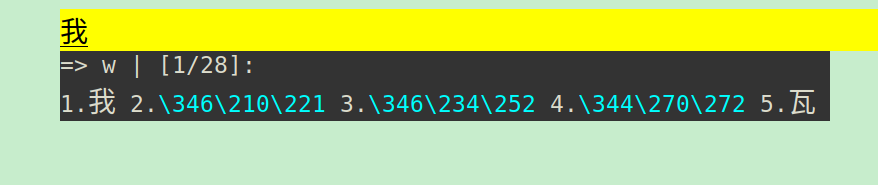
pyim 配置贴一下看看
竟然得到大佬亲自回复,感动,感谢您的劳动成果,下面是我的配置,然后大佬我还发现我在windows上使用pyim时候就不会出现提示词为乱码的情况,但是在ubuntu上用的时候就会出现
;;; init-pyim.el --- My personal Emacs configuration -*- lexical-binding: t; -*-
(use-package pyim
:ensure t)
(use-package pyim-basedict
:ensure t)
(use-package posframe
:ensure t)
(require 'pyim)
(require 'pyim-basedict)
(require 'pyim-cregexp-utils)
;; 如果使用 popup page tooltip, 就需要加载 popup 包。
(require 'popup nil t)
;; (setq pyim-page-tooltip 'popup)
;; 按照优先顺序自动选择一个可用的 tooltip
(setq pyim-page-tooltip '(posframe popup minibuffer))
;; 如果使用 pyim-dregcache dcache 后端,就需要加载 pyim-dregcache 包。
;; (require 'pyim-dregcache)
;; (setq pyim-dcache-backend 'pyim-dregcache)
;; 加载 basedict 拼音词库。
(pyim-basedict-enable)
;; 将 Emacs 默认输入法设置为 pyim.
(setq default-input-method "pyim")
;; 显示 5 个候选词。
(setq pyim-page-length 5)
;; 金手指设置,可以将光标处的编码(比如:拼音字符串)转换为中文。
(global-set-key (kbd "M-j") 'pyim-convert-string-at-point)
;; 按 "C-<return>" 将光标前的 regexp 转换为可以搜索中文的 regexp.
(define-key minibuffer-local-map (kbd "C-<return>") 'pyim-cregexp-convert-at-point)
;; 设置 pyim 默认使用的输入法策略,我使用全拼。
(pyim-default-scheme 'quanpin)
;; (pyim-default-scheme 'wubi)
