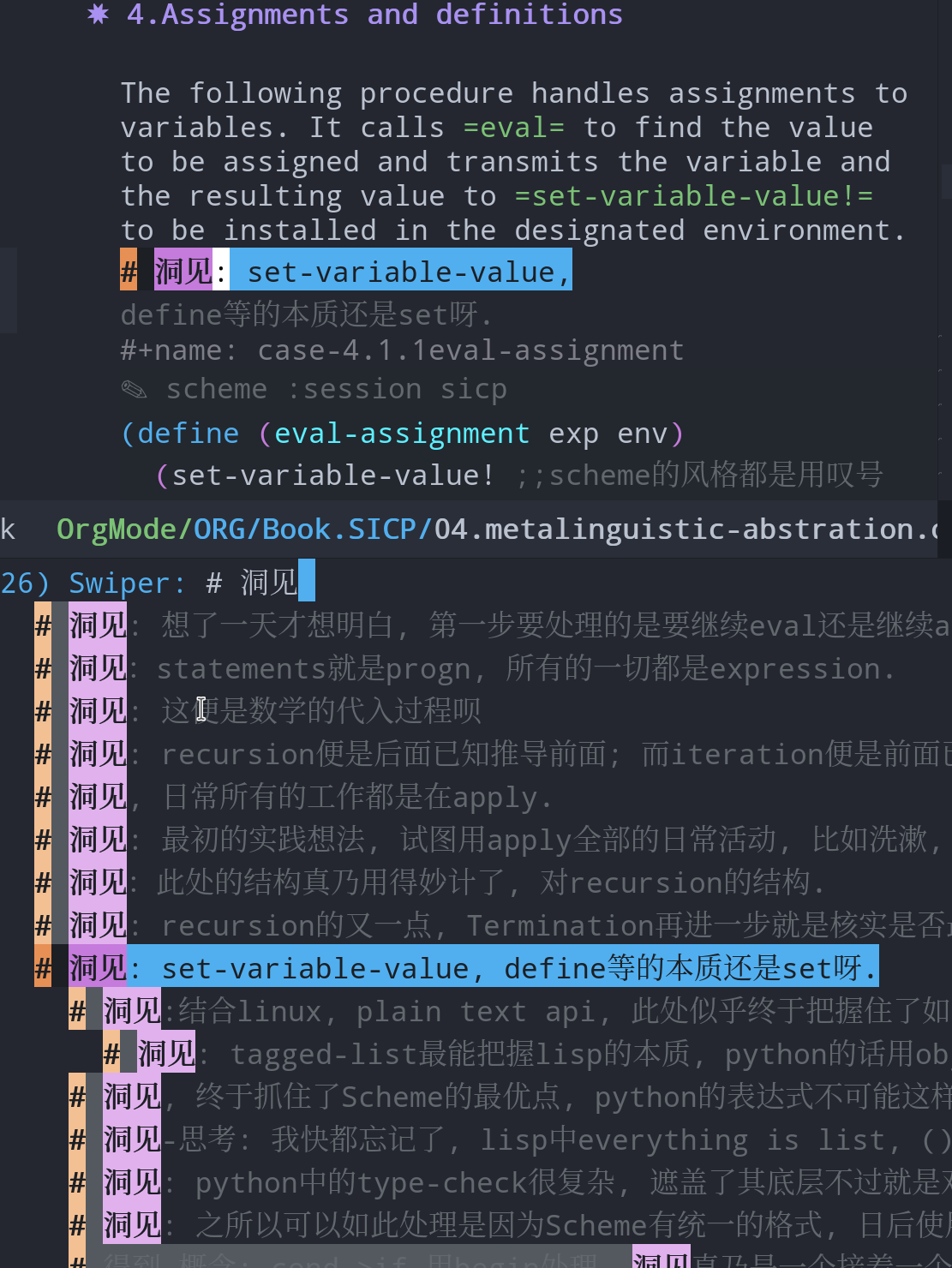
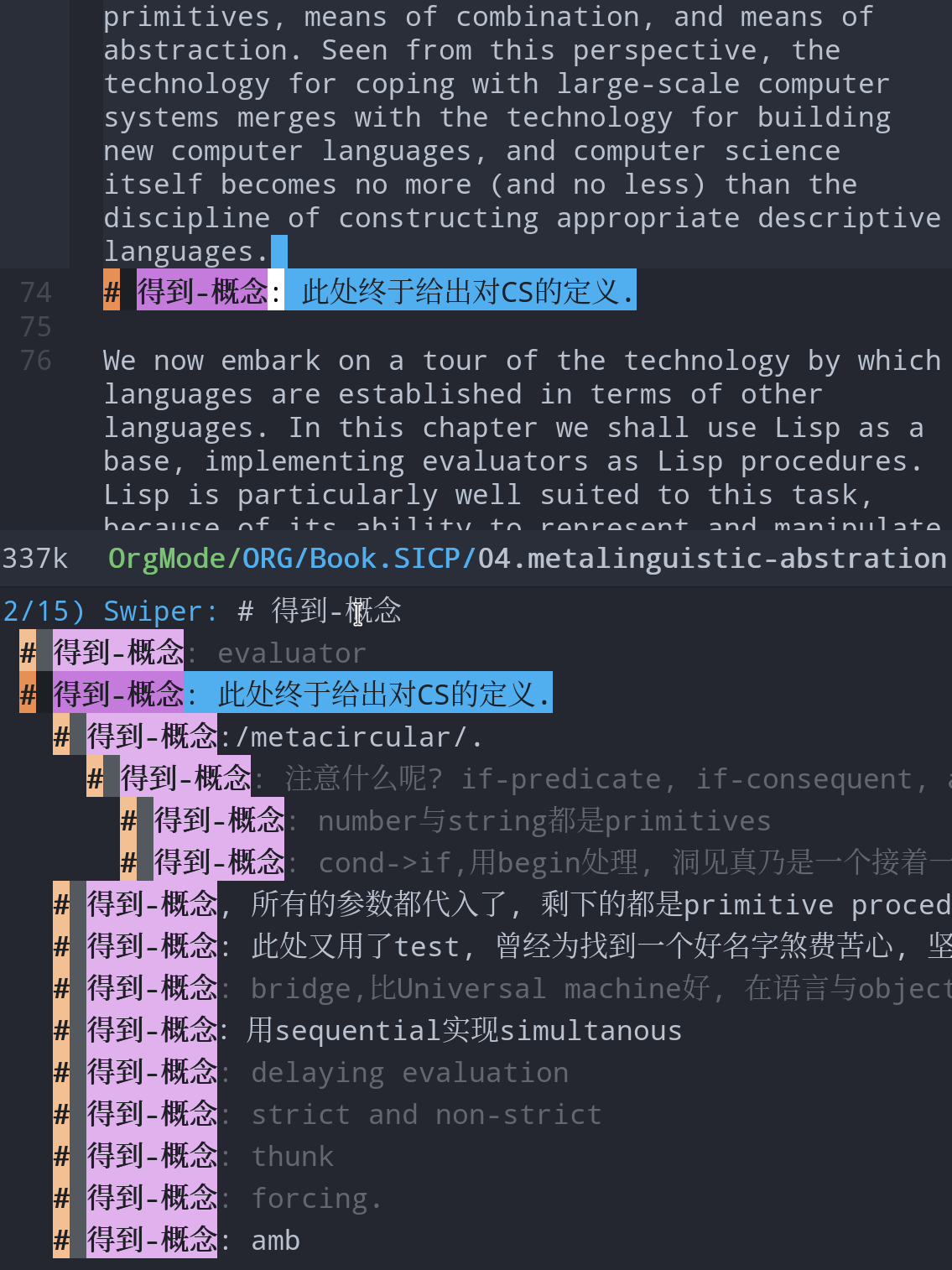
