利用org-protocol-capture-html和org-protocol插件实现在Web上截取笔记。 但每次利用capture中文后总让我选择coding system.
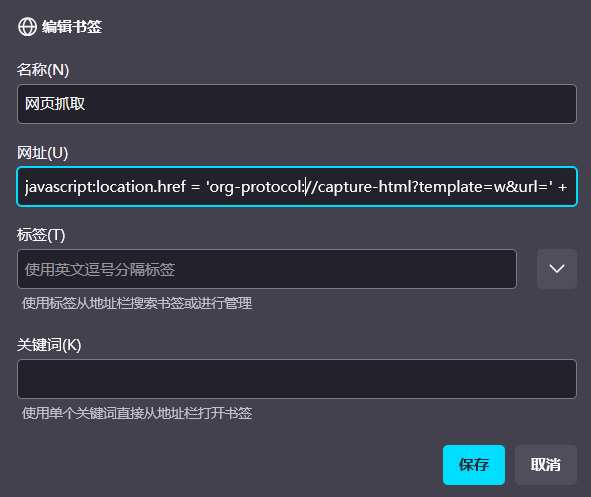
capture 用小书签来实现
 选中Web上的一些中文文字
选中Web上的一些中文文字预先格式化的文本后,capture,弹出select coding system
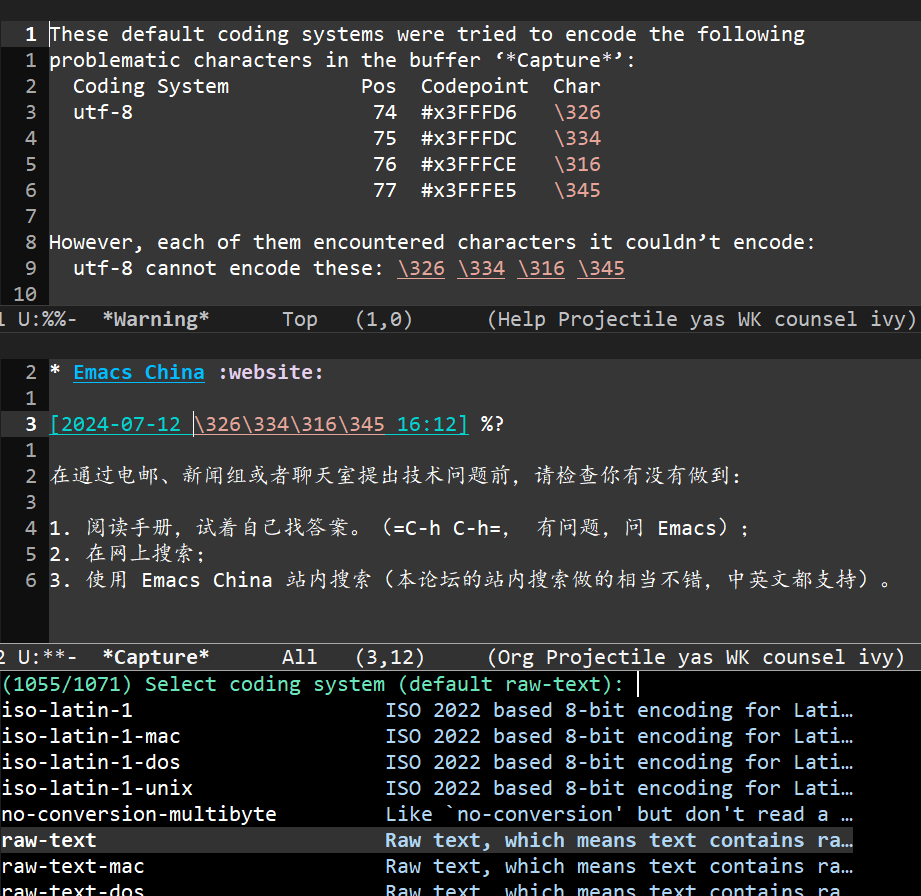
我想默认utf-8且不再弹出select coding system,请教一下该如何实现
利用org-protocol-capture-html和org-protocol插件实现在Web上截取笔记。 但每次利用capture中文后总让我选择coding system.
capture 用小书签来实现
选中Web上的一些中文文字预先格式化的文本后,capture,弹出select coding system
我想默认utf-8且不再弹出select coding system,请教一下该如何实现
同,甚至捕获之后选择UTF-8后依旧乱码
我用的这个插件,没啥问题
没啥问题,就是capture中文时需要选择一下utf-8 coding,嫌麻烦
我用的是Win10系统,一开始也是乱码一片。
后来在《电脑爱好者》杂志里面看到了这个,可以在 控制面板\时钟和区域-区域-管理-更改系统区域设置(管理员)中,勾选Beta版:使用Unicode UTF-8 提供全球语言支持(U). 然后就没有任何乱码了。
当然不用Win10系统的我就不知道怎么办了 ![]()