我在dired 下试图 revert-buffer-with-coding-system,姿势对不对?
一般这种乱码是什么编码?
Windows 下压缩的啥?rar?zip?7z?tar?
应该 7z 吧
压缩包文件名是 #YouXun#, 下面是解压的 bat 文件
if exist .\7z.exe (
.\7z.exe x %%a\#YouXun# -o.\game -m0=BCJ -aoa -m1=LZMA:d=21 -ms -mmt
goto end
)
微软历史遗留,用的 GBK
有什么办法修正吗
用maczip编码是正确的,你可以试试
citreu@asus-laptop:~/tmp/gbk-test$ touch $(echo 你好谢谢小笼包再见 | iconv -t gbk)
citreu@asus-laptop:~/tmp/gbk-test$ touch $(echo 太好听了吧 | iconv -t gbk)
citreu@asus-laptop:~/tmp/gbk-test$ ls
'̫'$'\272\303\314\375\301''˰'$'\311' ''$'\304\343\272\303''ллС'$'\301\375\260\374\324''ټ'$'\373'
citreu@asus-laptop:~/tmp/gbk-test$ for i in *; do mv "$i" "$(echo $i | iconv -f gbk -t utf-8)"; done
citreu@asus-laptop:~/tmp/gbk-test$ ls
你好谢谢小笼包再见 太好听了吧
看起来是打包的时候文件名就是这样。
7z 文件头包含编码,解码的时候无论哪个平台不会错的。
GUI工具的话,我之前用的 Keka - the macOS file archiver 感觉对编码识别和处理的比较好。
命令行的话,可以用 unar 可以在命令行制定编码
那就用The Unarchiver 手动选择编码解压,还不行就是压缩的问题了
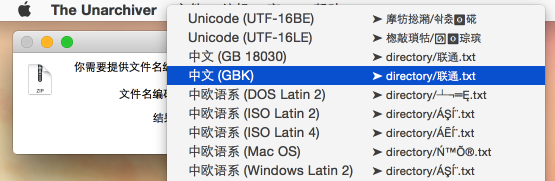
楼上说的编码是 GBK 不太准确。应该说不同语言系统编码都是对应的编码(比如一些日文资源的压缩包就要用 shift jp)。现在 win 10 差不多有慢慢变成 utf8,但各种场景还是会出现两种编码都在用的情况。