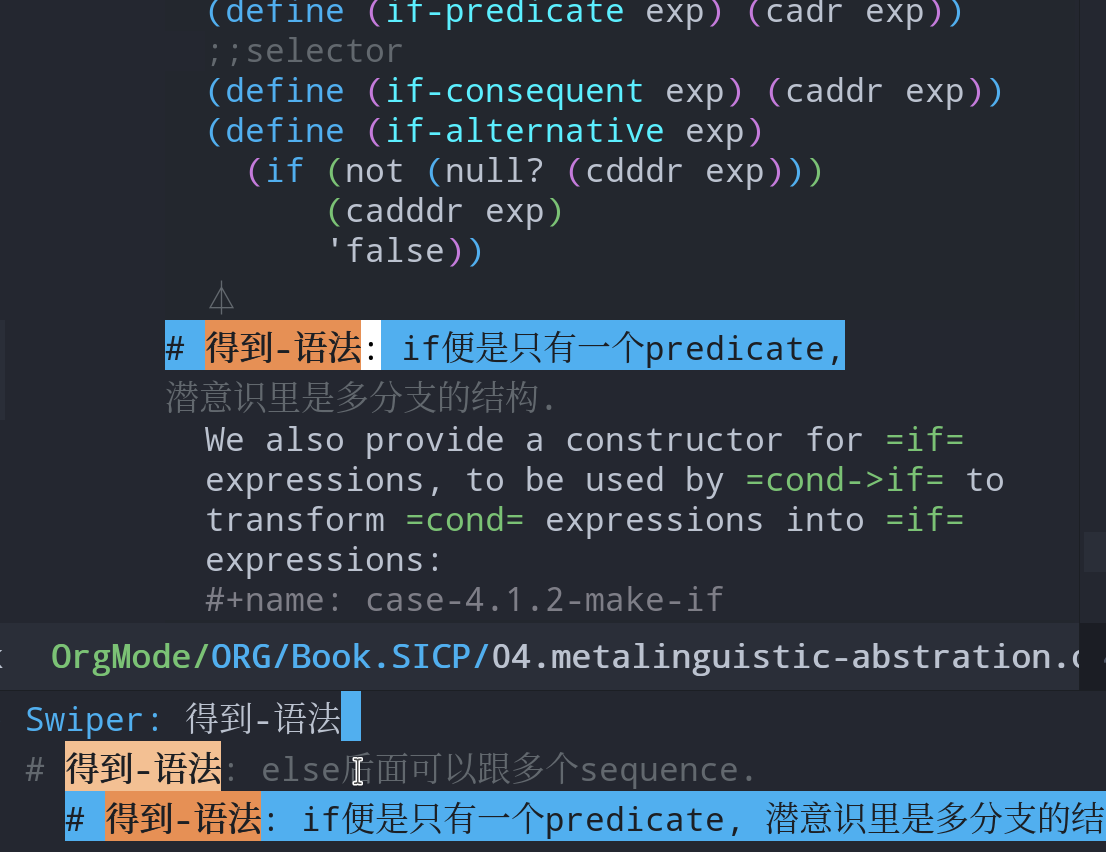
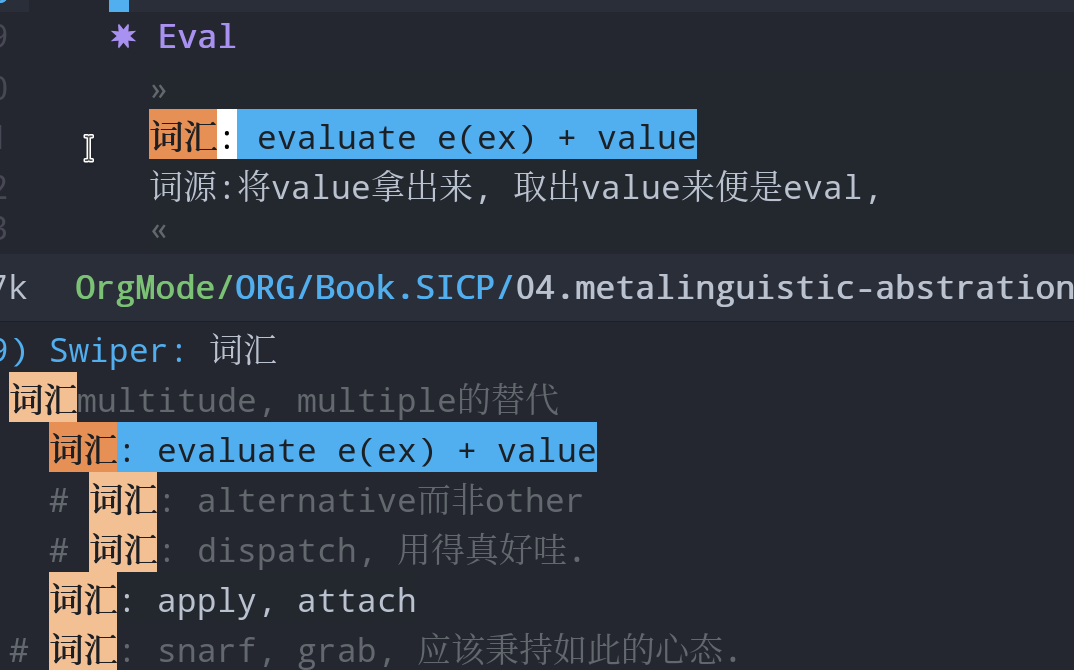
