【更新】目前尝试用 Zotero 来代替 Calibre,同时用 Bibtex 记录来保证笔记的引用,用 Org-noter 来找回引用的原始资料和上下文。
相关设置的参考这位数学博士的做法:金色飞贼小米的个人空间-金色飞贼小米个人主页-哔哩哔哩视频
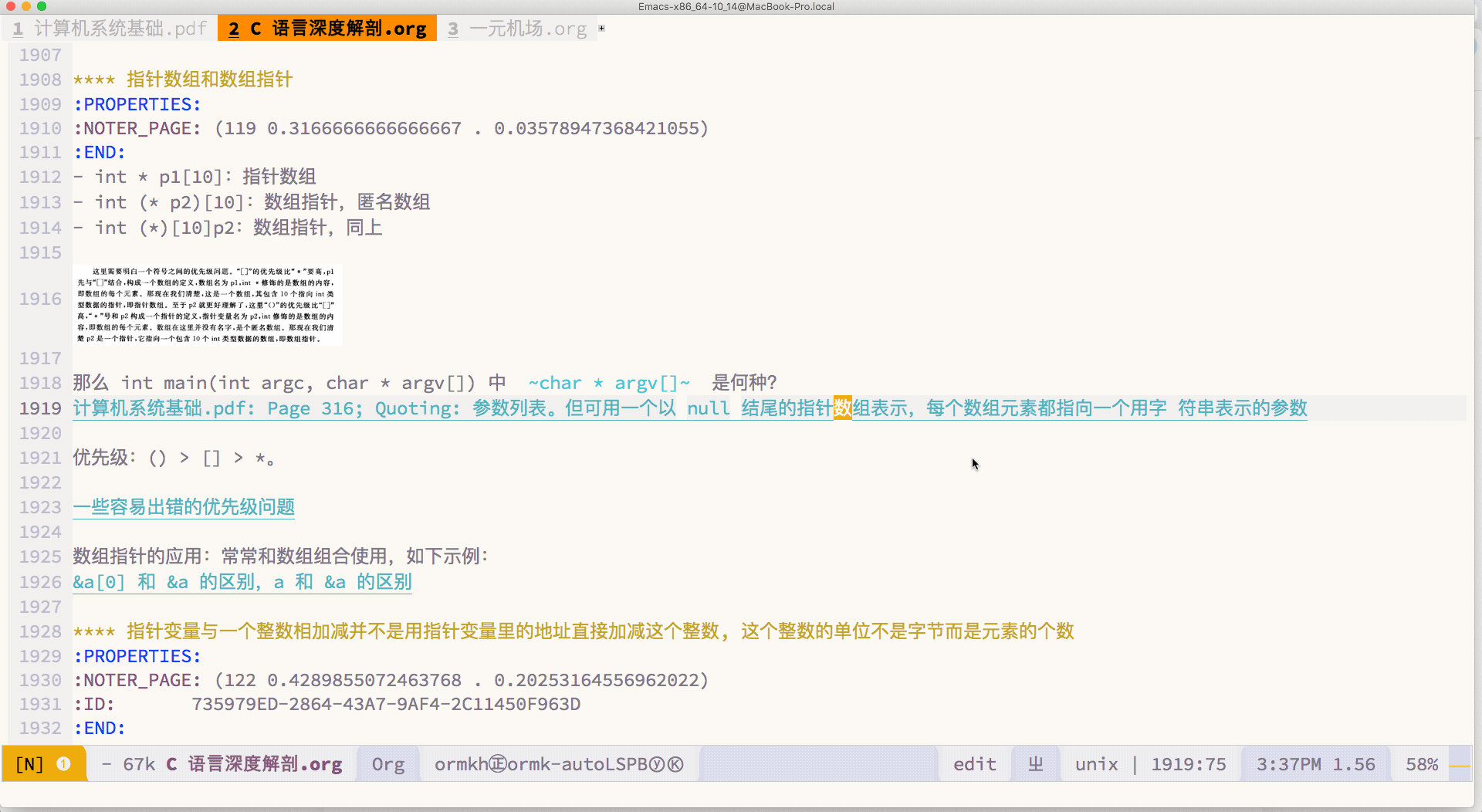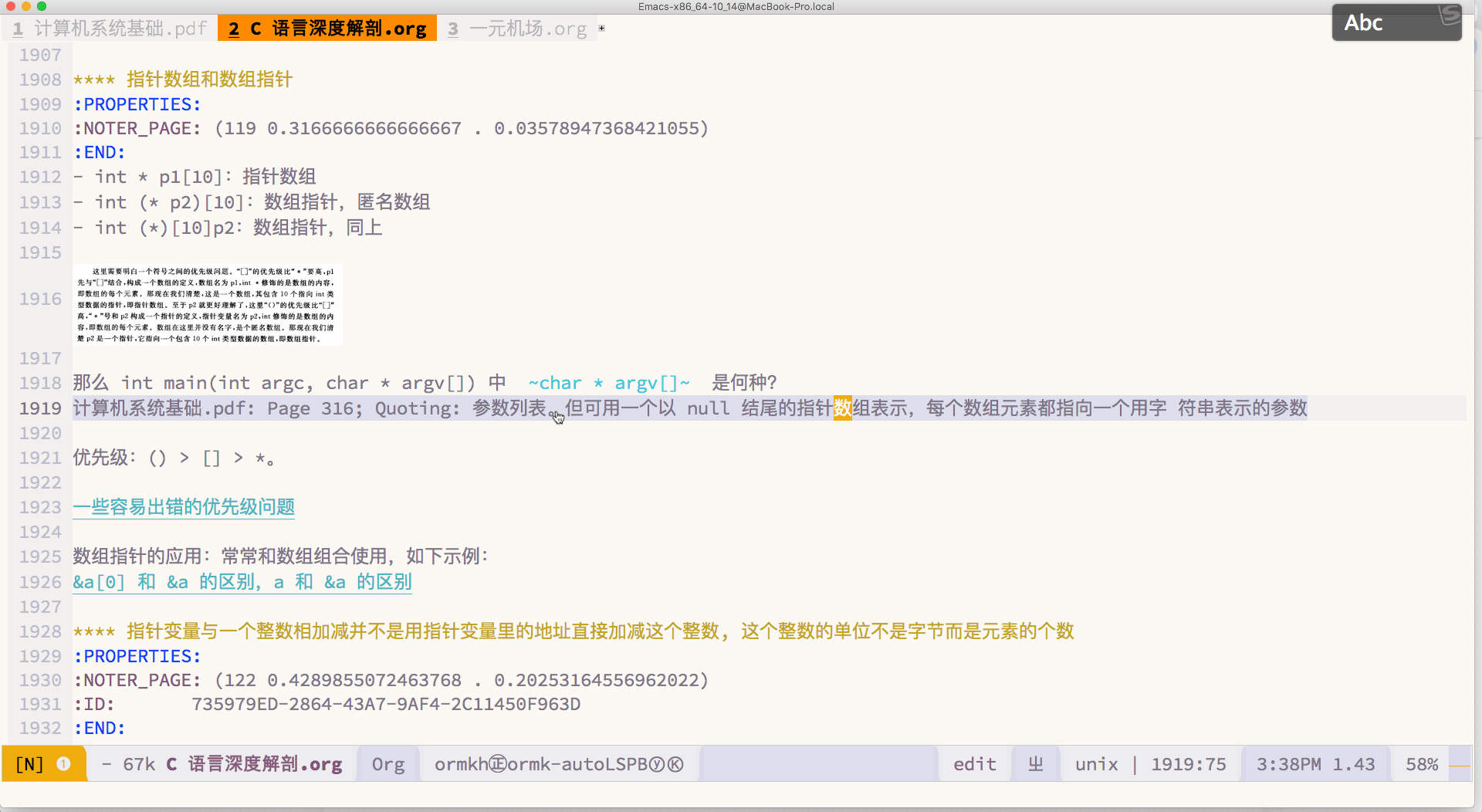