;; (pyim-default-scheme 'cangjie)
;; 设置 pyim 是否使用云拼音
(setq pyim-cloudim 'google)
;; 设置 pyim 探针
;; 设置 pyim 探针设置,这是 pyim 高级功能设置,可以实现 *无痛* 中英文切换 :-)
;; 我自己使用的中英文动态切换规则是:
;; 1. 光标只有在注释里面时,才可以输入中文。
;; 2. 光标前是汉字字符时,才能输入中文。
;; 3. 使用 M-j 快捷键,强制将光标前的拼音字符串转换为中文。
;; (setq-default pyim-english-input-switch-functions
;; '(pyim-probe-dynamic-english
;; pyim-probe-isearch-mode
;; pyim-probe-program-mode
;; pyim-probe-org-structure-template))
;; (setq-default pyim-punctuation-half-width-functions
;; '(pyim-probe-punctuation-line-beginning
;; pyim-probe-punctuation-after-punctuation))
;中文使用全角标点,英文使用半角标点。
(setq-default pyim-punctuation-translate-p '(auto))
;; 开启代码搜索中文功能(比如拼音,五笔码等)
(pyim-isearch-mode 1)
;; 为 isearch 相关命令添加拼音搜索支持
(require 'pyim-cregexp-utils)
(pyim-isearch-mode 1)
;; 让 ivy 支持拼音搜索候选项功能
(require 'pyim-cregexp-utils)
(setq ivy-re-builders-alist
'((t . pyim-cregexp-ivy)))
;; 让 avy 支持拼音搜索
(with-eval-after-load 'avy
(defun my-avy--regex-candidates (fun regex &optional beg end pred group)
(let ((regex (pyim-cregexp-build regex)))
(funcall fun regex beg end pred group)))
(advice-add 'avy--regex-candidates :around #'my-avy--regex-candidates))
;; 让 vertico, selectrum 等补全框架,通过 orderless 支持拼音搜索候选项功能。
