最近需要在 org-mode 里写大量的伪代码,网上搜了下发现没有比较好的方案,于是自己折腾了下。
也欢迎大家分享自己的方案。
伪代码预览
先上效果图:
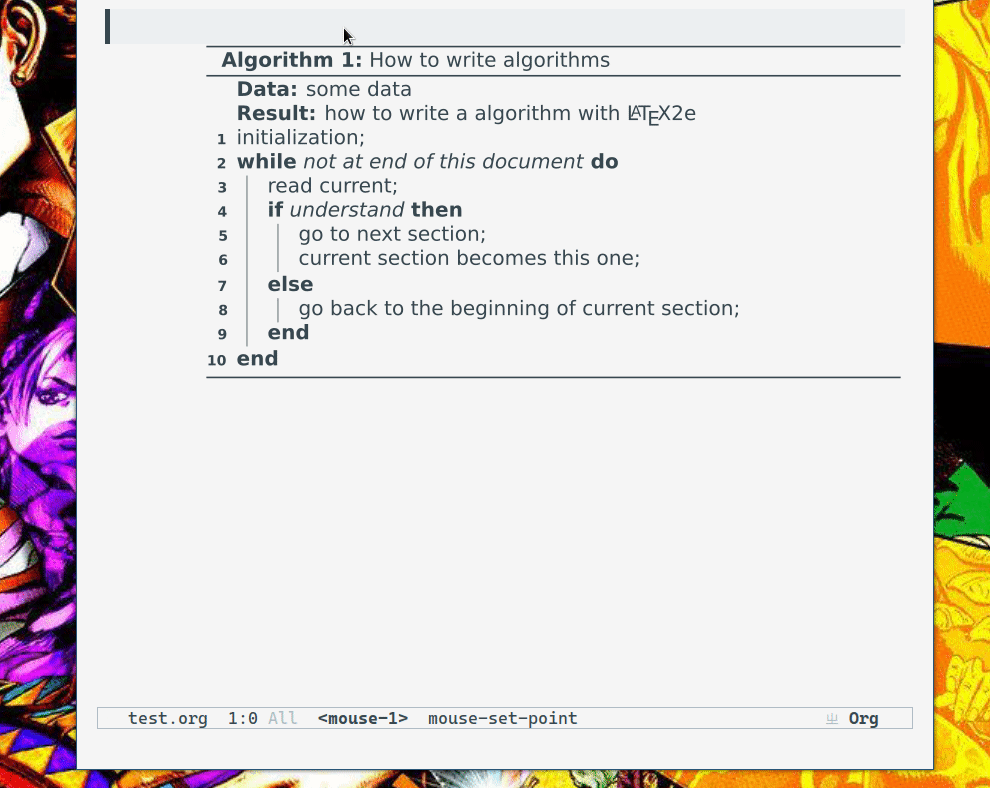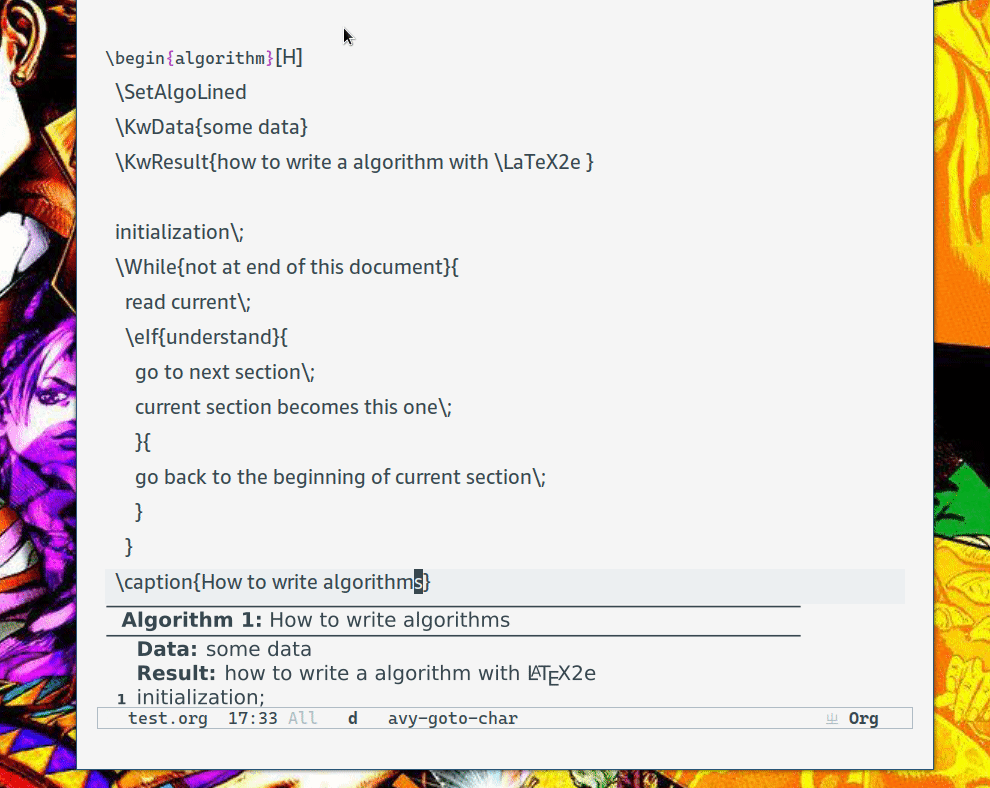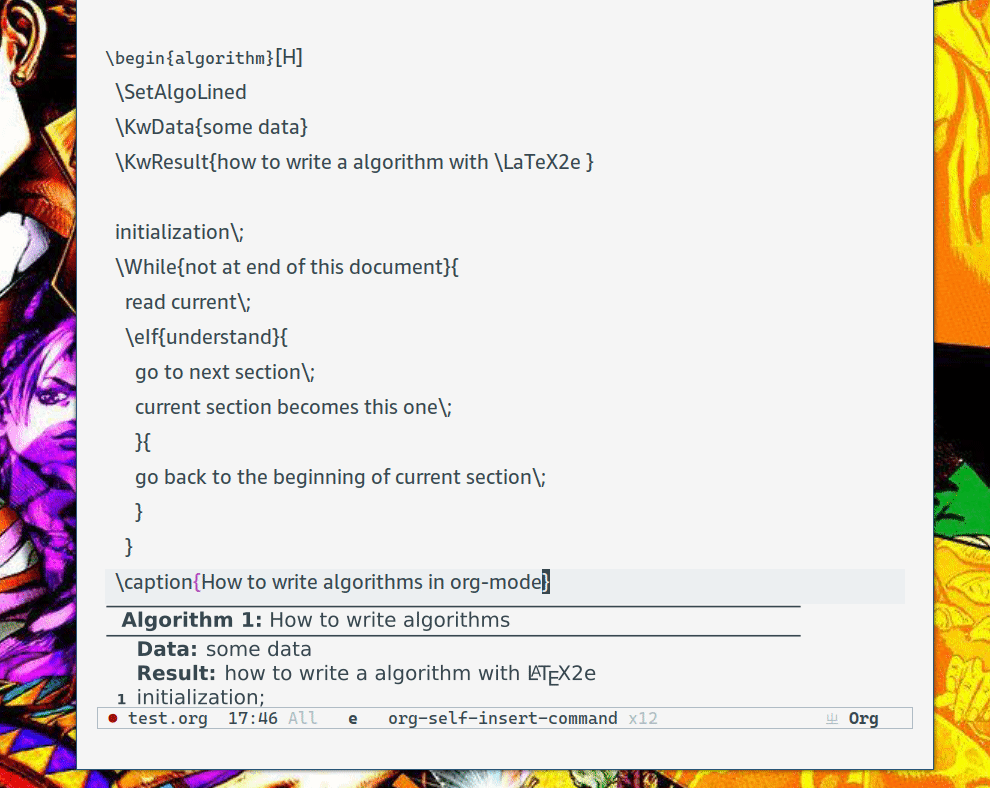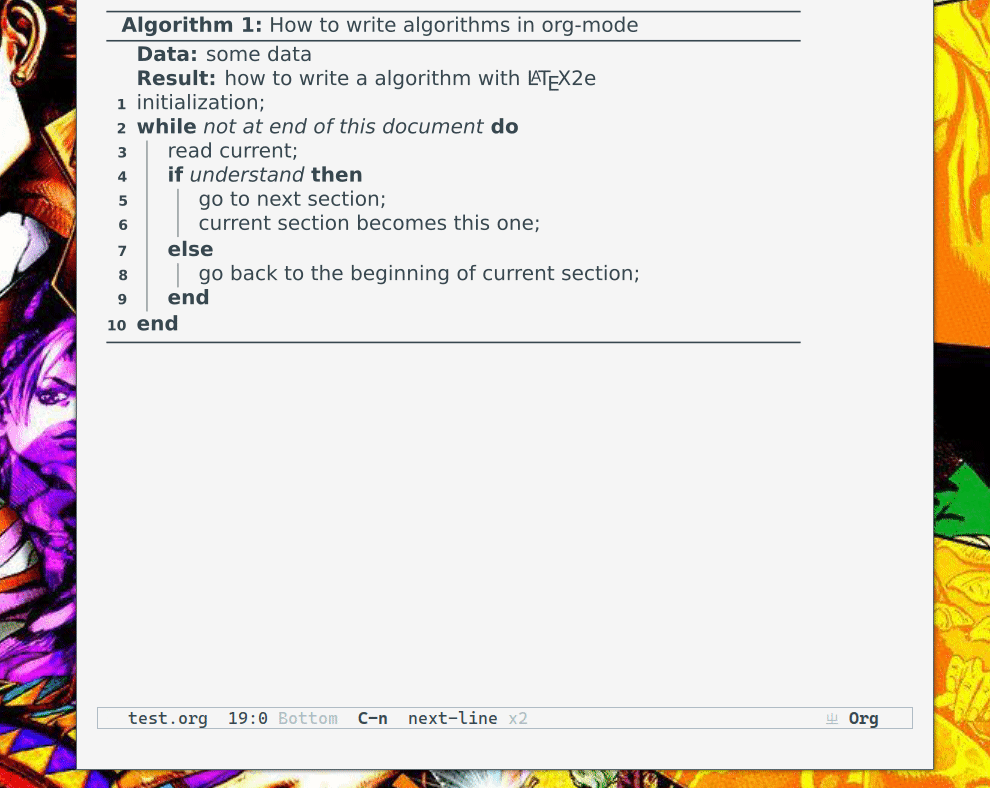
基于 xenops 做了些扩展,使其能够解析相应的 LaTeX 代码块(我是用 algorithm2e 来写的)。
代码
(add-to-list 'xenops-elements '(algorithm
(:delimiters
("^[ ]*\\\\begin{algorithm}" "^[ ]*\\\\end{algorithm}"))
(:parser . xenops-math-parse-algorithm-at-point)
(:handlers . block-math)))
(defun xenops-math-parse-algorithm-at-point ()
"Parse algorithm element at point."
(xenops-parse-element-at-point 'algorithm))
(defun xenops-math-parse-element-at-point ()
"Parse any math element at point."
(or (xenops-math-parse-inline-element-at-point)
(xenops-math-parse-block-element-at-point)
(xenops-math-parse-table-at-point)
(xenops-math-parse-algorithm-at-point)))
(defun xenops-math-block-delimiter-lines-regexp ()
"A regexp matching the start or end line of any block math element."
(format "\\(%s\\)"