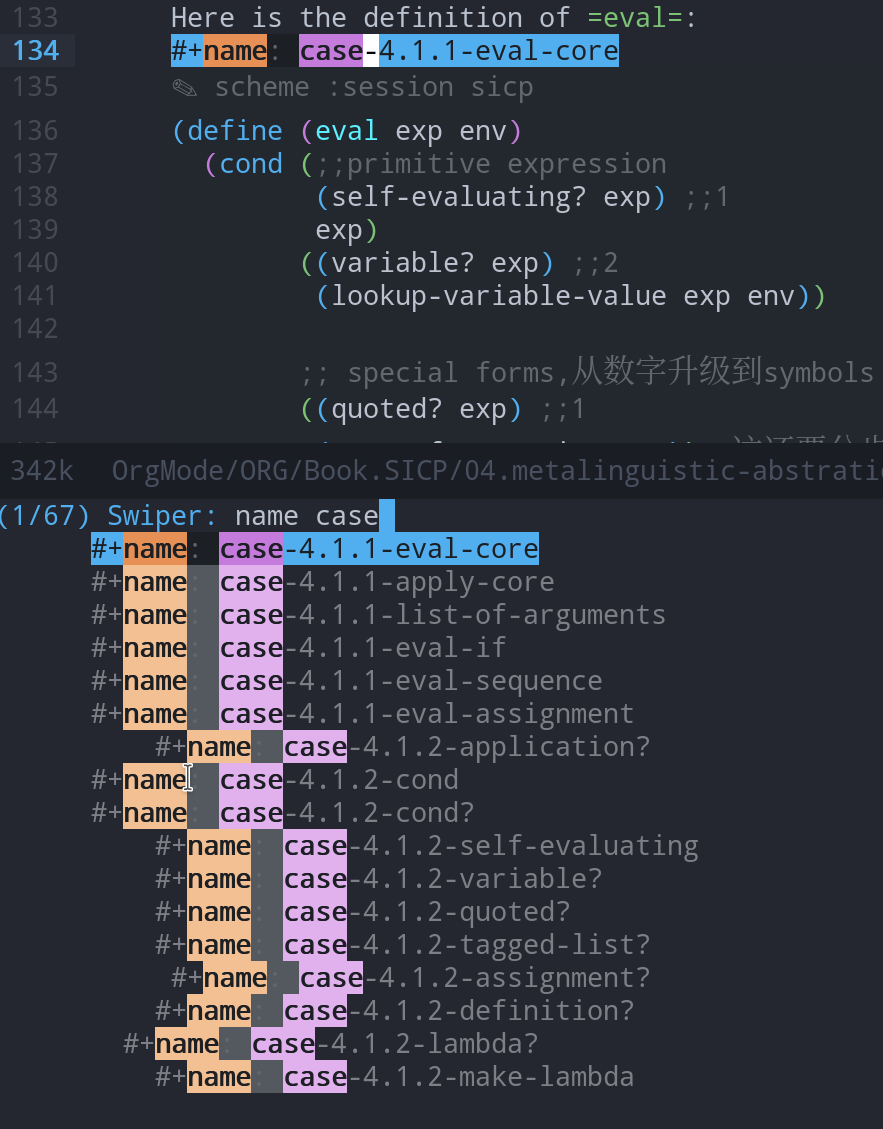
使用filter知识点的标签 #得到-概念 #得到-语法 #得到-行文(学习到了文章的结构) #得到-关联