这两天在做一个爬取房屋拍卖数据的作业
https://auction.jd.com/sifa_list.html?childrenCateId=12728
把数据爬出来再转化为自己小程序里的数据,因为表格不好转化,所以转化为图片(顺便体验到了Puppeteer的强大威力,尤其对俺这种前后端+canvas都了如指掌的工程狮来说)
正在写的代码:
http://spider.celwk.com/
爬到的数据生成的JSON:
http://spider.celwk.com/products/
渲染成
图片:
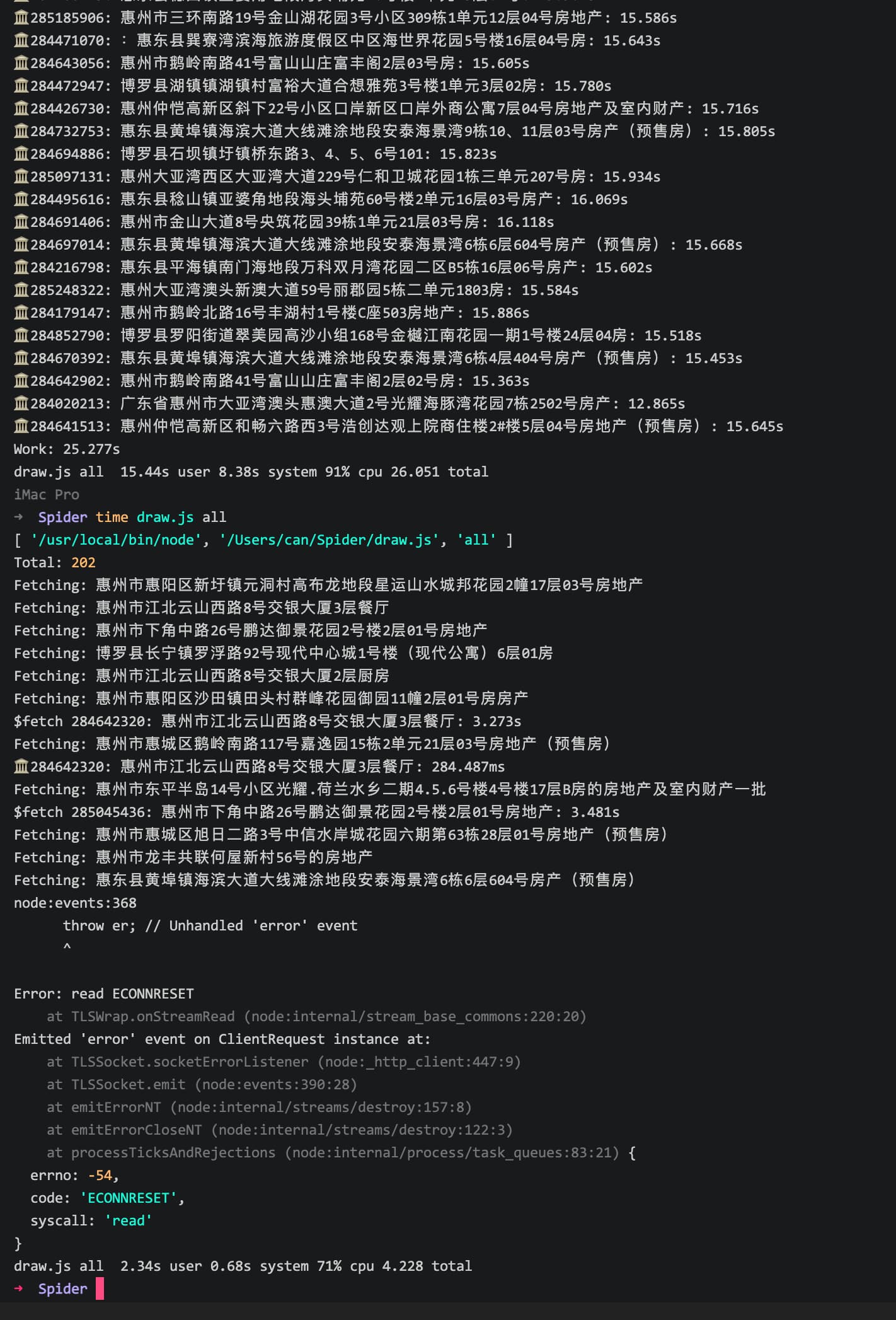
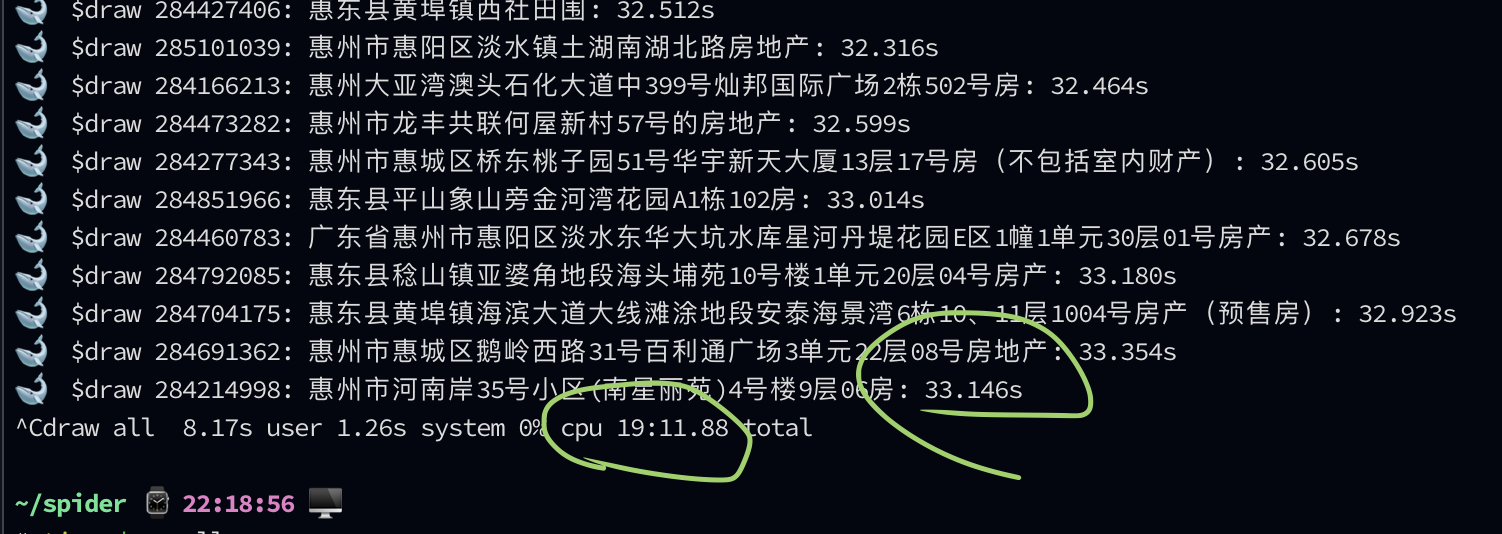
http://spider.celwk.com/table暂时只抓取200条的数据左右,一开始要每抓一条要1~2秒,所以要4~5分钟才抓完,后面用到并行(本质就是多线程吧?)Promise.all,同时请求和渲染,只要25~30秒左右就搞定,快了5~10倍!!