(defun my-orderless-regexp (orig-func component)
(let ((result (funcall orig-func component)))
(pyim-cregexp-build result)))
(advice-add 'orderless-regexp :around #'my-orderless-regexp)
(provide 'init-pyim)
我第一天配置好了正常用着,第二天就不行了,把词库删了pyim重装也不管用,把词库文件挨个改成utf-8也不行 ![]()
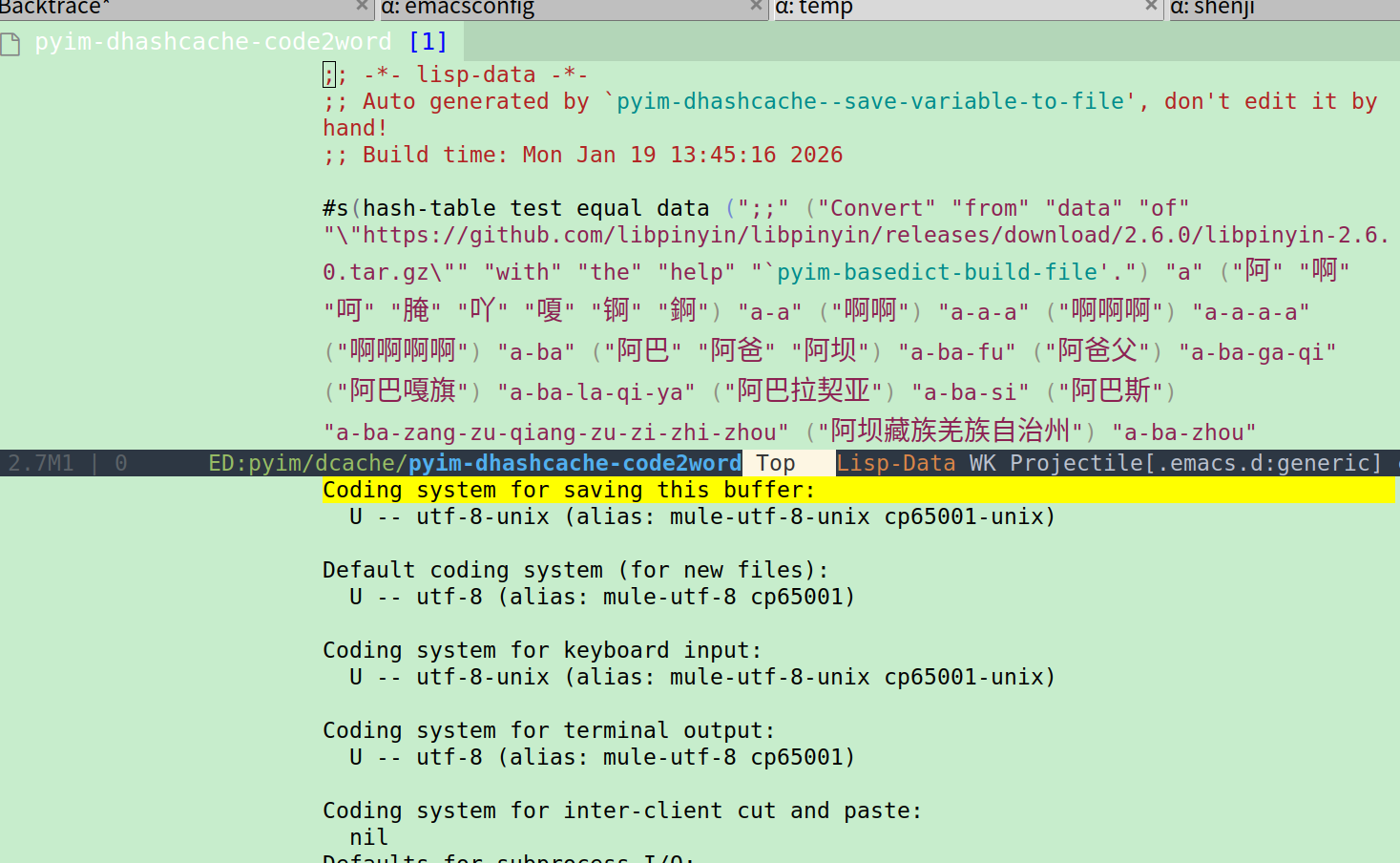
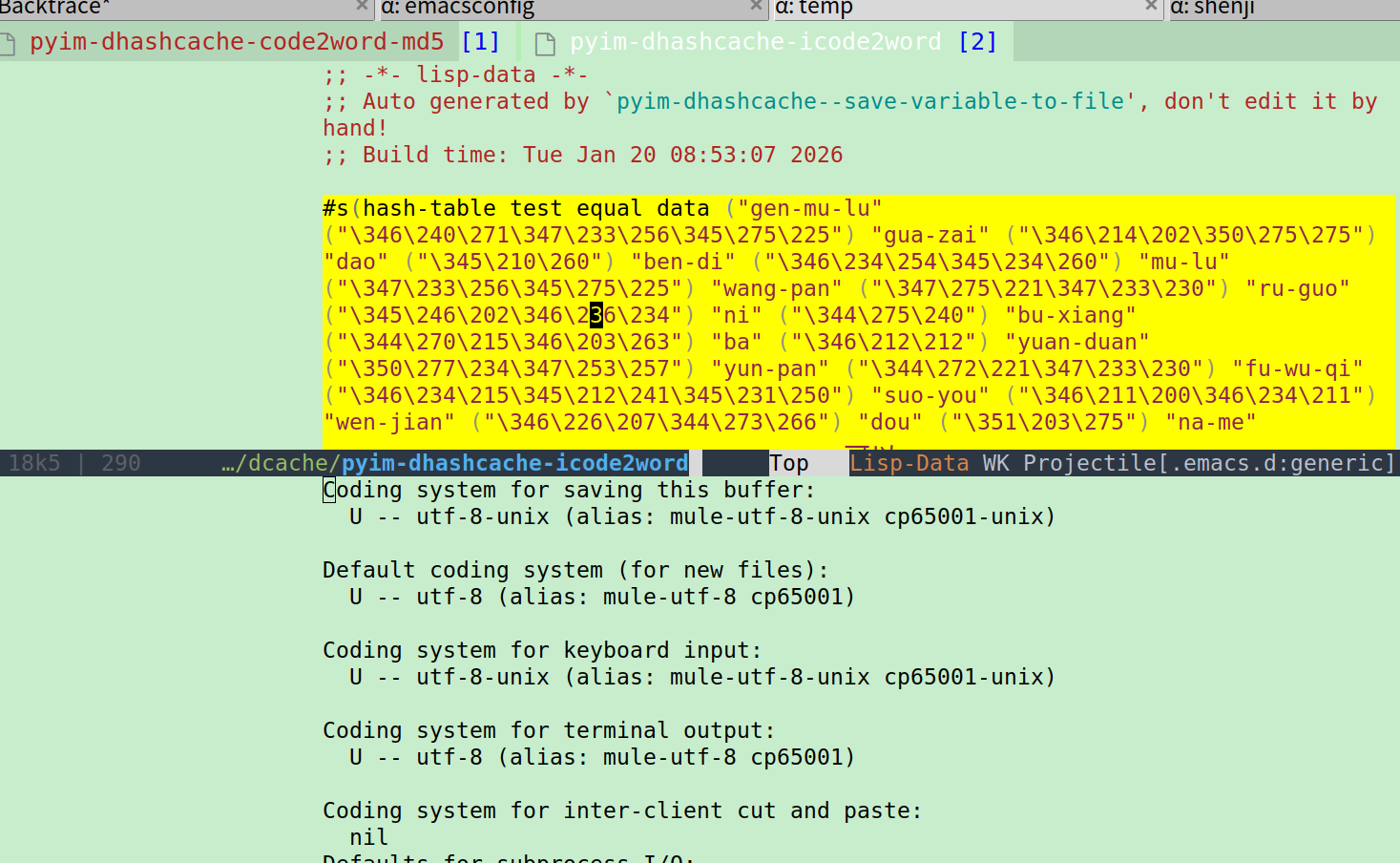
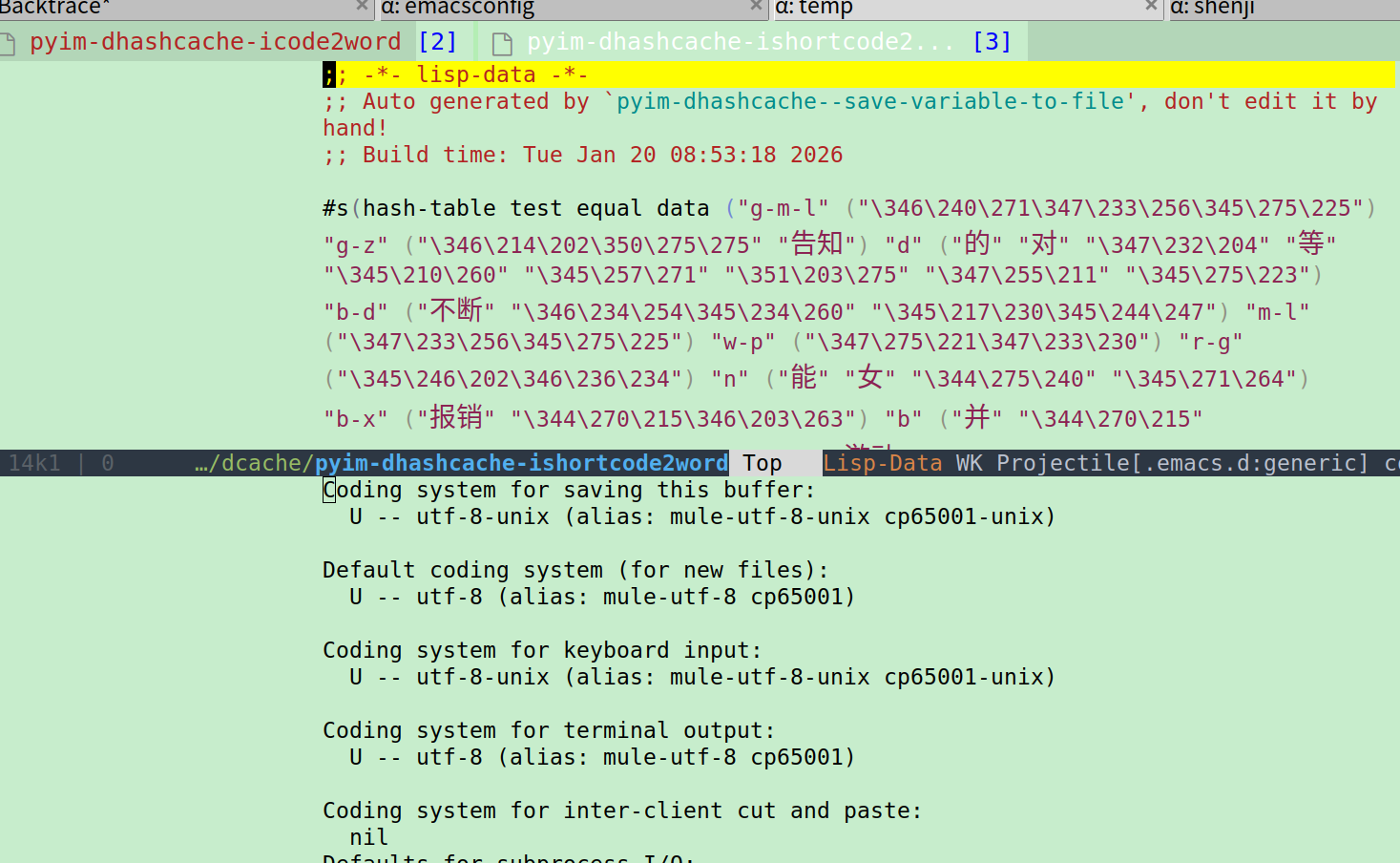
我在windows上和ubuntu上的pyim配置是一样的,但是缓存文件应该是不一样的,因为把pyim目录放到.emacs.d的.gitignore里了
把这一行去掉试试

可能是字体的问题。
可以试试这个字体: TH-Times核心说明书
linux 下 字体安装目录: ~/.fonts ; /usr/share/fonts 更新字体命令: fc-cache -v
设置字体(也可以用菜单选): (add-to-list 'default-frame-alist '(font . “TH-Tshyn-P1-16”))
或者临时试试
;; ** 设置 Charset
(set-language-environment "UTF-8")
(set-buffer-file-coding-system 'utf-8-unix)
(set-clipboard-coding-system 'utf-8-unix)
(set-file-name-coding-system 'utf-8-unix)
(set-keyboard-coding-system 'utf-8-unix)
(set-next-selection-coding-system 'utf-8-unix)
(set-selection-coding-system 'utf-8-unix)
(set-terminal-coding-system 'utf-8-unix)
(when (eq system-type 'windows-nt)
(set-language-environment "Chinese-GBK")
(set-selection-coding-system 'gbk-dos)
(set-next-selection-coding-system 'gbk-dos)
(set-clipboard-coding-system 'gbk-dos))
