我在 emacs -Q 下测试过没问题,请排除你的配置问题
给个样例文本看看
我在 emacs -Q 下测试过没问题,请排除你的配置问题
给个样例文本看看
#+title: Test
#+LATEX_CLASS: beamer
#+OPTIONS: H:2 toc:t num:t
#+startup: beamer
#+latex_header: \usepackage{xeCJK}
#+latex_header: \xeCJKsetup{CJKmath=true}
* 第一节
** 测试
这是 *一个* 测试。这是一个公式 \( 项目 \rightarrow 测试 \)。
最怕emacs -Q测试 ![]() ,先看看是不是我配制问题吧。
,先看看是不是我配制问题吧。

这是 emacs -Q 下导出结果,标记一直没有问题,只是行内公式根据个人写法不同导出结果不一致,已更新上面的函数。
我希望你每次回复的时候能注意一下预填充文本,反馈前先用 emacs -Q 测试是一个好习惯
好的,谢谢,那我慢慢找问题吧。顺便贴一下我的导出吧。
\begin{document}
\maketitle
\begin{frame}{Outline}
\tableofcontents
\end{frame}
\section{第一节}
\label{sec:orgb20d632}
\begin{frame}[label={sec:orga84fe28}]{测试}
这是 \alert{一个} 测试。这是一个公式 \(项目 \rightarrow 测试\)。
\end{frame}
\end{document}
这个可以啦,我复制你最新改的函数的时候,忘了把 (with-eval-after-load 'ox ...)这些加进去。感谢!
再报告一个问题
#+title: Test
#+LATEX_CLASS: beamer
#+OPTIONS: H:2 toc:t num:t
#+startup: beamer
#+latex_header: \usepackage{xeCJK}
#+latex_header: \xeCJKsetup{CJKmath=true}
* 第一节
** 测试
这是一个 *简单* 的 *小* 测试。这是一个公式 \( 项目 \rightarrow 测试 \)。
导出的latex是
\begin{document}
\maketitle
\begin{frame}{Outline}
\tableofcontents
\end{frame}
\section{第一节}
\label{sec:org4df4d97}
\begin{frame}[label={sec:orgff7d1eb}]{测试}
这是一个\alert{简单}的 \alert{小} 测试。这是一个公式\(项目 \rightarrow 测试\)。
\end{frame}
\end{document}
第二个标记“小”字两边的空格没有被过滤掉。
我提供的只是一个例子,肯定不能覆盖所有情况
建议根据自己的需求添加相应的正则
好的,谢谢,了解啦。
(defun eli-strip-ws-maybe (text _backend _info)
(let* ((text (replace-regexp-in-string
"\\(\\cc\\) *\n *\\(\\cc\\)"
"\\1\\2" text));; remove whitespace from line break
;; remove whitespace from `org-emphasis-alist'
(text (replace-regexp-in-string "\\(\\cc?\\) \\(.*?\\) \\(\\cc\\)"
"\\1\\2\\3" text))
;; restore whitespace between English words and Chinese words
(text (replace-regexp-in-string "\\(\\cc\\)\\(\\(?:<[^>]+>\\)?[a-z0-9A-Z-]+\\(?:<[^>]+>\\)?\\)\\(\\cc\\)"
"\\1 \\2 \\3" text))
(text (replace-regexp-in-string "\\(\\cc\\) ?\\(\\\\[^{}()]*?\\)\\(\\cc\\)"
"\\1 \\2 \\3" text)))
text))
我不确定是否会有副作用,毕竟个人测试条件有限。
我怎么遇到好多小问题,已经用 emacs -Q 测试过了,请问都是正则导致的吗?