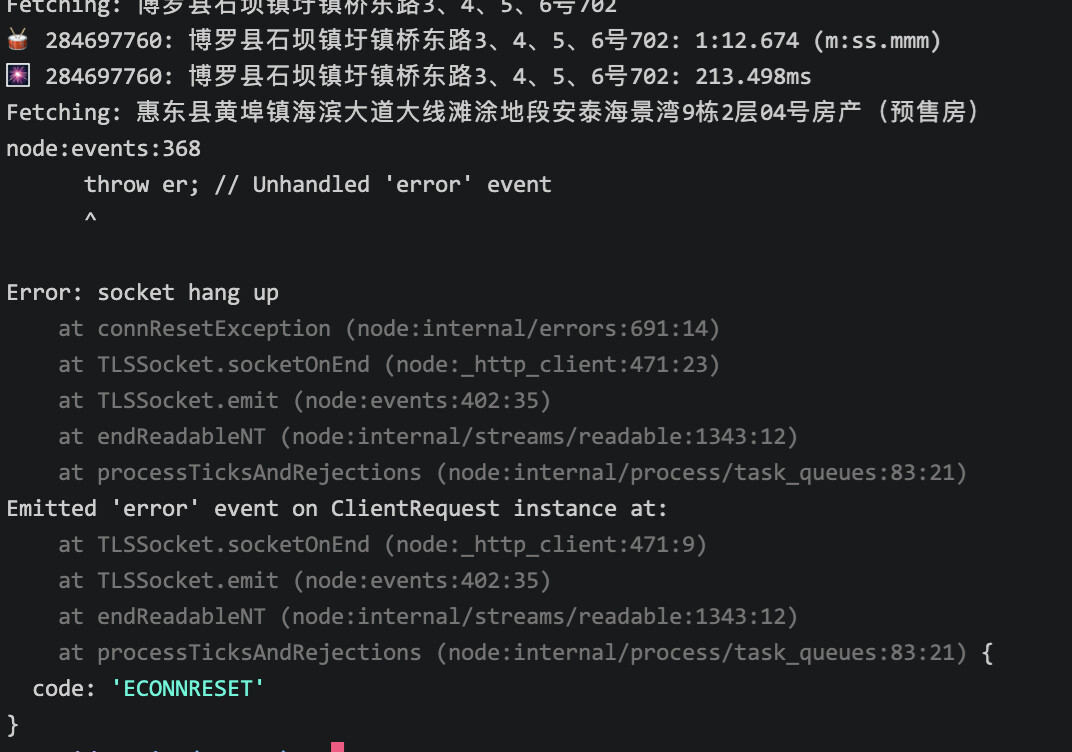
不过问题来了,大多时候是正常的,有时候又在爬到一部分(数量很随机)的时候出错,并且错误有时候又不一样,有时错误提示涉及到 socket hang up:
一开始以为在本地Mac才会,结果验证了在(阿里云)服务器Ubuntu也会,大多正常,也会时不时中途弹出类似的错误,而且有时候又是到了某一点就一动不动,要强制退出(Mac好像不会):
请教这会是什么问题?多线程冲突?还是Chrome内核(Chromium/Puppeteer)?
如果解决不了这个问题,可能问题也不大,就定时(例如30分钟,一般用crontab而不用自己用node.js去调用子进程吧)执行一次,只要发生概率低于50%,那就也可以??
咱要爬的数据也不会很大量啊,例如”暂时“只爬惠州近几个月的,大概就200条
咱伙伴其实也是参考某个app的,里面的数据可以从淘宝/京东里搜到

是不是服务端拒绝长连接啊,要不你抓个包看看?如果是这样的话请求头不用 keep-alive 就可以了
1 个赞
刚开始认真地玩爬虫,咱还没有“抓包”的概念🥲
如果有,请赐咱一本爬虫类的《葵花宝典》
