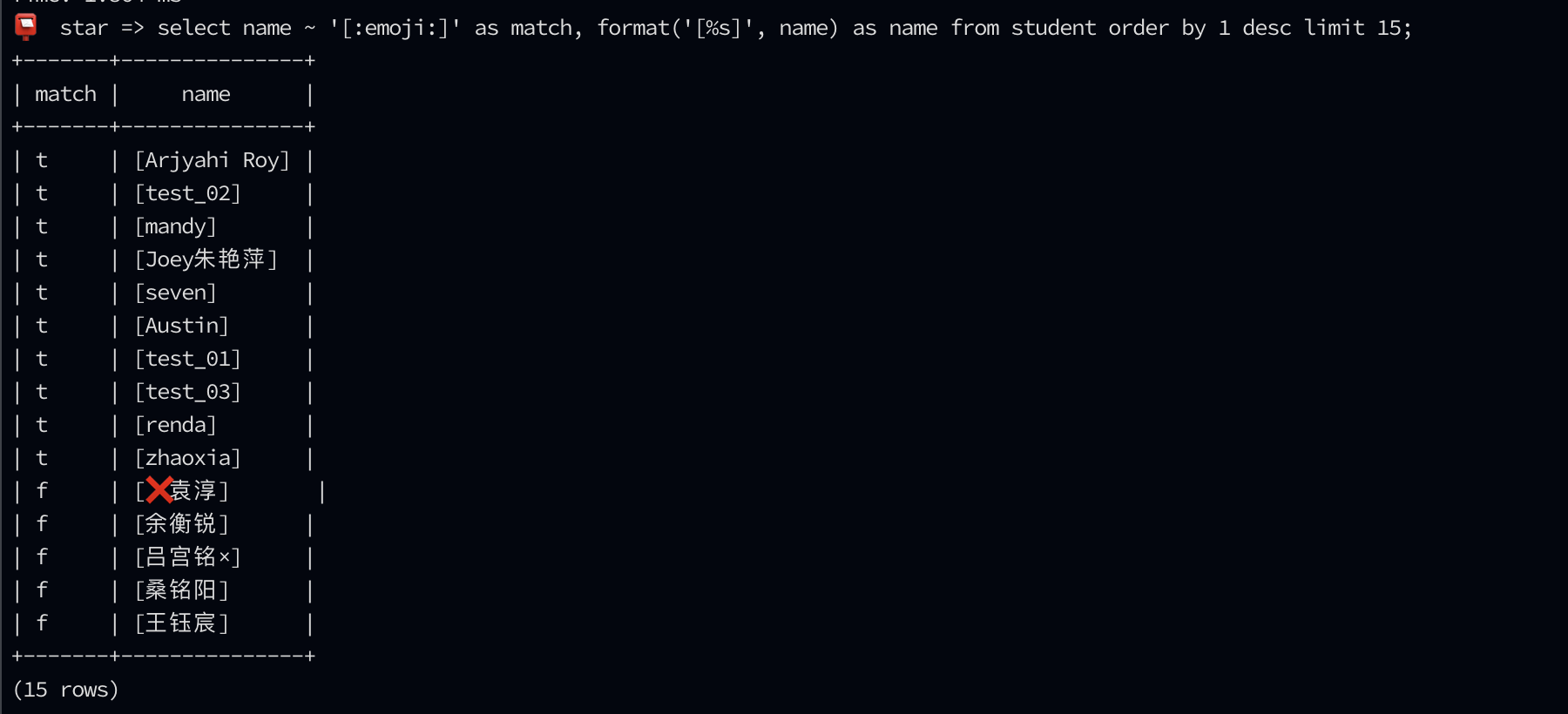
一般情况,是用
ORDER BY convert_to(name, 'GBK'))
来以中文 name排序,但是如果name包含表情符就会出错

难道说排序的时候我先把 name 的表情符先用 regexp_replace 掉吗?How?
一般情况,是用
ORDER BY convert_to(name, 'GBK'))
来以中文 name排序,但是如果name包含表情符就会出错
难道说排序的时候我先把 name 的表情符先用 regexp_replace 掉吗?How?