这类问题主要出现在 zip 上,因为 zip 头部不包含编码信息,也不像 tar 那样标准就用 utf8
一种方案是楼上用 the unarchiver(也就是 unar,它在 mac 上是有 GUI 的),有自动处理。
手动的方案是可以先用 libuchardet 来判断编码是什么,如echo "file" | uchardet,然后用 convmv -f <from> -t utf8 --notest -r <dir>来转换(这里 notest 去掉则是不实际改名,而打印转换后的,但因为终端输出的编码等各类因素,打印出来的很不准确,请以实际改名后的为主)。这里 convmv 干的事也就是楼上手动用 iconv 干的事
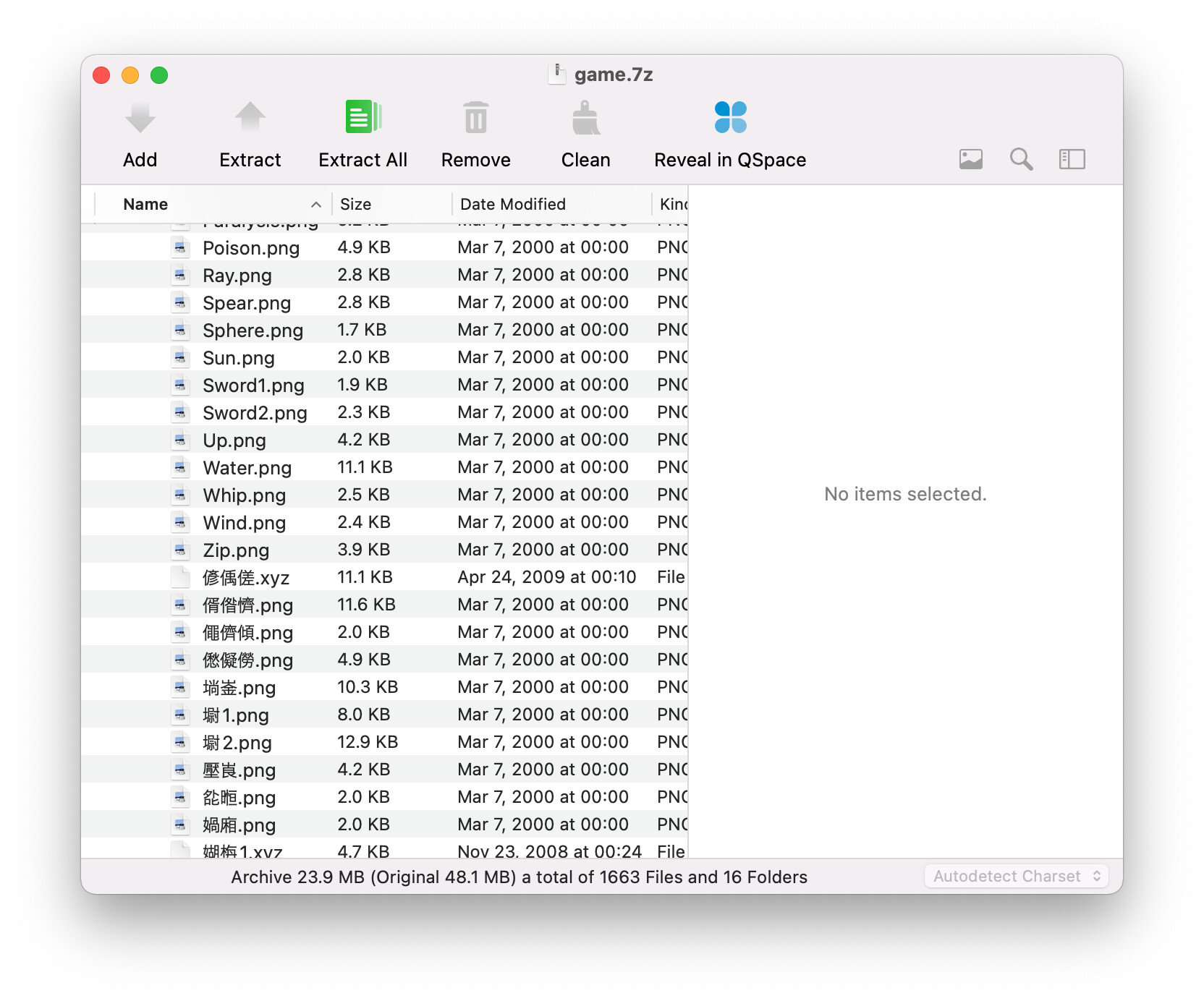
我印象中没遇到过乱码的 7z 压缩包。
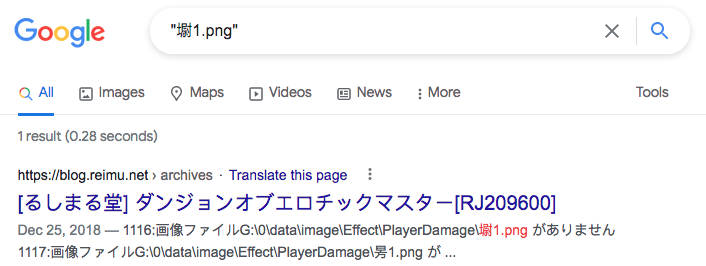
我谷歌了一下「墛1.png」这个“乱码”文件名,唯一的结果是一款日本成人RPG游戏的安装错误日志:
是废都物语啦,的确是日本人做的 RPG,的中文版。
(幸亏不是你说的那个 [抹汗])
The Unarchiver 都是直接把活干了,怎么才能停留在这个界面呢?
我有把 autodetection threshold 设置100%也不行,看来它对编码100%确信。可能本来就不是乱码?
有没日文好的,这要是正经日文我就尴尬了。
不理解 uchardet 工作原理
投喂目录文件名 ls -1 | uchardet 的结果是 UTF-8
(decode-coding-string
(encode-coding-string "僟儞僕儑儞柤丒媨揳" 'gbk) 'sjis)
;; => #("ダンジョン名・宮殿" 0 9 (charset japanese-jisx0208))
显示 utf-8 没错。
你看到的那些“乱码”,在 windows 上打包之前就“长”那样。而 7z 可以正确处理编码的,那些“乱码”也正好是汉字的生僻字,所以就原样从 gbk 转到 utf-8:
⋊> echo "僟儞僕儑儞柤丒媨揳" | uchardet
UTF-8
要还原 windows (gbk) 场景,才能正确探测到其编码:
⋊> echo "僟儞僕儑儞柤丒媨揳" | iconv -f utf-8 -t gbk | uchardet
SHIFT_JIS
{kind=link}