(关联到过往的经验) #得到-应用(对后续对概念对知识点应用的思);
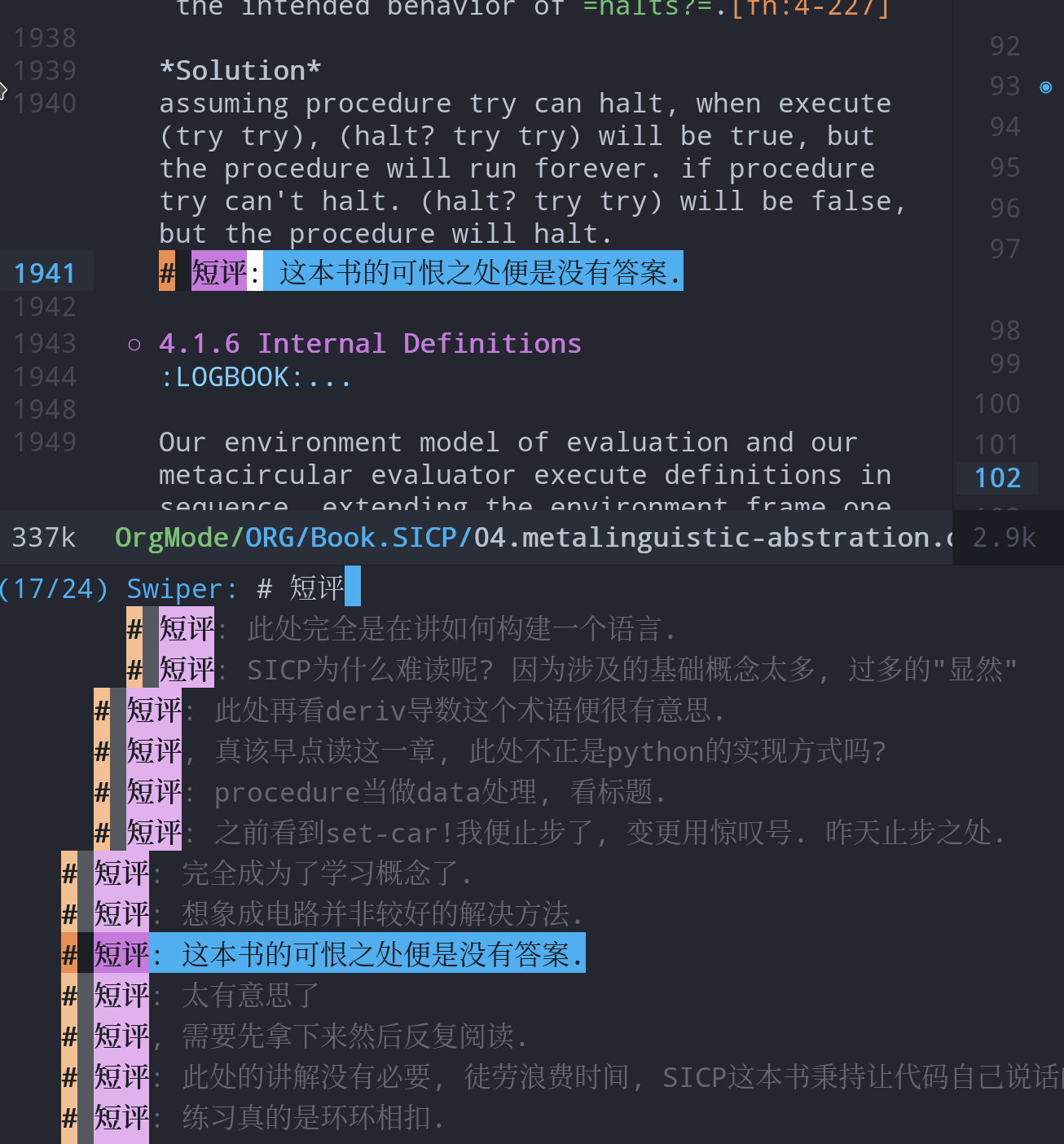
#短评(没有想好归类的,使用短评)