在建立二级标题的时候,如果标题是中文,会出现空格被吞掉的情况
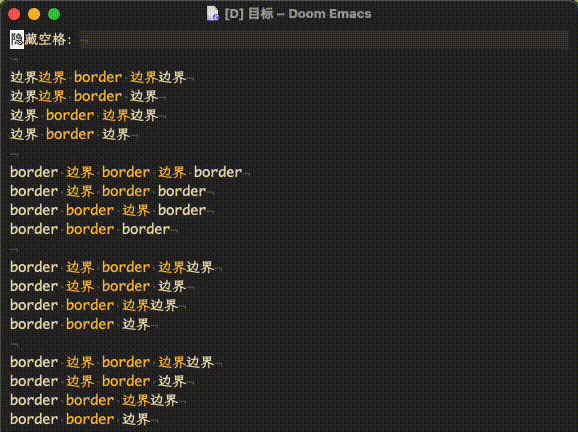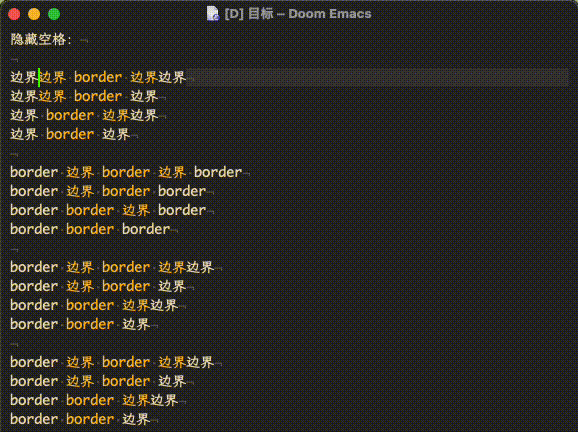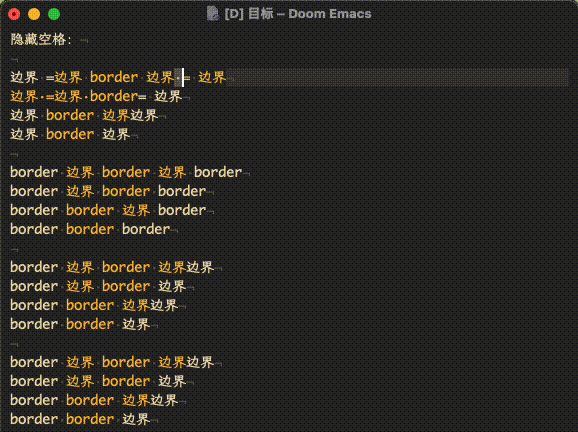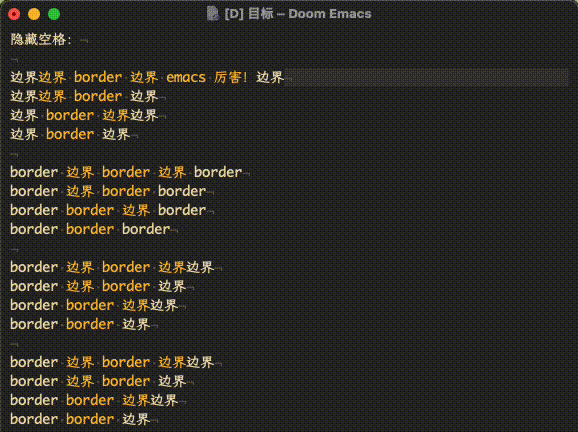
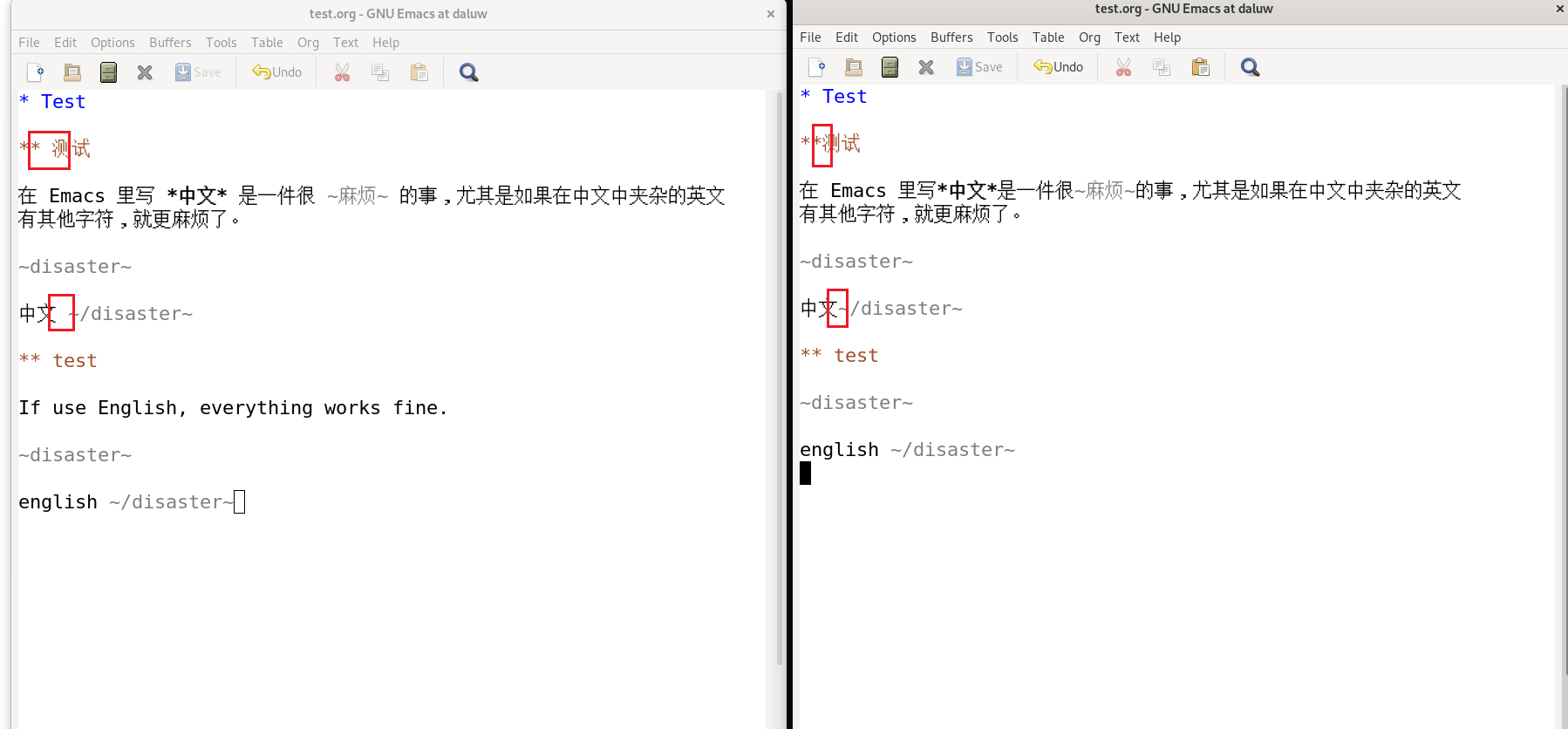
左图是 emacs -Q,右图是在 emacs -Q 的基础上加上了文中提到的 org 配置
抱歉,已更新正则
edit: 再次更新
感谢大佬,修复速度太快了,我也得好好学学正则了,免得遇到什么小问题都得来问 ![]()
话说最终版本是什么,看乱了已经 ![]()
隐藏空格一直是一楼的,导出时过滤空格的正则可以用最新的,不过建议根据自己的习惯和需求自己定义
一直习惯在读推理小说的时候用org-mode做笔记,需要标记一些中文关键词,今天发现用radio-target更适合这个场景,可以在创建target的地方写点概括性的描述
那也未必, 这是我用 prettify symbol 设置的零宽字符的显示:

(("" . 8248))
大部分情况下感观都还不错
应用这个hack,标记前后也可以是字母(无需空格)了(见上,加入了 [:alpha:])
而应用这个hack,会尽可能非贪婪地匹配(见上,加入了 .*?[~=*/_+]),从而实现同一句话多个标记不混杂:

但是,如果同时使用这两个hack,会出现一些特别的问题:
比如对于org-mode中文本:
www.baidu.com/ =sdf=
预期高亮行为是:
![]()
但是同时应用两个hack后是:
![]()
这是因为第一个 / 和后面的 = 匹配上了,而后面的 = 就无法匹配了。
以上还是较为简单的情形,如果复杂的话,一行同时有无序列表(+、-、*)、链接(很多 /),就比较复杂了,很大概率没有正确显示。
不过正如前辈所讲,渲染和导出机制不同:
以上问题只影响在Emacs里的高亮,导出是没问题的(我只做了少量测试)。
如果哪位前辈有更好的见解,欢迎指点!
因此我目前还是采用 font-lock 来隐藏空格,归纳论坛诸多前辈的代码,我目前是这么操作的:
(defvar org-hide-space-keywords
'(("\\cc\\( \\)[*/_=~+]\\cc.*?[*/_=~+]"
(0 (prog1 () (when org-hide-emphasis-markers (add-text-properties (match-beginning 1) (match-end 1) '(invisible t))))))