还是不行 ![]()
首先关闭 emacs,然后再删除 ~/.emacs.d/pyim/dcache, 再开启 emacs 试试
谢谢我试试
试过了大佬,不行 ![]() 这是最让我困惑的,我也试过手动把dcache文件夹下面的每个文件set-buffer-file-coding-system utf-8,还是不行
这是最让我困惑的,我也试过手动把dcache文件夹下面的每个文件set-buffer-file-coding-system utf-8,还是不行
关闭 emacs后再删除, emacs 有自动保存 dcache 机制
如果还不行,试试
;; 如果使用 pyim-dregcache dcache 后端,就需要加载 pyim-dregcache 包。
(require 'pyim-dregcache)
(setq pyim-dcache-backend 'pyim-dregcache)
;;; test.el --- My personal Emacs configuration -*- lexical-binding: t; -*-
(add-to-list 'load-path "/path/to/pyim")
(add-to-list 'load-path "/path/to/pyim-basedict/")
(add-to-list 'load-path "/path/to/posframe/")
(add-to-list 'load-path "/path/to/xr/")
(add-to-list 'load-path "/path/to/emacs-async/")
(require 'async)
(require 'pyim)
(require 'pyim-basedict)
(require 'pyim-cregexp-utils)
;; 如果使用 popup page tooltip, 就需要加载 popup 包。
(require 'popup nil t)
;; (setq pyim-page-tooltip 'popup)
;; 按照优先顺序自动选择一个可用的 tooltip
(setq pyim-page-tooltip '(posframe popup minibuffer))
;; 如果使用 pyim-dregcache dcache 后端,就需要加载 pyim-dregcache 包。
;; (require 'pyim-dregcache)
;; (setq pyim-dcache-backend 'pyim-dregcache)
;; 加载 basedict 拼音词库。
(pyim-basedict-enable)
;; 将 Emacs 默认输入法设置为 pyim.
