在学习日语的过程中,有一些背单词的需求,于是就把目光投向了anki。使用过程中体验非常的好,及时的复习以及每天合理的新词汇数量都极其合我心意。
但由于我使用的教材是《大家的日本语》,网上的anki牌组,无论是收费的还是免费的,都只有初级的50课。中级的教材中,目前我手头只有纸质的材料,每一课的单词表都有,该如何通过ocr识别,将他们制成anki牌组呢?
尝试过使用白描,在扫描成表格的步骤中,对于日语的识别非常非常差,全都强行附会成了形近的中文汉字。
请教各位道友,如何比较高效率地将这纸质材料整理成anki牌组?
手动一张一张输进去,ocr 处理做不到所有图都正确,只能用于辅助。
诚然。之前看到过一个说法,就是anki制卡的过程其实也是一次学习或者复习的过程,深以为然。
但是如果真的纯手动实在是太慢了,日语的特别之处在于有汉字、读音(假名)、释义三部分,如果是英语的话只需要单词和释义,并且输入法用shift切一下中英文输入模式即可。我现在有三个输入法

从中文切换到日文需要两次Win+space然后Alt+~,繁琐的程度到了有些难以接受的程度了。
如果用excel按列来输入,固然是可以,但是这样的话前面所说的制卡兼学习的意义又会丧失掉。所以也是我不太想要采纳方式。
昨天试着用自己的方式做了一下,现阶段还算比较满意,简单介绍一下流程吧。
首先是手机上通过扫描全能王这个app进行扫描,可以自动把页面展平、加强对比度等等,当然这一步如果有扫描仪来完成自然是最好。
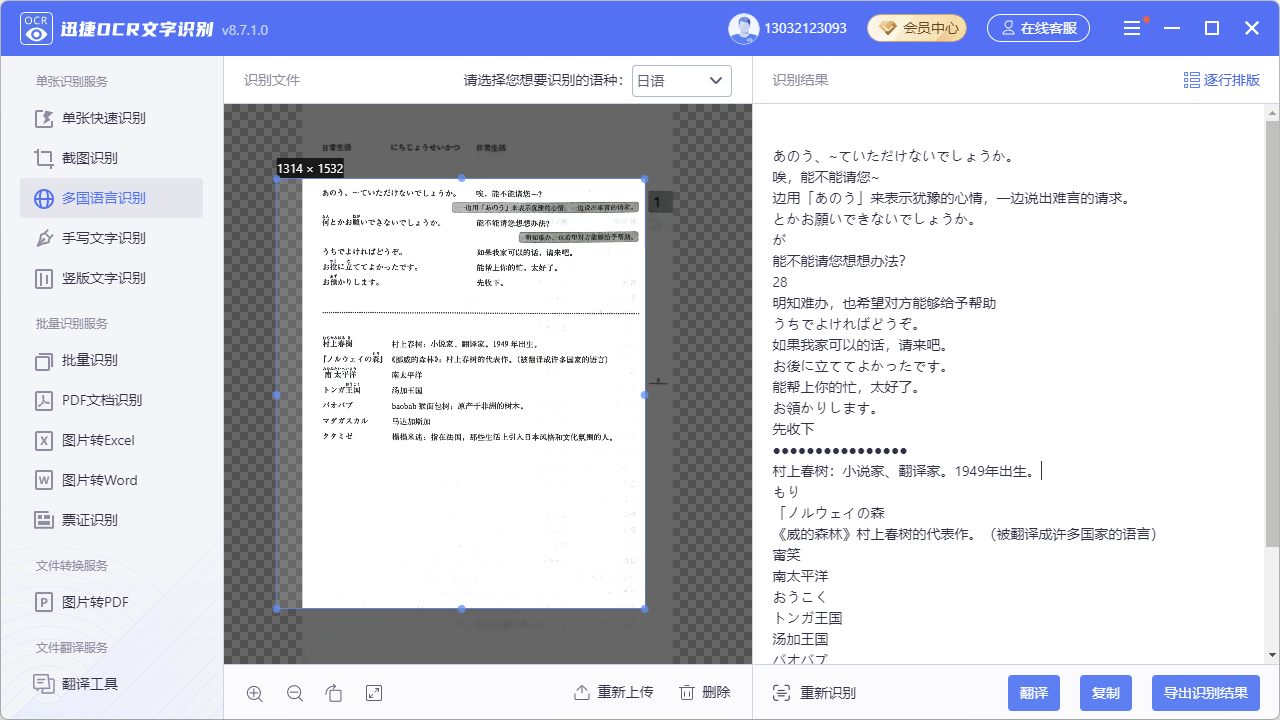
接下来传到电脑上后,我通过迅捷OCR的多国语言识别进行识别。免费的也可以识别,但是结果不能复制或者导出,但是我看到了扫描的效果还是不错的,就买断了,买断后不限次数,并且可以导出。
导出的内容还是有一些错误的,比如我上面给出的这一页中,导出的内容就是
あのう、~ていただけないでしょうか。
唉,能不能请您~
边用「あのう」来表示犹豫的心情,一边说出难言的请求。
とかお願いできないでしょうか。
が
能不能请您想想办法?
28
明知难办,也希望对方能够给予帮助
うちでよければどうぞ。
如果我家可以的话,请来吧。
お後に立ててよかったです。
能帮上你的忙,太好了。
お領かりします。
先收下
●●●●●●●●●●●●●●●●
村上春树:小说家、翻译家。1949年出生。
もり
「ノルウェイの森
《威的森林》村上春树的代表作。(被翻译成许多国家的语言)
甯笑
南太平洋
おうこく
トンガ王国
汤加王国
バオバブ
baobab猴面包:原产于非洲的树木
マダガスカル
马达加斯加
タタミゼ
榻榻米迷:指在法国,那些生活上引人日本风格和文化氛围的人。
错误不少(这一页由于格式比较乱,错误偏多;前几页效果还是不错的),手动修掉一些错误之后,按照字段再进行分割,
あのう、~ていただけないでしょうか。,,唉,能不能请您~<br>一边用「あのう」来表示犹豫的心情,一边说出难言的请求。
何とかお願いできないでしょうか。,,能不能请您想想办法?<br>明知难办,也希望对方能够给予帮助
うちでよければどうぞ。,,如果我家可以的话,请来吧。
お役に立ててよかったです。,,能帮上你的忙,太好了。
お預[あず]かりします。,,先收下
因为我选择的是汉字 假名 释义的形式,一些词汇没有汉字,则用假名来填充汉字字段,然后把假名字段空出来。需要换行的地方用<br>来代替。最终形成这样的一个txt文档。
最后一步把这个txt文档导入anki,就完成了制作。
找一个带日语识别功能的软件就好了啊,很多OCR都可以调当前识别语言的。