#洞见 #洞见-关联 #洞见-应用
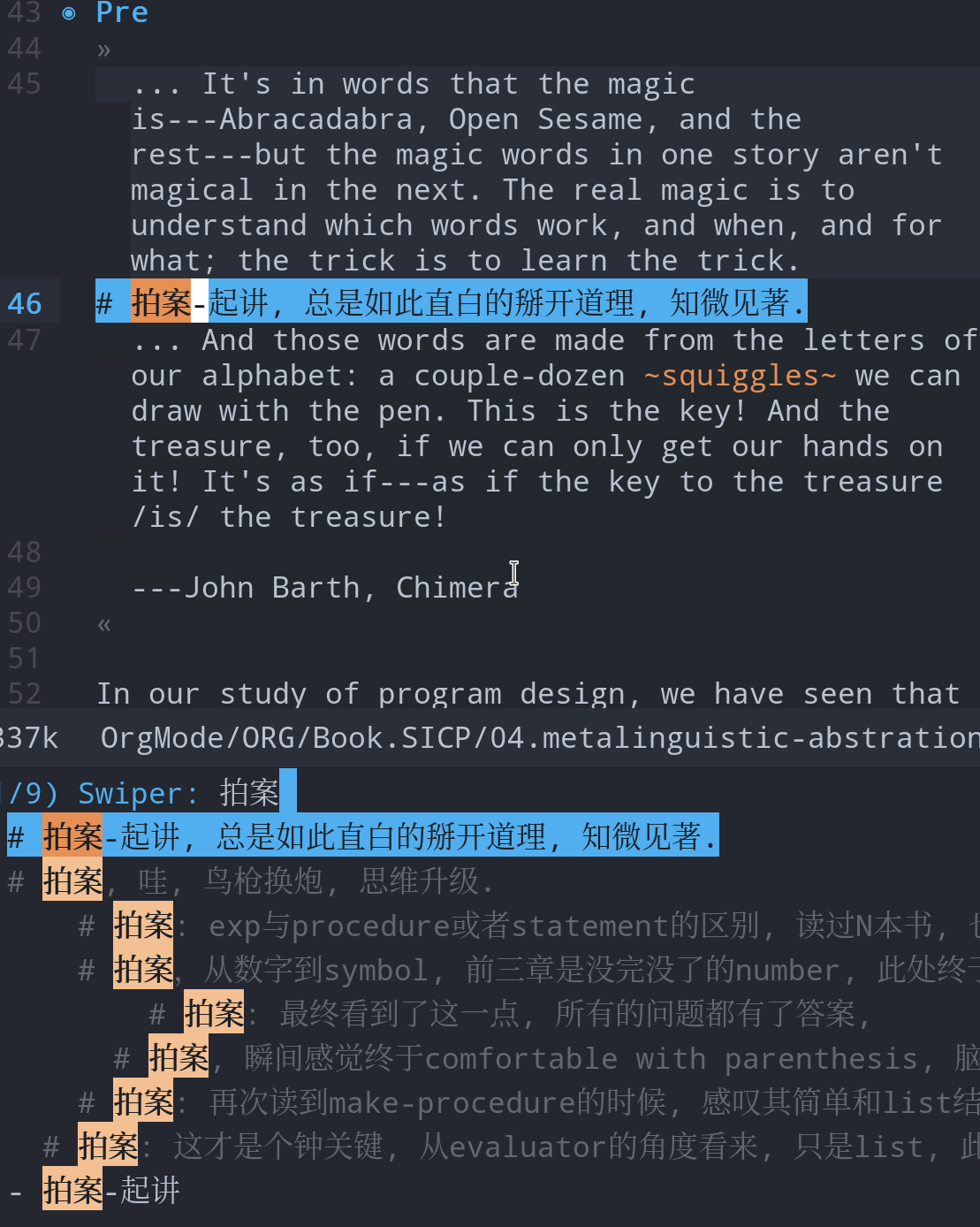
#拍案 #词汇 #总结 等等,
使用"问题?"等标签的优点:
一是: 为后续查询提供结构化的关键词
二是: 可扩展性, 一本书, 二读, 三读, 四读, 可以在既有的标签规则下, 添加新的想法.
项目:
素材: