新功能背景
很多人抱怨标签不好用,尤其使用一段时间后,标签数量膨胀,像多年未整理的仓库,让人失去整理动力。这种痛苦源于工具将标签视为简单标记,仅用于搜集资料,忽视层级与分类。更关键的是,工具缺乏对标签的组织和管理能力,导致数量过多时,用户陷入管理无能的困境,标签从帮手变成负担。
我在思考“标签如何更有用”时,发现标签本质上是一种集合,汇聚被标记事物的共性。例如,“工作”标签集合会议记录、任务清单和邮件,“学习”标签包括笔记、文章和视频。这种集合视角让我联想到推荐算法——大数据和AI通过为数据打标签,并挖掘标签间联系,实现精准推荐。
我想将推荐算法的机制应用于个人管理中。如果把标签视为动态集合,并赋予标签间关系,就能形成网络状结构化体系。例如:
-
“工作”与“deadline”关联,提醒任务紧急性;
-
“读书”与“笔记”形成层级,梳理学习脉络;
-
“旅行”与“预算”并列,方便规划。
这样的系统能消除标签数量膨胀带来的混乱,让用户在信息中自由切换视角。例如,面对项目,你可通过“时间”查看进度,“团队”检查分工,或“资源”评估需求。这种多维度思考是网络化标签的核心优势。
所以,我为 org-supertag 新增加了如下功能:
为标签与标签之间设定关系 org-supertag-relation-manage
在如何帮助人发现标签关系这件事上,我进一步思考,发现不少标签会添加到同一个对象上。这意味着,这这些同时出现的标签,存在着内部关系。我们可以快速通过「同现」这一关系,找到相互关联的标签。

因此,在标签关系的管理界面可以看到「Co-occurrence Tags」这一栏,可以直接看到一起出现过的标签。在我们添加标签关系时有重要的参考意义。
这里有两个小功能:
- Find By Relation,可以找到存在着关系的标签。
- Find By Relation Group,可以基于标签关系组找到存在着关系的标签。
这两点可以提供比较丰富的发现维度。
隐式发现信息结构 org-supertag-tag-discover
标签发现面板,是一种渐进式过滤的机制。可以在添加了一个标签的同时,添加另外的标签,寻找位于两个标签之间的交集里的笔记(笔记节点)。
同样,它会有 Co-occurring Tags 一栏,可以看到此间一起出现过的标签,并将它们直接添加为过滤条件,像放大镜一样,一点点变得具体。

换言之,这里存在着一种发现路径,这个发现路径将你第一次添加为过滤条件的标签,视为一个入口。如果这是一个箱庭世界,就可以通过不断添加标签,从而方便自己回顾和寻找对应的笔记。
在这个过程中,如果不断重复这一发现过程,路径本身就是结构化的象征,自然而然,在不断设计标签关系,以及发现标签的交集时,这种结构化自然地会印在脑海里。
多列对比视图 org-supertag-column
如果把标签视为集合,为了方便不同的集合之间的对比,应该以一种列状视图来表现。
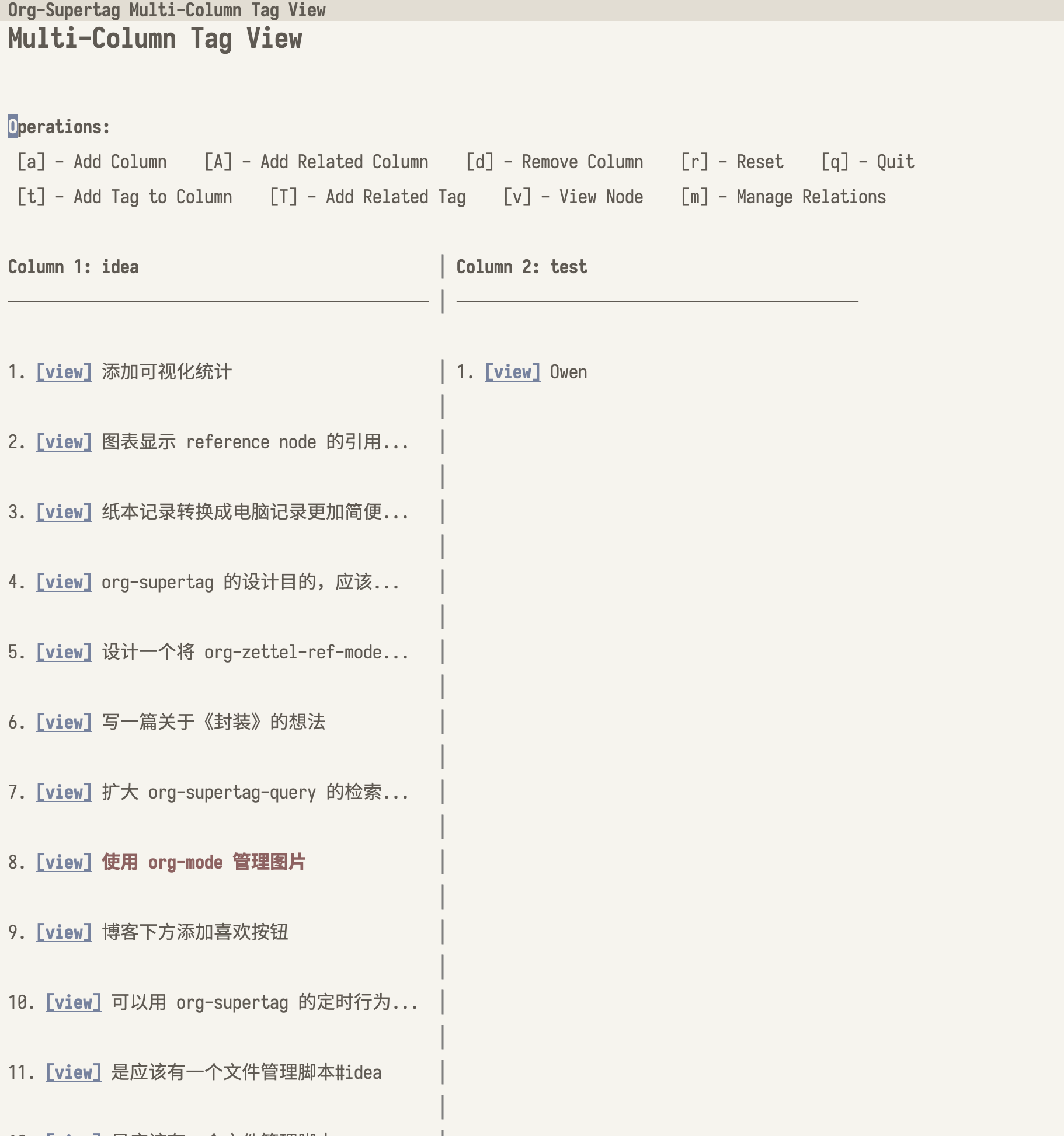
在 Multi-Colmn Tag View 中,可以快速地添加标签,进行对比,同时,还可以通过 Add Realated Tag,来将相关联的标签放在一起进行对比。
内联标签 org-supertag-inline-insert-tag
当然,将多个标签添加到同一个对象是吃力的。尤其是当前大部分工具添加标签的过程,在思考标签的时候都花了太多时间。
我提出的解决方案是,让 org-supertag 支持内联标签。让人在自然输入的过程中,直接输入标签。以 # 作为前缀。
比如:
This is a #book, named #harry_portter
这两个标签,基于「同现」的统计,可以轻易地发现,以及方便为它们添加关系。
org-supertag-inline-insert-tag 不光可以用于 heading 下方的内容,写在标题中。比如:
- This is a #book, named #harry_portter
和 org-supertag 里添加普通的标签一样,这个标签关系同样会记录。只不过不会显示为 org-tag。
目前,我在积极实践这套自己提出的想法、方法、工具。尽管记录的标签数量还不够多,但现在记录标签的积极性大大地提高了。