(s-join "\\|"
(apply #'append (xenops-elements-get-for-types '(block-math table algorithm) :delimiters)))))
HTML 导出时转换成图片
我比较喜欢在导出成 HTML 时将图片编码为 base64 ,这样就不用担心图床之类的问题了。
所以可以很方便的直接复用 xenops 的缓存图片,直接导出不需要其他 hack。
具体做法是使用 org-export-before-parsing-functions(org-mode 9.5 及更低版本是 org-export-before-parsing-hook ),导出前将代码块换成相应的图片链接。
代码
(defun eli/filter-org-html--format-image (orig source attributes info)
"Use base64 string instead of url to display images.
This functions is a advice for `org-html--format-image',
arguments, SOURCE ATTRIBUTES and INFO are like the arguments with
the same names of ORIG."
(let ((image-html (funcall orig source attributes info))
(image-base64 (format "data:image/%s+xml;base64,%s\"%s"
(or (file-name-extension source) "")
(base64-encode-string
(with-temp-buffer
(insert-file-contents-literally
(file-relative-name
(substring source 7)
default-directory))
(buffer-string)))
(file-name-nondirectory source))))
(replace-regexp-in-string "img src=\"\\(.*?\\)\"" image-base64 image-html
nil nil 1)))
(advice-add 'org-html--format-image :around #'eli/filter-org-html--format-image)
(defun eli/org-html-export-replace-algorithm-with-image (backend)
"Replace algorithms in LaTeX with the corresponding images.
BACKEND is the back-end currently used, see `org-export-before-parsing-functions'"
(when (org-export-derived-backend-p backend 'html)
(let ((end (point-max)))
(org-with-point-at (point-min)
(let* ((case-fold-search t)
(algorithm-re "^[ ]*\\\\begin{algorithm}"))
(while (re-search-forward algorithm-re end t)
(let* ((el (xenops-math-parse-algorithm-at-point))
(cache-file (abbreviate-file-name
(xenops-math-get-cache-file el)))
(begin (plist-get el :begin))
(end (plist-get el :end)))
(delete-region begin end)
(insert (concat "[[" cache-file "]]")))))))))
(add-to-list 'org-export-before-parsing-functions
#'eli/org-html-export-replace-algorithm-with-image)
效果如下:

这样就可以比较舒服的在 org-mode 里写伪代码了,具体配置见:.elemacs/init-latex.el at master · Elilif/.elemacs · GitHub