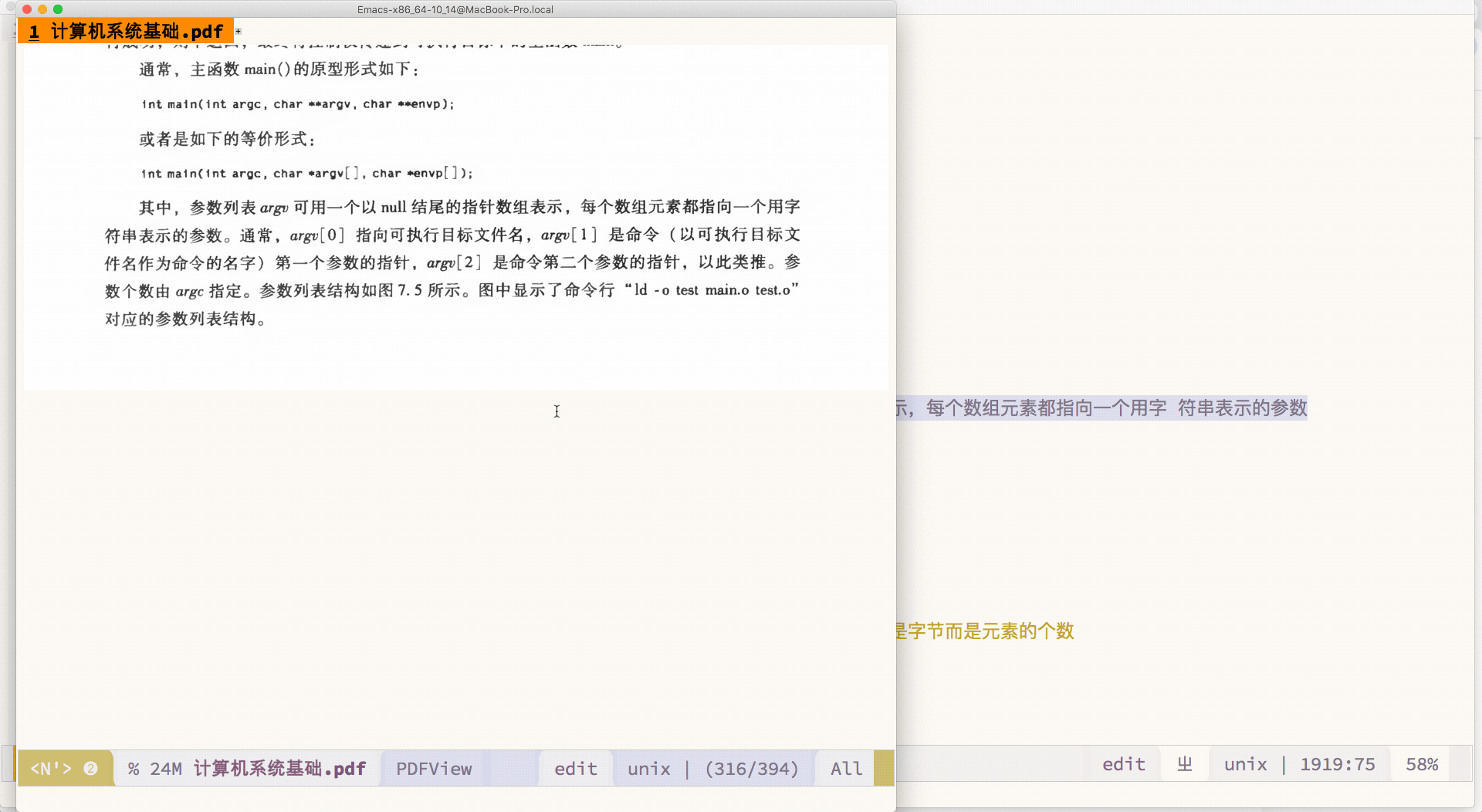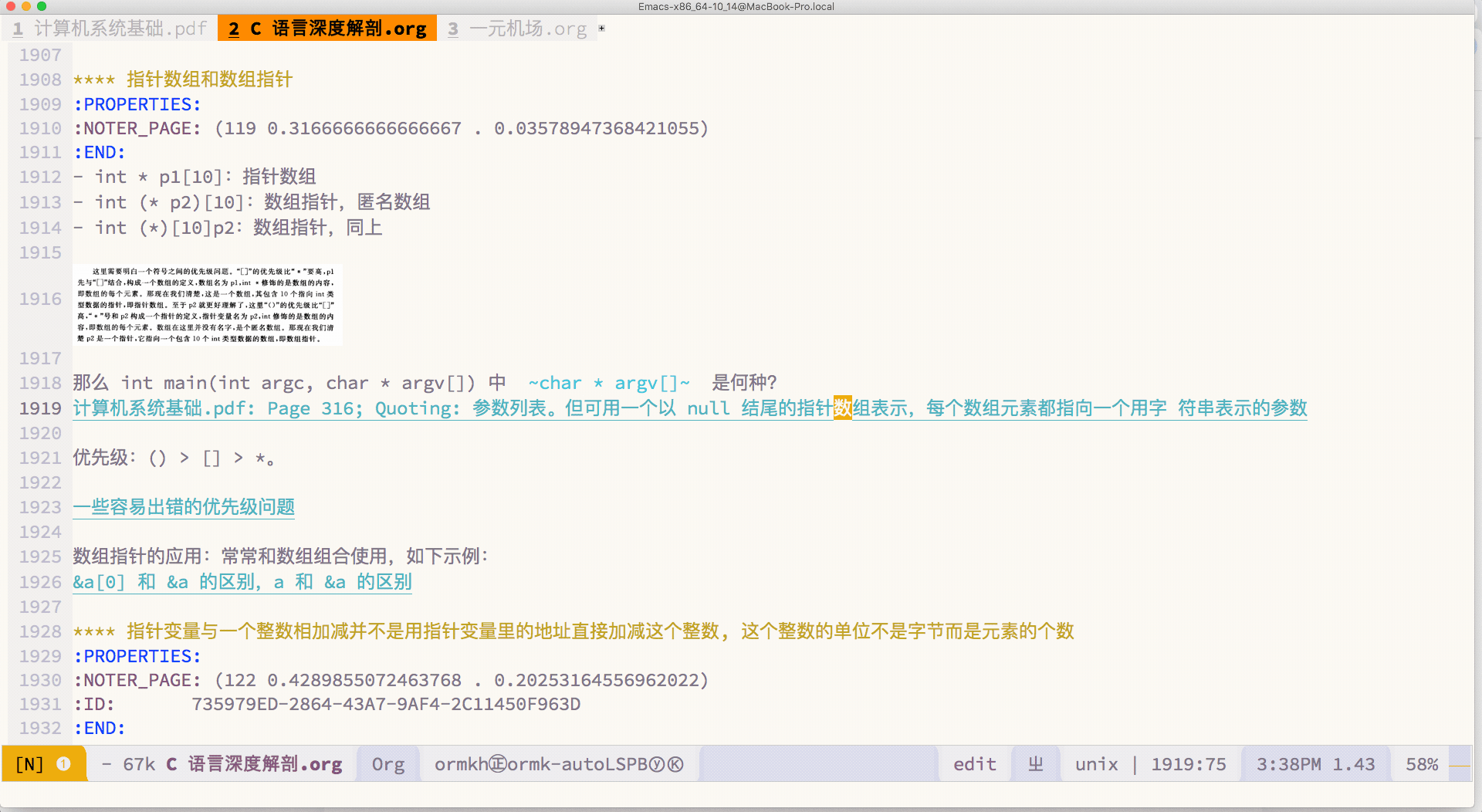
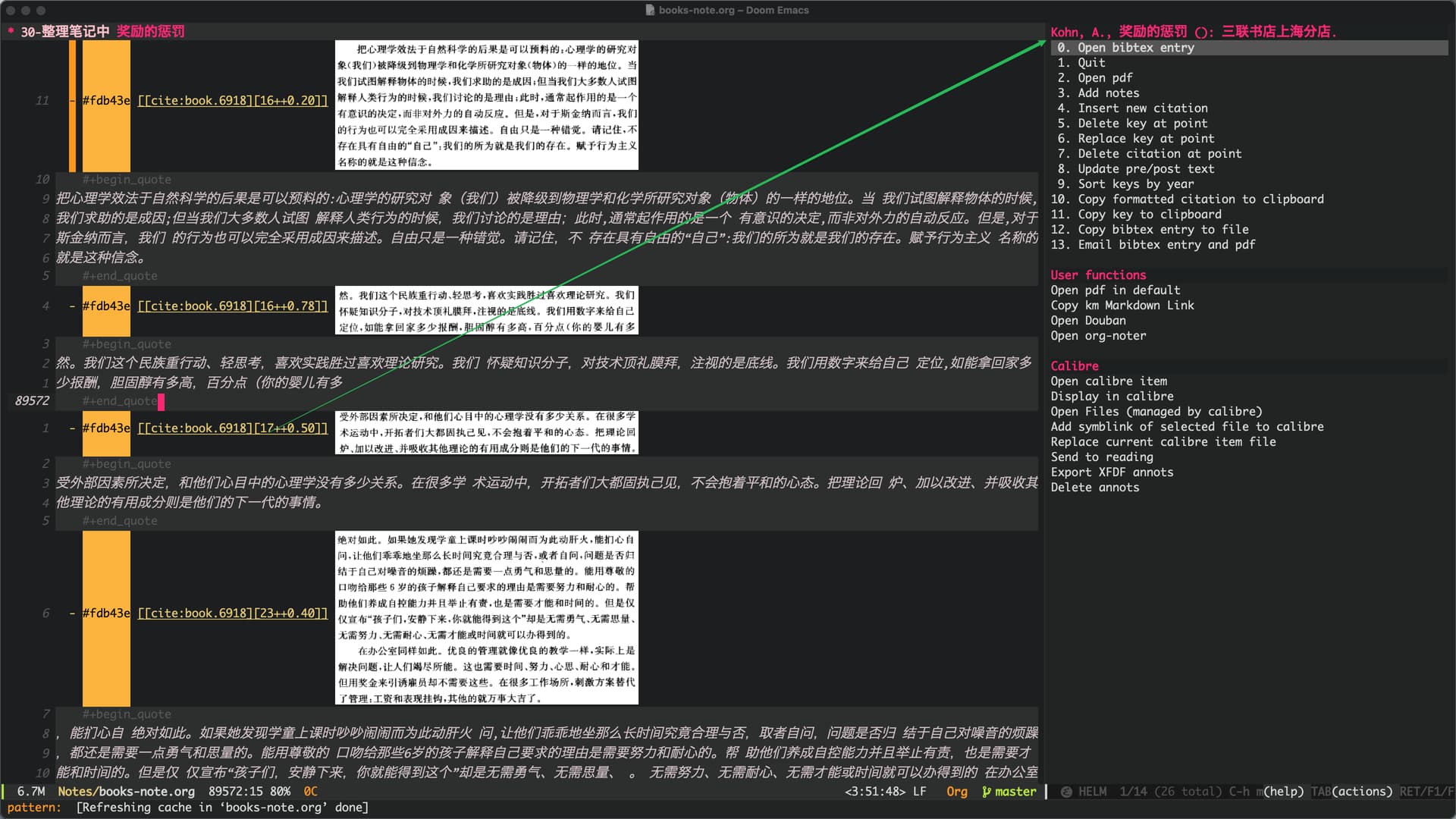
有点烦恼,Calibredb.el 和 Org-noter 无法完美的配合,主要因为 Org-noter 采用古怪的定位笔记文件路径的方式(它采用启动一个 session 的方式来安排笔记文件的路径,而这个路径不可自定义)
而我努力了差不多有 4, 5 天, 也找不到合适的解决方案.
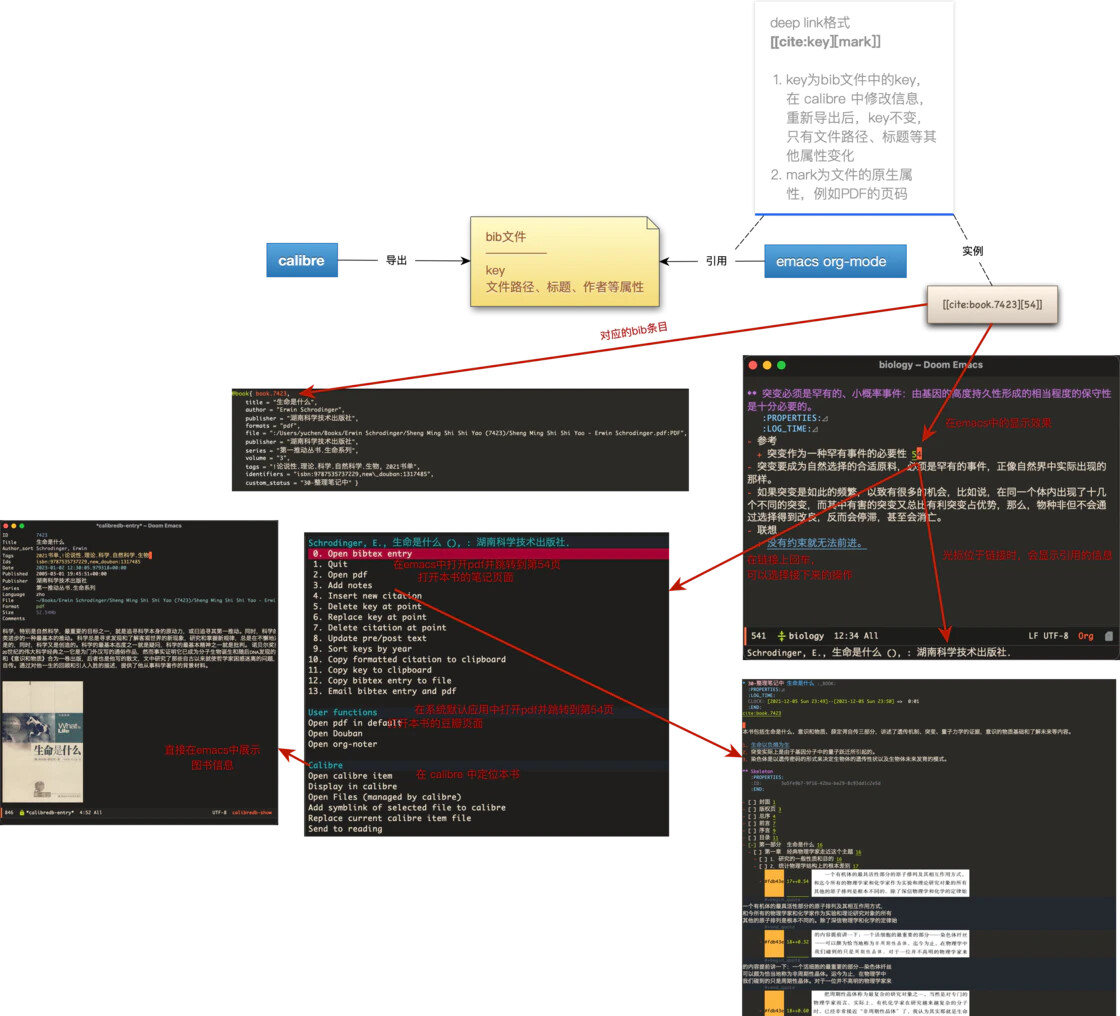
我现在希望重新确立一个更加严谨的笔记系统, 希望里面所记录的内容是可以找到对应出处的. 而整个流程最不能让人满意的, 就是 Org-noter, 我应该怎么弄, 才能够改变这个令人讨厌的插件呢? 一个想法是, 它应该采用类似 Org-roam V2 一样的做法, 将引用文献与笔记之间的关系储存在数据库里, 这样就可以避免倚赖文件名来进行检索和定位了.
我看到, Logseq 也在尝试推荐它的「数据库」版本, 做法也和 Org-roam V2 一样, 将关系储存在数据库里, 以提高检索的效率, 以及避免倚赖文件名定位这一脆弱的方法.
之前在 emacs-china 看到 @cireu 分享的 <终极 OS之梦>, 主要提到 “万物皆是数据库” 的思想, 这一思想的关键所在, 是在文件名之外, 提供了更多的 metadata, 为文件提供更丰富的维度; 此外, 也让文件以更丰富的方法进行组织和发现, 比如像 Calibre 这样为文件进行排序, 打标签, 打星标等等, 甚至可以提供更多的字段来丰富维度.
希望尽快提高自己的工程能力, 可以在 Org-noter 的基础上进行开发,形成 Org-roam + Calibredb + Org-noter + Org-roam-bibitex + helm-bibitex + org-ref 比较完美的笔记流组合.