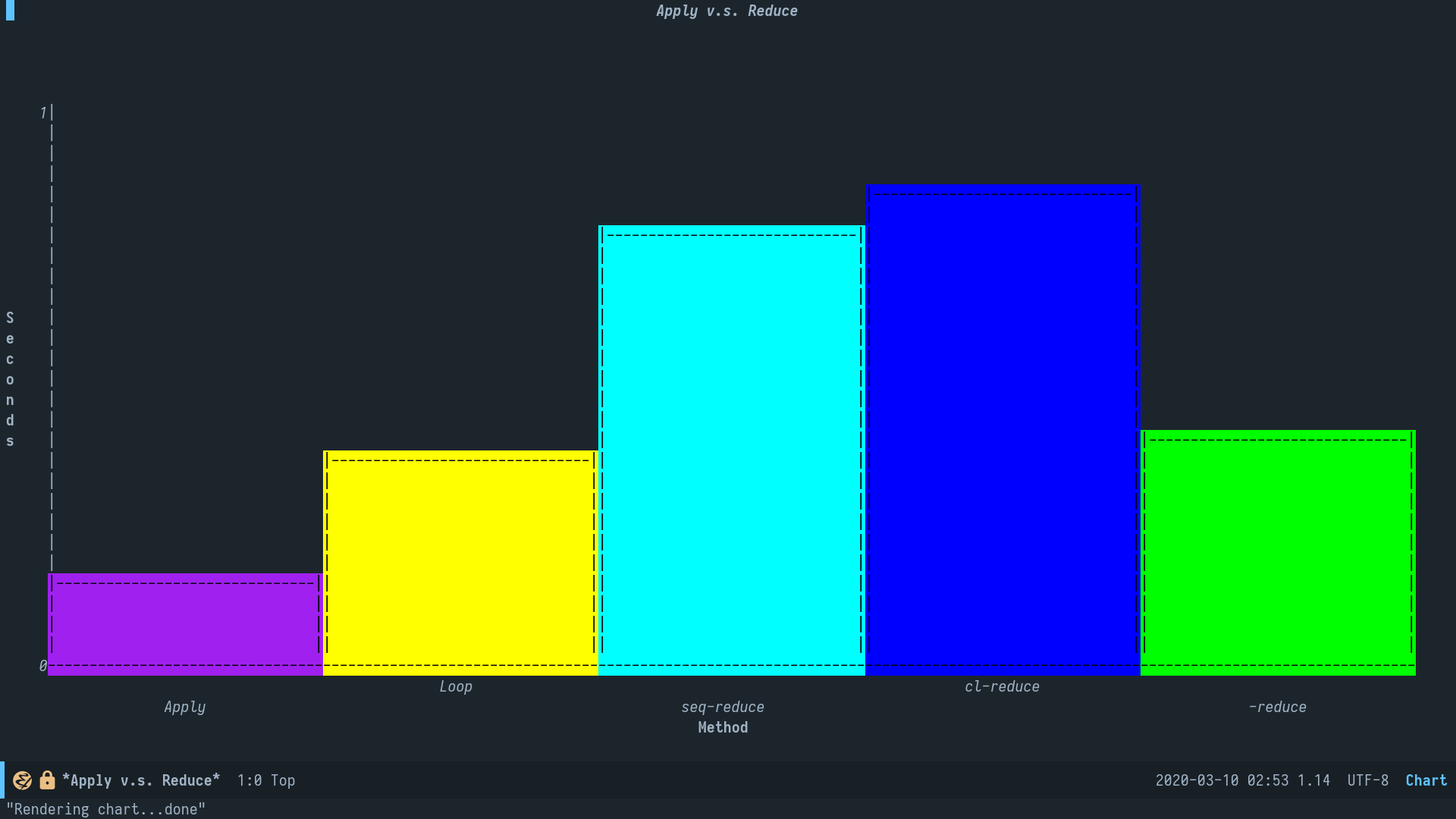
Apply v.s. Reduce 对照这个贴子,重新做了个图表。注意到其中cl-reduce和-reduce已经经过了native-comp,seq-reduce仍然是byte-comp。我猜测seq-reduce是用cl-defmethod定义的多态函数,生成其函数体需要手动拼接lambda,所以没法被优化。
更新:O2优化编译dash.el后,-reduce甚至比loop还要快一丢丢,实属厉害
Apply v.s. Reduce 对照这个贴子,重新做了个图表。注意到其中cl-reduce和-reduce已经经过了native-comp,seq-reduce仍然是byte-comp。我猜测seq-reduce是用cl-defmethod定义的多态函数,生成其函数体需要手动拼接lambda,所以没法被优化。
更新:O2优化编译dash.el后,-reduce甚至比loop还要快一丢丢,实属厉害