("[*/_=~+].*?\\cc[*/_=~+]\\( \\)\\cc"
(0 (prog1 () (when org-hide-emphasis-markers (add-text-properties (match-beginning 1) (match-end 1) '(invisible t))))))))
(font-lock-add-keywords 'org-mode org-hide-space-keywords 'append)
;; disable
;; (font-lock-remove-keywords 'org-mode org-hide-space-keywords)
只要“标记”和“未标记”文本的相邻边界都是中文,则隐藏(invisible)这一侧的空格:
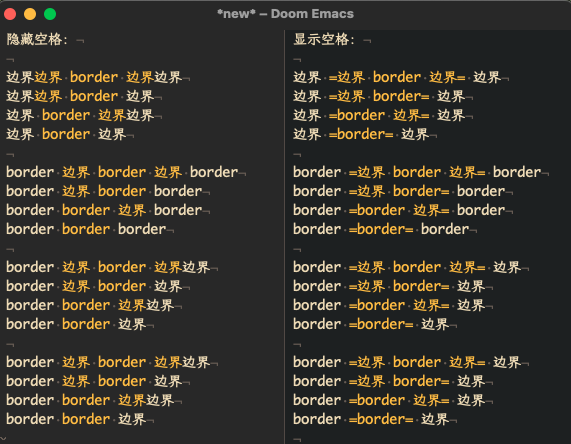
同时,通过开关 org-hide-emphasis-markers ,标记符号(+、=、~等)会与符合上面特征的空格,一起显示或隐藏。
同时,有一个众所周知的包 org-appear 可以自动显示和隐藏这些标记符号,通过一个小 hack,可以使它自动显示和隐藏周围的空格:
(psearch-patch org-appear--show-invisible
(psearch-replace '`(t . ,_args)
'`(t
(remove-text-properties (1- start) visible-start '(invisible org-link))
(remove-text-properties visible-end (1+ end) '(invisible org-link)))))
这里我是用 psearch 来 hack 的,其实就是修改函数 org-appear--show-invisible:
- (remove-text-properties start visible-start '(invisible org-link))
+ (remove-text-properties (1- start) visible-start '(invisible org-link))
- (remove-text-properties visible-end end '(invisible org-link)))
+ (remove-text-properties visible-end (1+ end) '(invisible org-link)))
最终效果如下: