先介绍一个技巧,就是如何用gdb准确获得断点间代码运行时间,昨天用这个方法分析了emacs windows版本上进程启动相关代码
比如我现在想准确测量emacs源码中 callproc.c第678行到925行的运行时间,
1 先在678行和925行都下断点,程序跑起来,停在678行
2 然后在本地创建一个文件,写入如下内容
python import time
python starttime=time.time()
finish
python endtime=time.time()
python print (endtime-starttime)
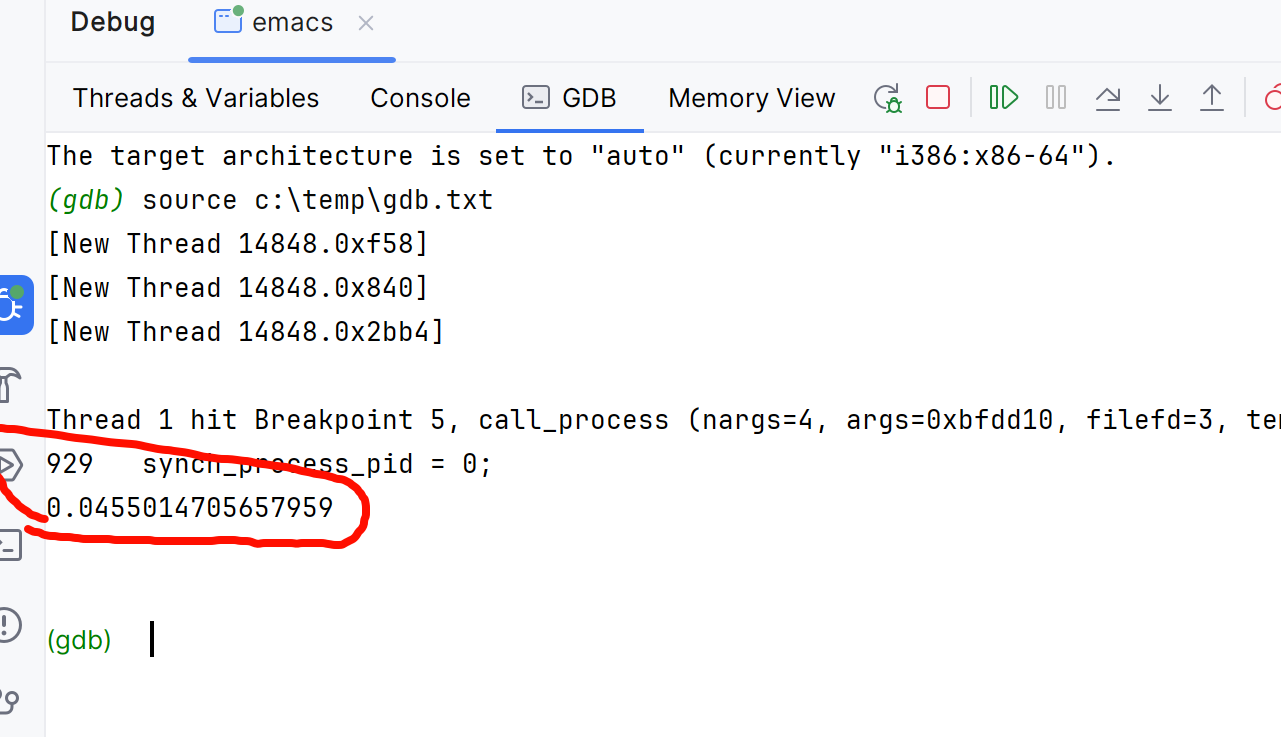
3 在gdb中source这个文件,如下就获得了这段代码的运行时间
4 自己修改脚本,可以灵活测量多种不同的情况,比如一些异步的操作,这里就不细说了
对emacs windows上进程启动的研究
首先是单独做了一些测试,
执行的命令为 git --version ,执行一百次
结果如下(这里参考我的另一个cmdproxy的帖子做了优化,不做的话会慢差不多零点几秒)
1 windows emacs shell-command 7.51s
2 linux emacs shell-command 0.25s
3 windows 下用system函数执行 3.76s
4 linux 下用system函数执行 0.15s
5 windows emacs call-process 5.67s
6 linux emacs call-process 0.07s
然后分析emacs的源码,使用二分法,测量时间,最后可以定位到,执行call-process,主要的时间就花在了callproc.c的678行到924行
678行执行了emacs_spawn,最终是调用了CreateProcess启动进程,
924行执行了wait_for_termination,最终是调用了WaitForMultipleObjects等待这个进程结束
这里也不涉及之前提到的模拟机制。
于是写如下代码进行测试
#include <stdio.h>
#include <stdlib.h>
#include <chrono>
#include <iostream>
#include <windows.h>
using namespace std;
using namespace std::chrono;
void f() {
STARTUPINFO si;
PROCESS_INFORMATION pi;
DWORD status;
TCHAR cmd[MAX_PATH] = TEXT("git.exe --version");
for (int i = 0; i < 100; ++i) {
ZeroMemory(&si, sizeof(si));
si.cb = sizeof(si);
ZeroMemory(&pi, sizeof(pi));
if (!CreateProcess(NULL, cmd, NULL, NULL, FALSE, 0, NULL, NULL, &si, &pi))
{
printf("wrong1\n");
return;
}
WaitForSingleObject(pi.hProcess, INFINITE);
GetExitCodeProcess(pi.hProcess, &status);
CloseHandle(pi.hProcess);
CloseHandle(pi.hThread);
}
}
int main() {
auto t0 = std::chrono::steady_clock::now();
f();
auto t1 = std::chrono::steady_clock::now();
cout << nanoseconds{t1 - t0}.count() << "ns\n";
std::this_thread::sleep_for(1s);
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(t1 - t0).count() << "ms\n";
}
最终也花了3秒左右,网上也查了不少资料,都没啥办法,已经是最简化的代码了。看来这块没啥办法了。