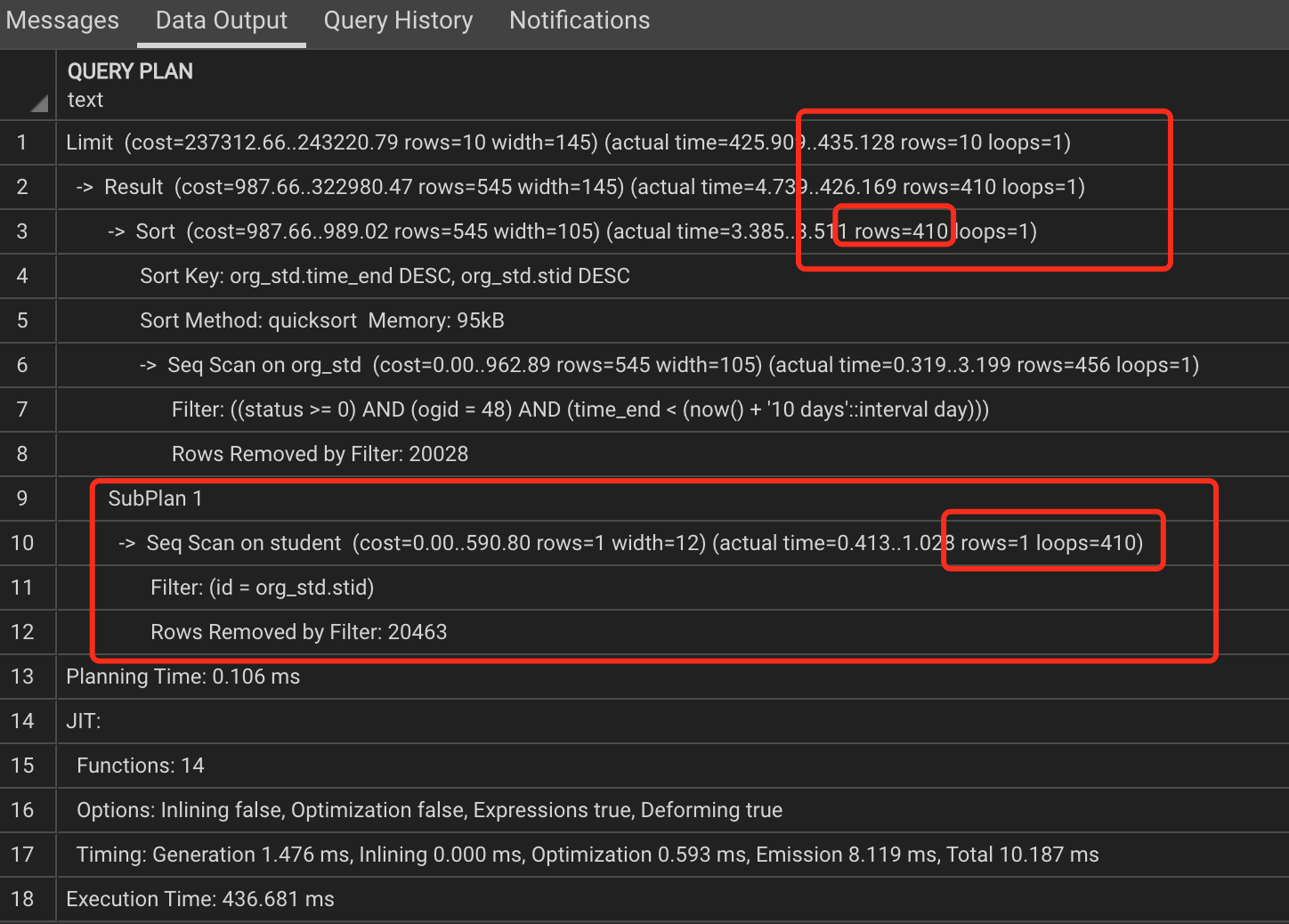
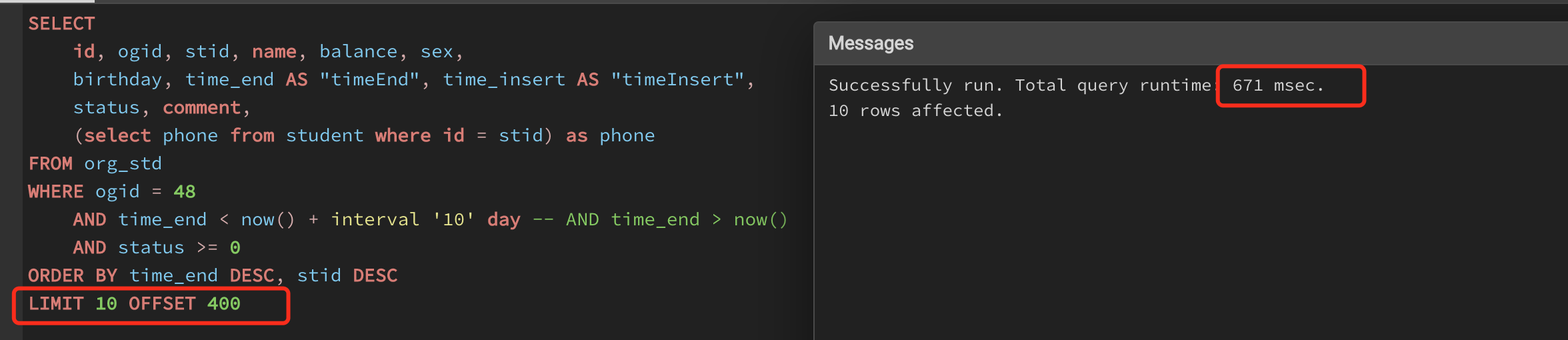
前几天有个意外的问题, 就是一个简单的 SELECT id, name, balance... 语句因为有 LIMIT...OFFSET 翻页而延迟时间差别大
例如第一页时 LIMIT 10 OFFSET 0 还是挺正常蛮快的, 但当用户翻到后面几页的时候 LIMIT 10 OFFSET 400 就慢了挺多