(setq default-input-method "pyim")
;; 显示 5 个候选词。
(setq pyim-page-length 5)
;; 金手指设置,可以将光标处的编码(比如:拼音字符串)转换为中文。
(global-set-key (kbd "M-j") 'pyim-convert-string-at-point)
;; 按 "C-<return>" 将光标前的 regexp 转换为可以搜索中文的 regexp.
(define-key minibuffer-local-map (kbd "C-<return>") 'pyim-cregexp-convert-at-point)
;; 设置 pyim 默认使用的输入法策略,我使用全拼。
(pyim-default-scheme 'quanpin)
;; (pyim-default-scheme 'wubi)
;; (pyim-default-scheme 'cangjie)
;; 设置 pyim 是否使用云拼音
(setq pyim-cloudim 'google)
;; 设置 pyim 探针
;; 设置 pyim 探针设置,这是 pyim 高级功能设置,可以实现 *无痛* 中英文切换 :-)
;; 我自己使用的中英文动态切换规则是:
;; 1. 光标只有在注释里面时,才可以输入中文。
;; 2. 光标前是汉字字符时,才能输入中文。
;; 3. 使用 M-j 快捷键,强制将光标前的拼音字符串转换为中文。
;; (setq-default pyim-english-input-switch-functions
;; '(pyim-probe-dynamic-english
;; pyim-probe-isearch-mode
;; pyim-probe-program-mode
;; pyim-probe-org-structure-template))
;; (setq-default pyim-punctuation-half-width-functions
;; '(pyim-probe-punctuation-line-beginning
;; pyim-probe-punctuation-after-punctuation))
;中文使用全角标点,英文使用半角标点。
(setq-default pyim-punctuation-translate-p '(auto))
;; 开启代码搜索中文功能(比如拼音,五笔码等)
(pyim-isearch-mode 1)
;; 为 isearch 相关命令添加拼音搜索支持
(require 'pyim-cregexp-utils)
(pyim-isearch-mode 1)
;; 让 ivy 支持拼音搜索候选项功能
(require 'pyim-cregexp-utils)
(setq ivy-re-builders-alist
'((t . pyim-cregexp-ivy)))
;; 让 avy 支持拼音搜索
(with-eval-after-load 'avy
(defun my-avy--regex-candidates (fun regex &optional beg end pred group)
(let ((regex (pyim-cregexp-build regex)))
(funcall fun regex beg end pred group)))
(advice-add 'avy--regex-candidates :around #'my-avy--regex-candidates))
;; 让 vertico, selectrum 等补全框架,通过 orderless 支持拼音搜索候选项功能。
(defun my-orderless-regexp (orig-func component)
(let ((result (funcall orig-func component)))
(pyim-cregexp-build result)))
(advice-add 'orderless-regexp :around #'my-orderless-regexp)
你先手动下载四个项目。然后再手动测试一下
emacs -q -l test.el
我没有复现你出现的问题,不过我认为你可以先试着把其他干扰项去除掉。
这个行了大佬,这是因为啥呢
我试了老哥,emacs -l -q init-pyim.el,输入拼音还是有乱码,但是我用了pyim-dregcache当后端就不出现乱码了,我猜是不是还是缓存的词库文件编码不对,但是我曾经尝试手动把所有词库缓存文件转成utf-8,还是不行
用dregcache作后端,是不是不会使用缓存的词库文件了大佬