[:emoji:]
这是我知道的唯一相关的知识了。
我不懂编程,也不懂数据库 ![]() 正则也只是用到哪儿学到哪儿。
正则也只是用到哪儿学到哪儿。
你可以尝试换个思路:剔除非中文字符,然后再筛选。
中文字符[\u4e00-\u9fa5]、双字节字符[^\x00-\xff]
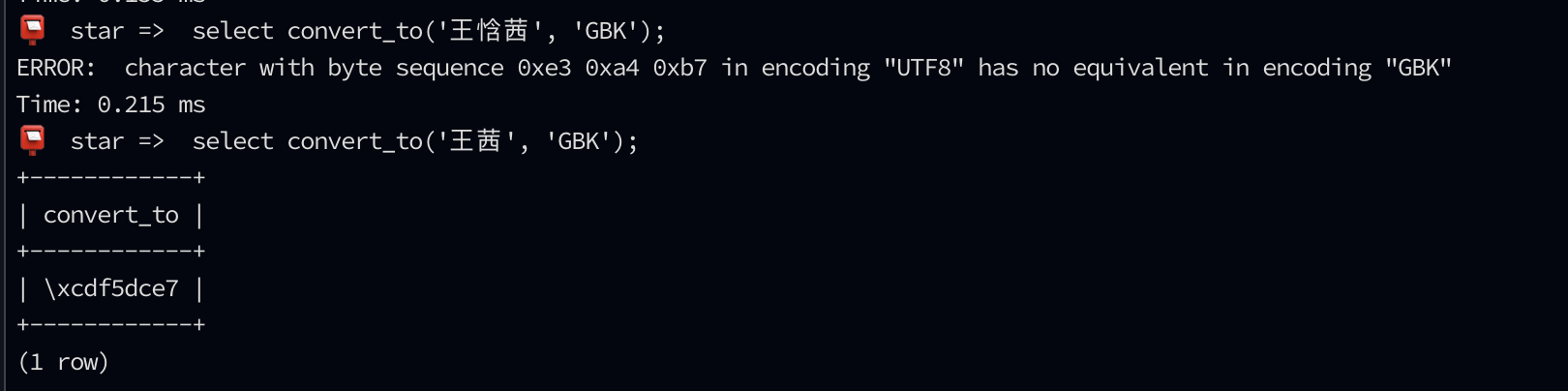
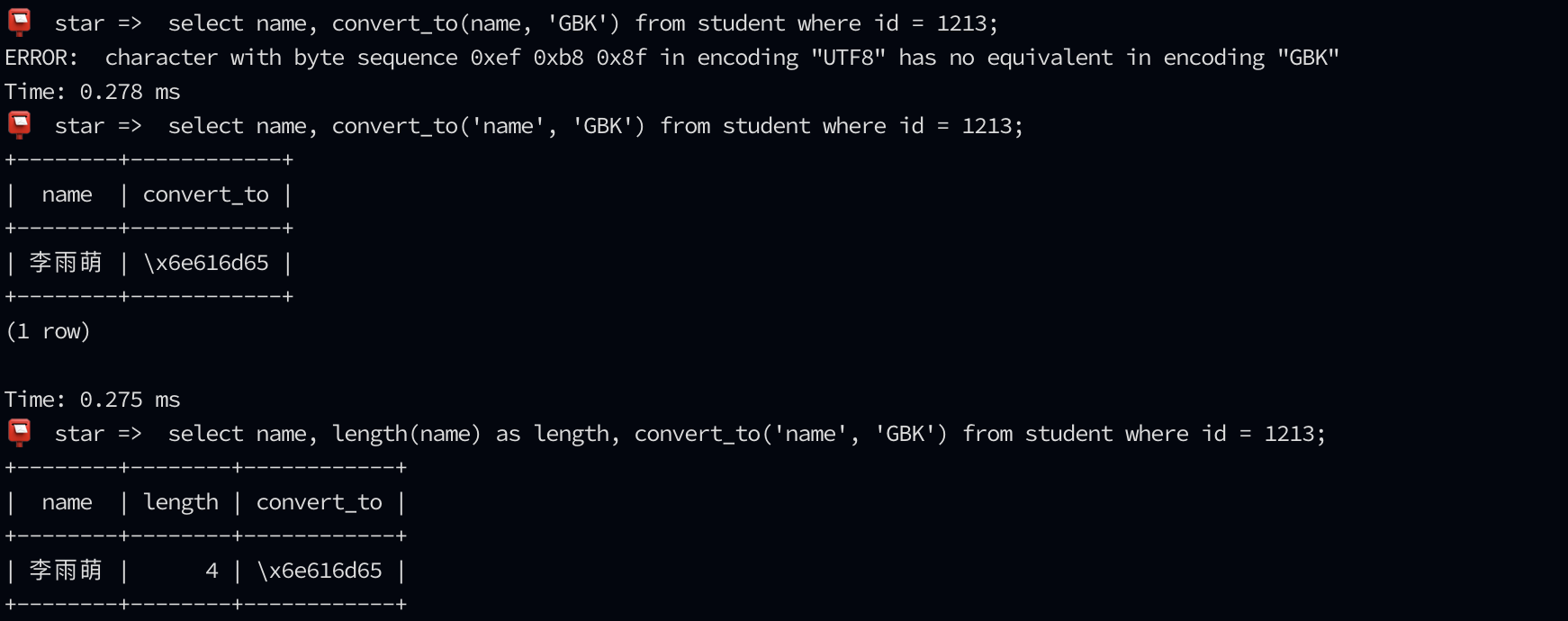
还是反向操作吧,提前把 GBK 不能覆盖的字符都剔除出去。
中文 GBK 是按拼音排序的吗?这还真不知道,哈哈。
建议别放弃,我有做过中文文件名排序的事,是用php输出目录下文件名(显示在org-mode里),但排序和windows资源管理器不一样,资源管理器是用中文拼音排序,感觉这样更合理。
不知道怎么实现拼音排序,于是就定义了一个php数组,["啊"=>"a","阿"=>"a","埃"=>"ai","挨"=>"ai","哎"=>"ai"…],把gb2312定义的一级汉字3755个都列了出来,这样中文转拼音在排序就和资源管理器差不多了。
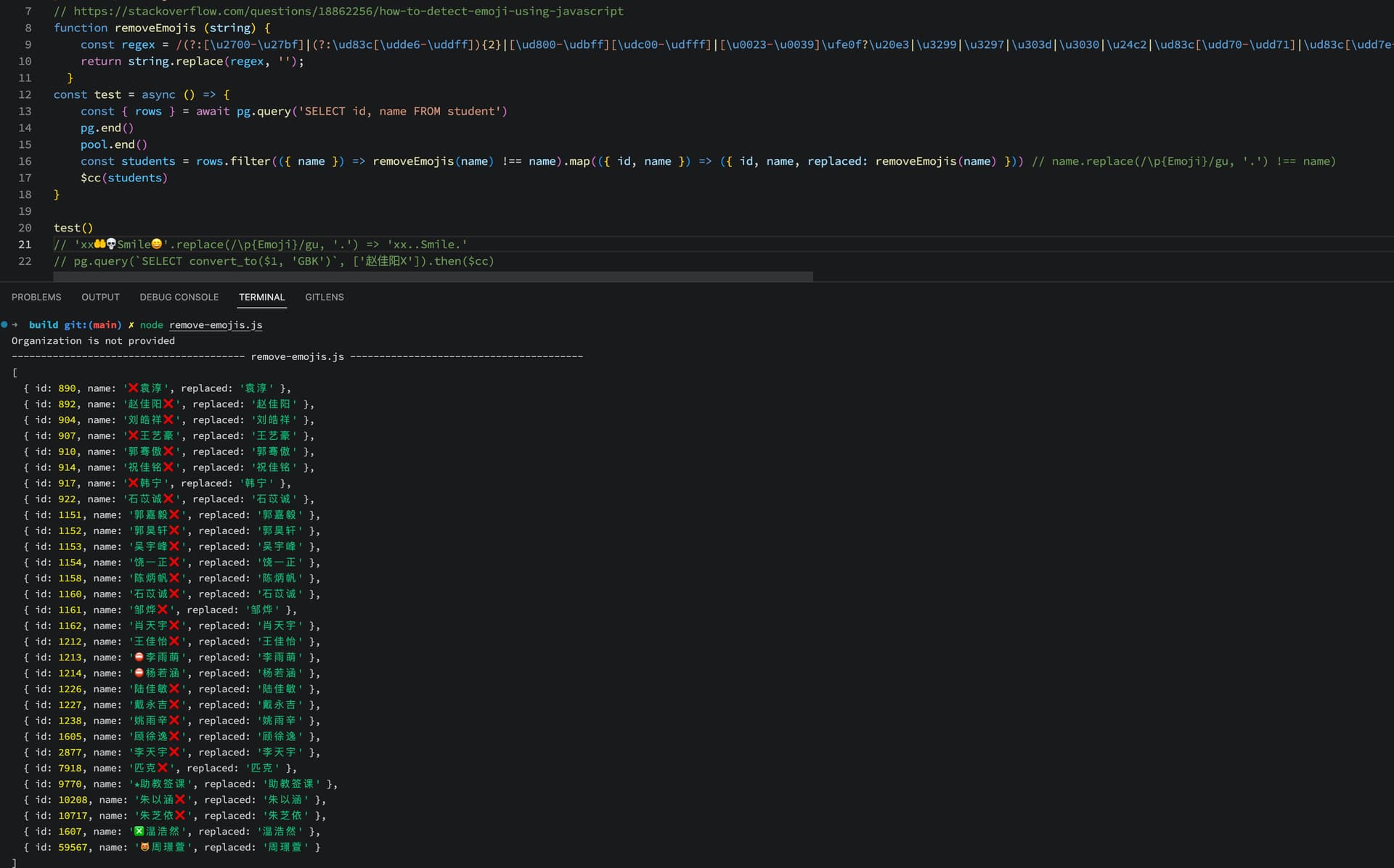
表情符不知道怎么排,但正常的文件名或人名应该很少有会用表情符号的
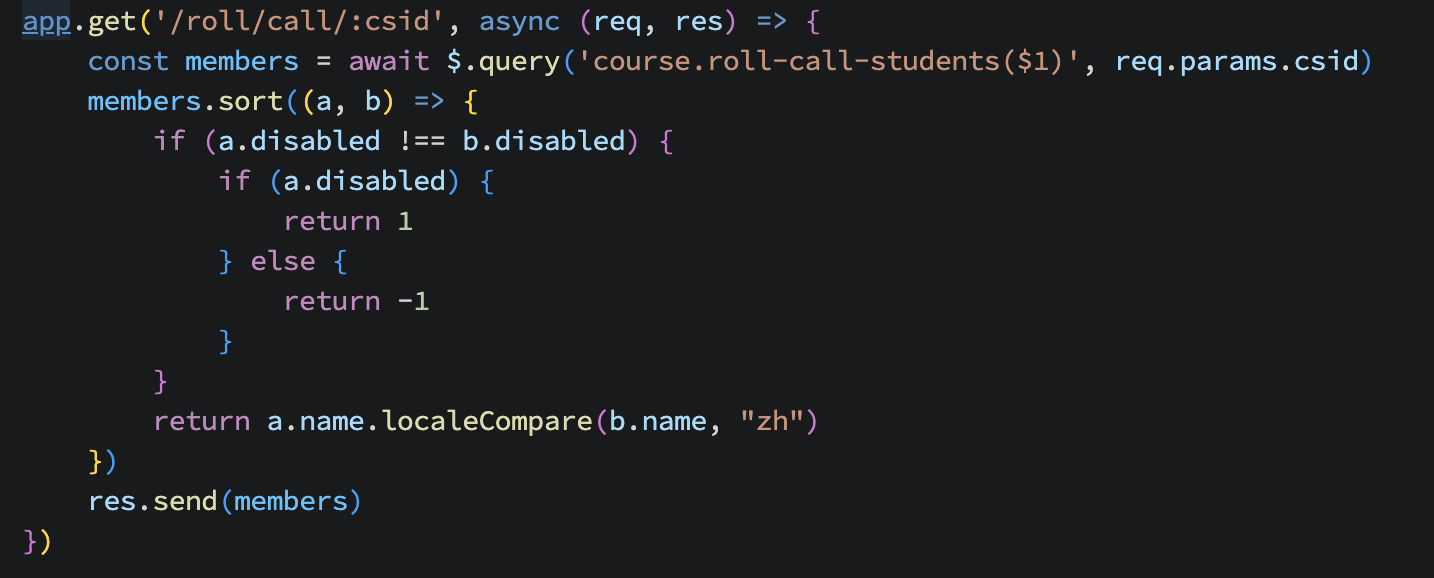
我最后是直接在获取数据后再用 node.js 去排序了(localCompare)
我现在是尽量每个请求都用Postgres的数据库函数处理,现在算是尝到了滋味,想得没错!(我在做的网站也并不算很简单,但node 的代码除去公用的函数也就两三百行,其它都用数据库的 Functions or Procedure 解决,而这个拼音排序问题解决不了所以交由JS来解决,放到前端解决也是可以的)
这个拼音排序好像比我那个一个字一个字的遍历数组转拼音排序要好得多
如果不需要处理多音字,这个其实很简单,找一个汉字转拼音的库,数据库创增加一个独立的字段保存拼音,就可以了。