但是我换成先只返回id(query语句一样), 再调用一个SELECT就快了许多
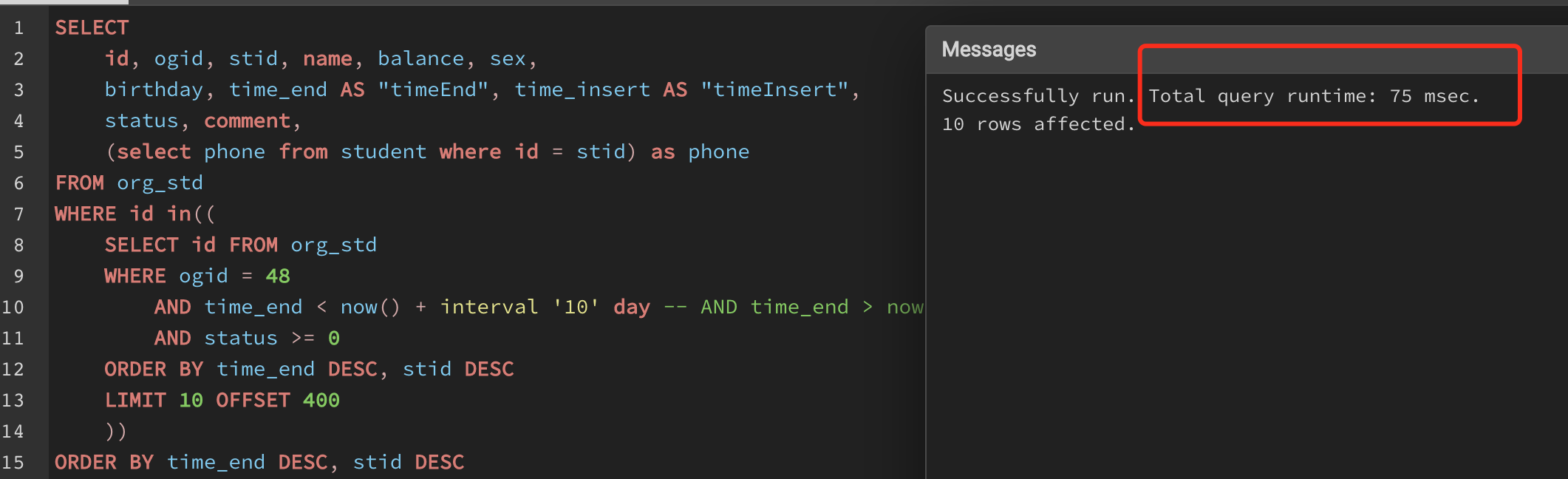
我原以为这两个在实际的运行是一样的, query不是先计算满足WHERE再去获取对应SELECT了什么吗? 看样子是先整个SELECT...WHERE...执行完再去取LIMIT...OFFSET, 取出的结果是一模一样的
从数学逻辑这二者是一模一样的(a+b=b+a) 理论上这是否可以是Postgres内部的优化选项?
[本人PostgreSQL小白]