Telegram 上群友 David 提出的原问题是这样的
从网页中往org中复制, 怎样保留源文档的超链接?
正好咱也有这个需求,就去摸了摸鱼,下面是成果:
-
首先配置好 org-protocol,这个不是这里的重点,而且也挺罗嗦的,所以这里就不说了
-
在配置好 org-protocol 的基础上,假定对应的 org-capture 模板的标识符为 w,那么添加下面这段 js 代码为浏览器书签
javascript:location.href='org-protocol://capture?template=w&url='+encodeURIComponent(location.href)+'&title='+encodeURIComponent(document.title)+'&body='+encodeURIComponent(function(){var html = "";var sel = window.getSelection();if (sel.rangeCount) {var container = document.createElement("div");for (var i = 0, len = sel.rangeCount; i < len; ++i) {container.appendChild(sel.getRangeAt(i).cloneContents());}html = container.innerHTML;}var dataDom = document.createElement('div');dataDom.innerHTML = html;dataDom.querySelectorAll('a').forEach(function(item, idx) {console.log('find a link');var url = new URL(item.href, window.location.href).href;var content = item.innerText;item.innerText = '[['+url+']['+content+']]';});['p', 'h1', 'h2', 'h3', 'h4'].forEach(function(tag, idx){dataDom.querySelectorAll(tag).forEach(function(item, index) {var content = item.innerHTML.trim();if (content.length > 0) {item.innerHTML = content + ' ';}});});return%20dataDom.innerText.trim();}())
里面其实是写了一个 js 函数来做转换,对人友好版如下:
function(){
var html = "";
var sel = window.getSelection();
if (sel.rangeCount) {
var container = document.createElement("div");
for (var i = 0, len = sel.rangeCount; i < len; ++i) {
container.appendChild(sel.getRangeAt(i).cloneContents());
}
html = container.innerHTML;
}
var dataDom = document.createElement('div');
dataDom.innerHTML = html;
dataDom.querySelectorAll('a').forEach(function(item, idx) {
console.log('find a link');
var url = new URL(item.href, window.location.href).href;
var content = item.innerText;
item.innerText = '[['+url+']['+content+']]';
});
['p', 'h1', 'h2', 'h3', 'h4'].forEach(function(tag, idx){
dataDom.querySelectorAll(tag).forEach(function(item, index) {
var content = item.innerHTML.trim();
if (content.length > 0) {
item.innerHTML = content + ' ';
}
});
});
return dataDom.innerText.trim();
}
最终效果如下
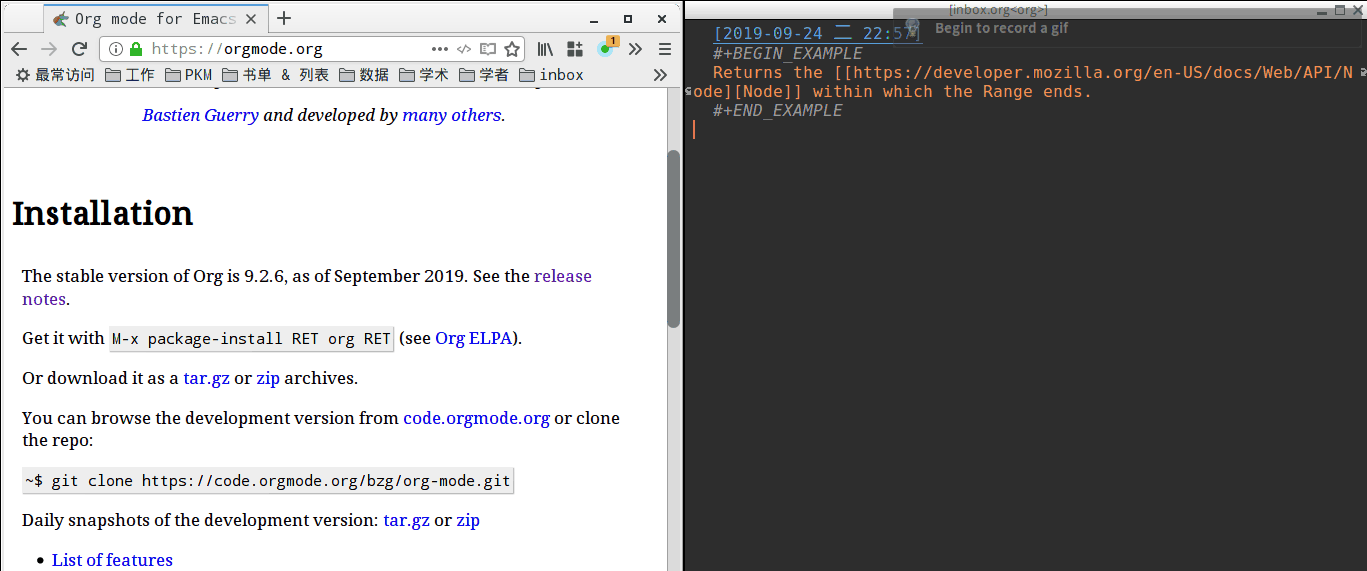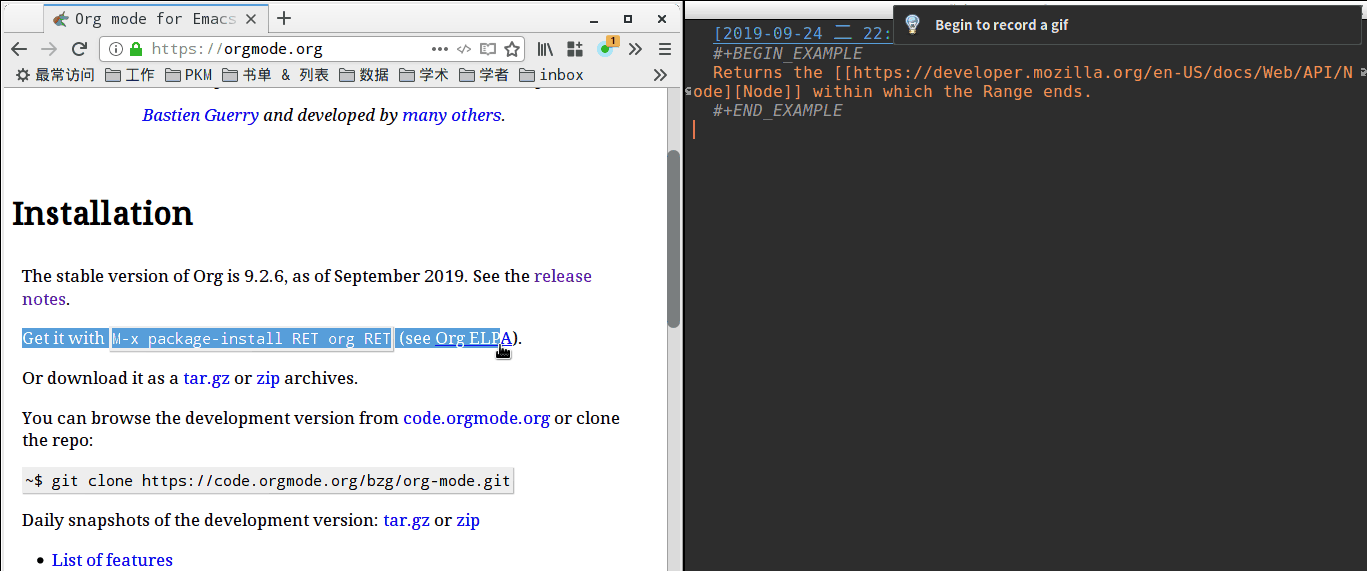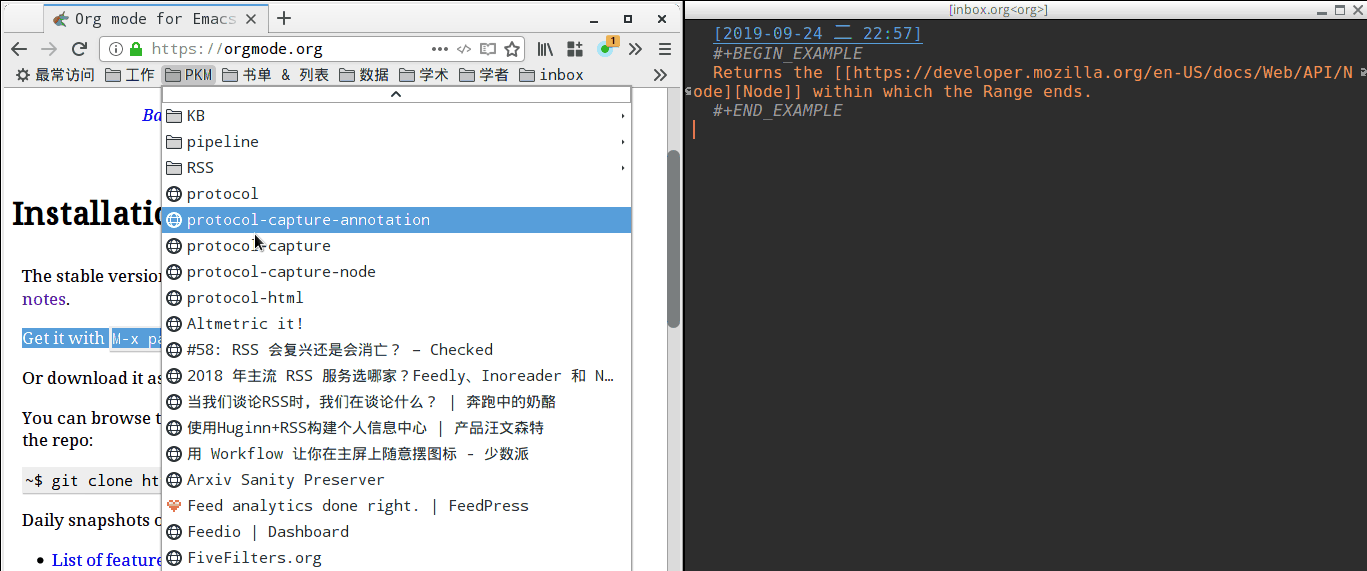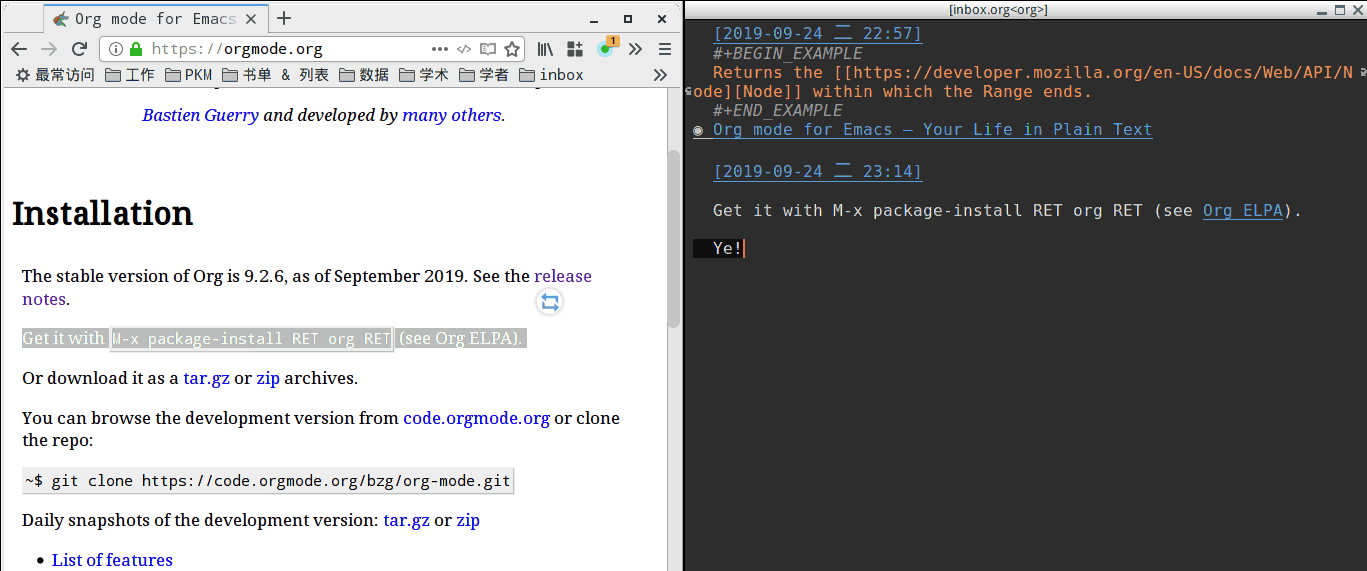
有更好的办法也欢迎交流啦~
6 个赞
今天我也刚好在配置 org-protocal
我是可以通过配置模板来实现这个功能
在模板里用 %:annotation 就可以获得原文链接
具体的你可以看看这篇文章:强大的 Org mode(4): 使用 capture 功能快速记录 · ZMonster's Blog
关键不是获得原文链接,而是获得原文正文中的链接,和这个 %:annotation 不是一回事
很多网站比如说 Google 首页(当然只是举个例子)貌似换成你的 Javascript 就无法抓取了,
用这个简单的可以
javascript:location.href='org-protocol://capture?template=l&url='+encodeURIComponent(location.href)+'&title='+encodeURIComponent(document.title%20%7C%7C%20%22%5Buntitled%20page%5D%22)+'&body='+encodeURIComponent(window.getSelection())
1 个赞
我最早的时候就是这样的,但这个没法保留选中区域中的链接。
在 Google 首页不生效是因为我抄的代码里用了 jQuery 的语法,如果网页不支持 jQuery 就会失败,我也是这两天才发现这个问题。
已经把 js 代码改成原生的了,不妨再看下。
1 个赞
说到这个,现在用 org-protocol 每次 chrome 都会提示要不要用 emacs 打开,我记得之前可以选择始终使用 emacs 打开的
有哪位道友知道怎么默认emacs打开吗?
zhua
12
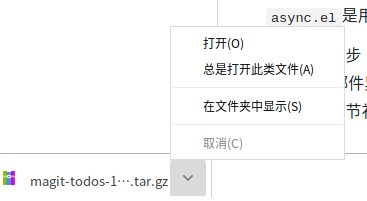
我也不敢确定, 好像是文件在第一次, 下载后,
在左下角下完的这里, 这个文件有个
向下的箭头, 单击, 选中"总是打开此类文件"
不知道你是什么os,回答中linux的方法有效。设置完后下次再用就会有选择不再提示的选项。
一行版本用的 encodeURIComponent 会对部分字符保留(!, ', (, ), *)),导致对于一些网站失效,比如说 Why We Think | Lil'Log
用 URLSearchParams 修改了一版
javascript:(function() {
const selectedText = (function() {
var html = "";
var sel = window.getSelection();
if (sel.rangeCount) {
var container = document.createElement("div");
for (var i = 0, len = sel.rangeCount; i < len; ++i) {
container.appendChild(sel.getRangeAt(i).cloneContents());
}
html = container.innerHTML;
}
var dataDom = document.createElement('div');
dataDom.innerHTML = html;
dataDom.querySelectorAll('a').forEach(function(item, idx) {
console.log('find a link');
var url = new URL(item.href, window.location.href).href;
var content = item.innerText;
item.innerText = '[['+url+']['+content+']]';
});
['p', 'h1', 'h2', 'h3', 'h4'].forEach(function(tag, idx) {
dataDom.querySelectorAll(tag).forEach(function(item, index) {
var content = item.innerHTML.trim();
if (content.length > 0) {
item.innerHTML = content + ' ';
}
});
});
return dataDom.innerText.trim();
})();
const params = new URLSearchParams({
template: "w",
url: location.href,
title: document.title || "UNTITLED PAGE",
body: selectedText
});
location.href = 'org-protocol://capture?' + params.toString();
})();
单行书签版
javascript:(function(){const selectedText=(function(){var html="";var sel=window.getSelection();if(sel.rangeCount){var container=document.createElement("div");for(var i=0,len=sel.rangeCount;i<len;++i){container.appendChild(sel.getRangeAt(i).cloneContents());}html=container.innerHTML;}var dataDom=document.createElement('div');dataDom.innerHTML=html;dataDom.querySelectorAll('a').forEach(function(item,idx){console.log('find a link');var url=new URL(item.href,window.location.href).href;var content=item.innerText;item.innerText='[['+url+']['+content+']]';});['p','h1','h2','h3','h4'].forEach(function(tag,idx){dataDom.querySelectorAll(tag).forEach(function(item,index){var content=item.innerHTML.trim();if(content.length>0){item.innerHTML=content+' ';}});});return dataDom.innerText.trim();})();const params=new URLSearchParams({template:"w",url:location.href,title:document.title||"UNTITLED PAGE",body:selectedText});location.href='org-protocol://capture?'+params.toString();})();
相关帖子
1 个赞

 哈哈,理解错了。
没想到引用的也是大佬的文章啊
哈哈,理解错了。
没想到引用的也是大佬的文章啊