使用 scikit-learn 和 nltk 实现相似文件查找功能。
暂不支持中文,欢迎大佬参与开发,造福我等小白。
类似 DEVONthink 的 see also 或 Obsidian 的 graph-analysis。
安装插件之后需要先打开一个 org 文件,然后运行 M-x org-similarity-insert-list RET 安装 Python 依赖。
UPDATE 2022-12-28 01:53:39 +0800
在 hsingko 大佬和插件作者的帮助下,重新跑起来了。
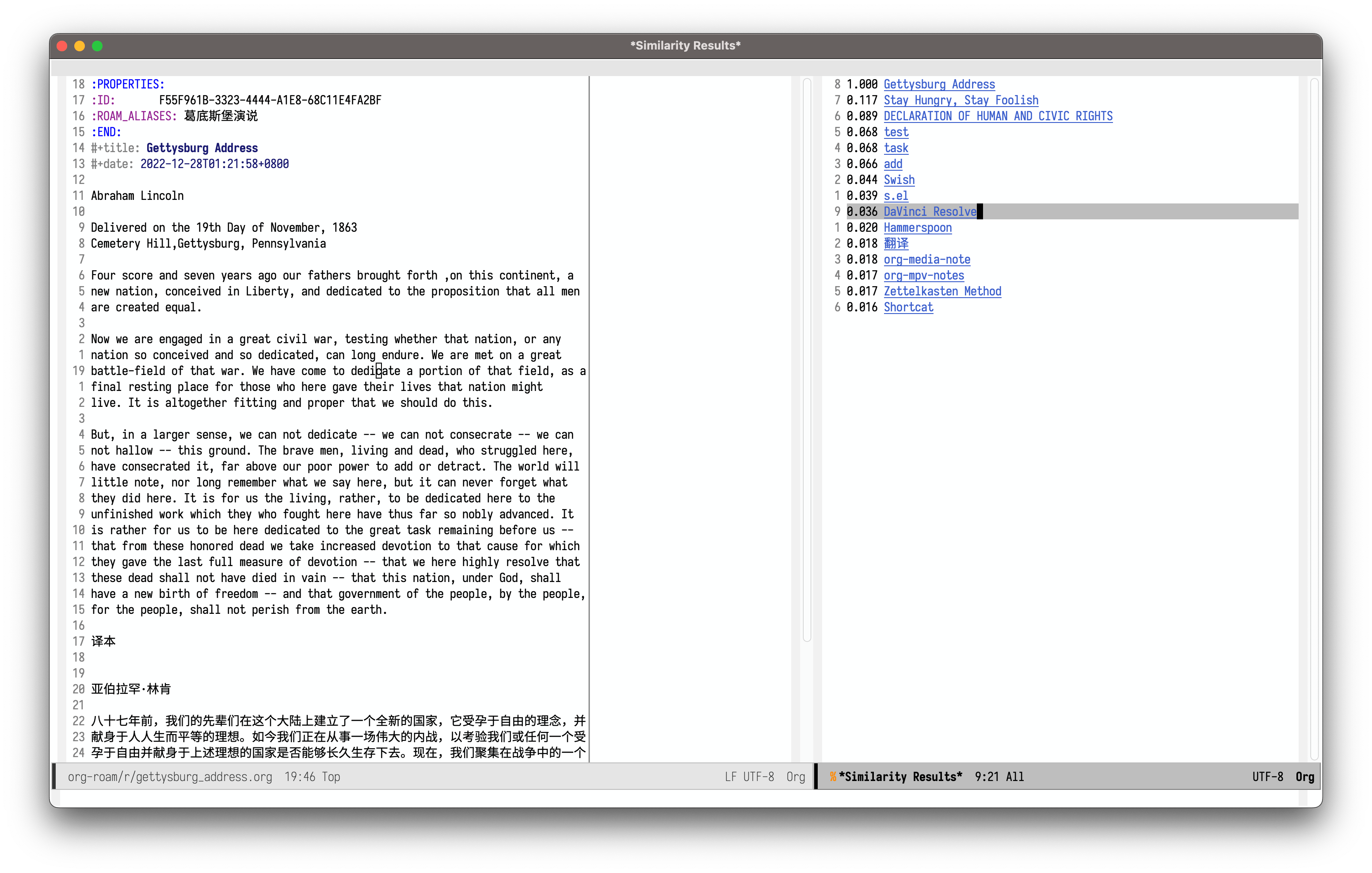
以下 bug 信息已过时,请勿参考。
不过在我电脑上 0.2 版本没跑起来,提示 UnicodeDecodeError,有没有 Python 大佬愿意帮助改进一下啊,感谢感谢 ![]()
Traceback (most recent call last):
File "/opt/homebrew/Cellar/[email protected]/3.10.9/Frameworks/Python.framework/Versions/3.10/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/opt/homebrew/Cellar/[email protected]/3.10.9/Frameworks/Python.framework/Versions/3.10/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/Users/suliveevil/.config/emacs/lib/org-similarity/venv/lib/python3.10/site-packages/orgsimilarity/__main__.py", line 257, in <module>
main()
File "/Users/suliveevil/.config/emacs/lib/org-similarity/venv/lib/python3.10/site-packages/orgsimilarity/__main__.py", line 238, in main
scores = get_scores(
File "/Users/suliveevil/.config/emacs/lib/org-similarity/venv/lib/python3.10/site-packages/orgsimilarity/__main__.py", line 157, in get_scores
documents = [
File "/Users/suliveevil/.config/emacs/lib/org-similarity/venv/lib/python3.10/site-packages/orgsimilarity/__main__.py", line 158, in <listcomp>
orgparse.load(f).get_body(format="plain") for f in target_filenames
File "/Users/suliveevil/.config/emacs/lib/org-similarity/venv/lib/python3.10/site-packages/orgparse/__init__.py", line 136, in load
lines = (l.rstrip('\n') for l in orgfile.readlines())
File "/opt/homebrew/Cellar/[email protected]/3.10.9/Frameworks/Python.framework/Versions/3.10/lib/python3.10/codecs.py", line 709, in readlines
return self.reader.readlines(sizehint)
File "/opt/homebrew/Cellar/[email protected]/3.10.9/Frameworks/Python.framework/Versions/3.10/lib/python3.10/codecs.py", line 618, in readlines
data = self.read()
File "/opt/homebrew/Cellar/[email protected]/3.10.9/Frameworks/Python.framework/Versions/3.10/lib/python3.10/codecs.py", line 504, in read
newchars, decodedbytes = self.decode(data, self.errors)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xf8 in position 18590: invalid start byte