错误提示看起来不是数据的远程获取错误(除了那个一直没反应但没提醒错误的情况),而是内部的线程之类的
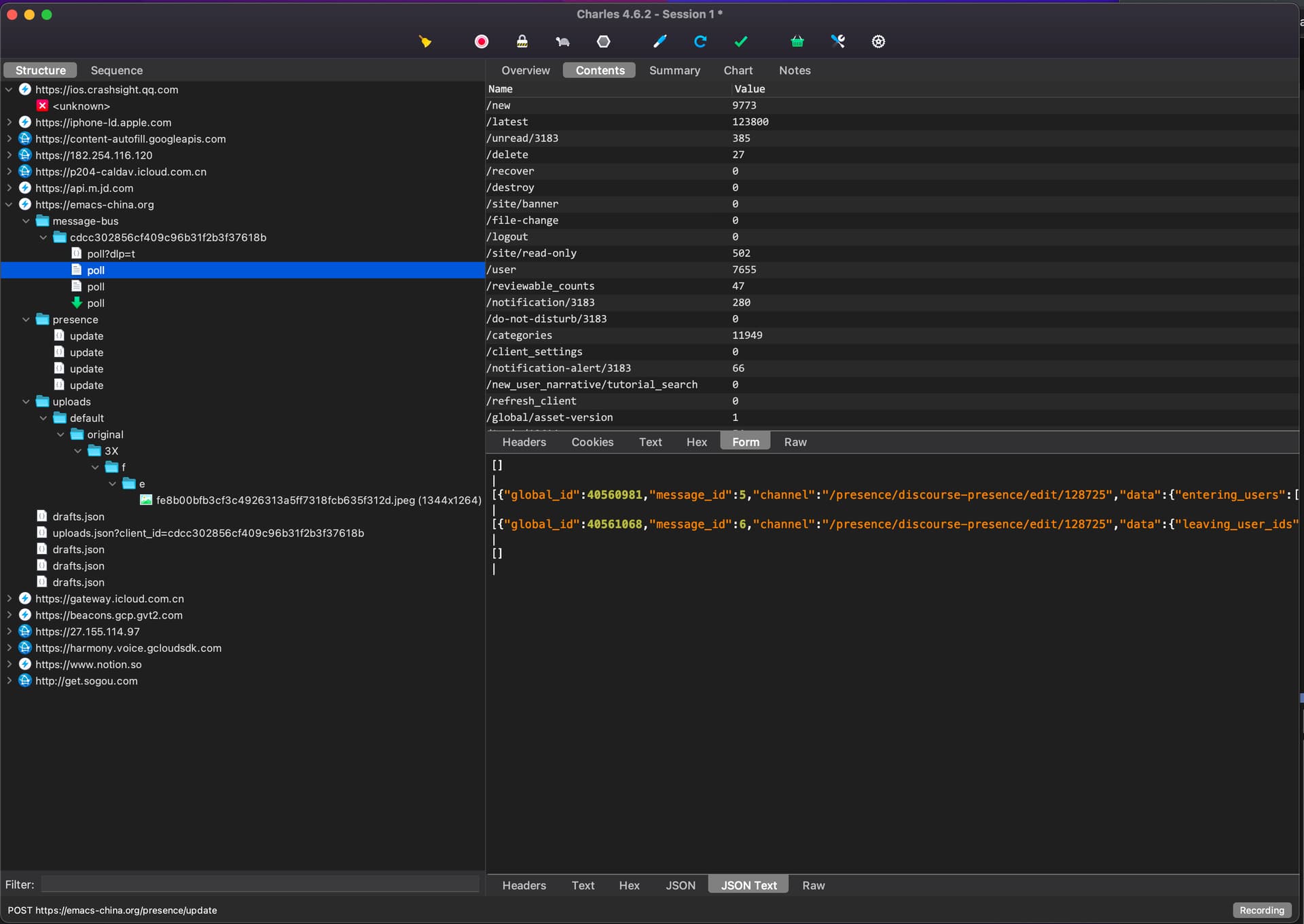
请教你们用什么工具抓取iPhone app(例如美团)和 iMac app(例如Kindle)的请求? 网上搜的好像主要是Charles?
Bitnut
11
这个工具我用的不多,一般就是用 wireshark 或者 tcpdump 抓抓包,看他的博文感觉区别不大。
玩了两三个小时,感觉还挺好玩的,以后抓取app的数据不难了  ,甚至可能比我用Chrome的Developer Tools 还更好抓!
,甚至可能比我用Chrome的Developer Tools 还更好抓!
咱猜是这个原因了,因为平均一秒钟请求几十上百个API,而不是客户端的原因
俺太“单纯”了,提示都有写着 Unhandled ‘error’ event…
只要加上 req.on(‘error’,……) 就不会被“秒”了
这些error的原因估计是因为爬虫短时间大量https请求,服务器主动长连接了?
咱没“刻意”加 keep-alive header(默认有吗?)