之前看到 PEG 这套理论有专门的论文支撑,挺期待这个新功能的,晚上尝试使用了一下,结果文档很简陋呀,个别 api 我试了很长时间都没有找到能够正确运行的写法。比如 define-peg-ruleset,以及使用 with-peg-rules 定义了规则之后,如何通过 funcall 来调用等。
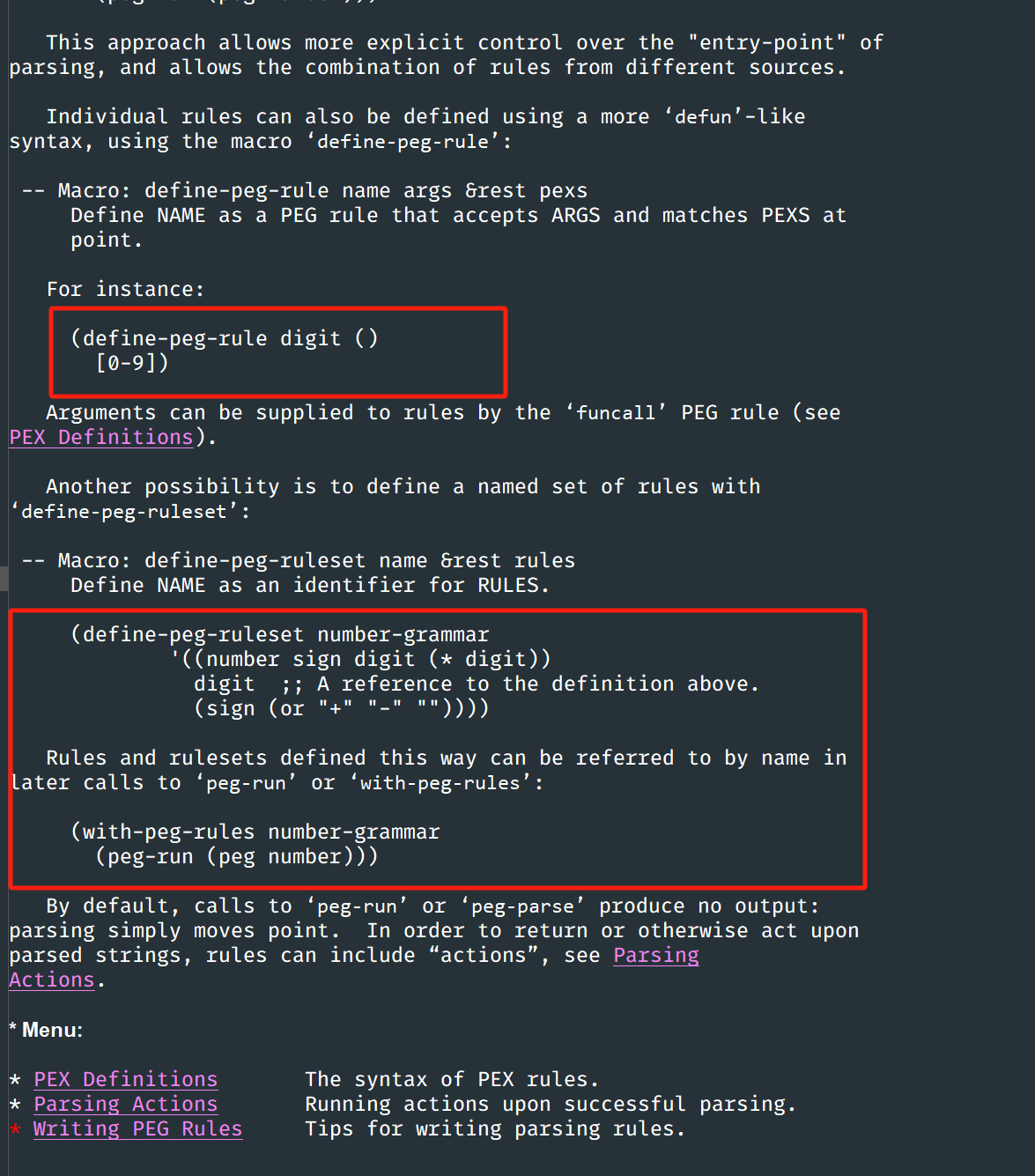
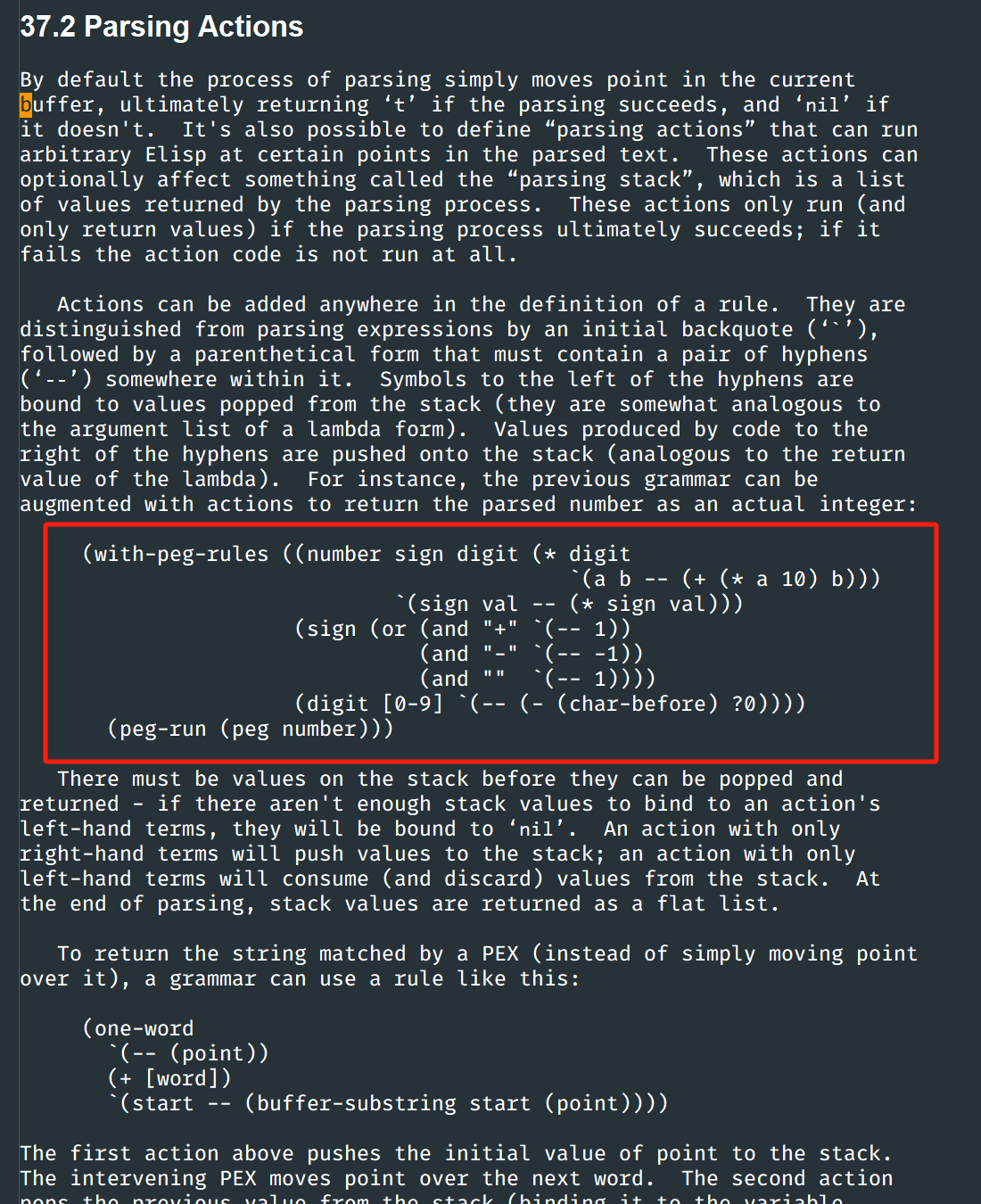
下面是官方文档中的例子:
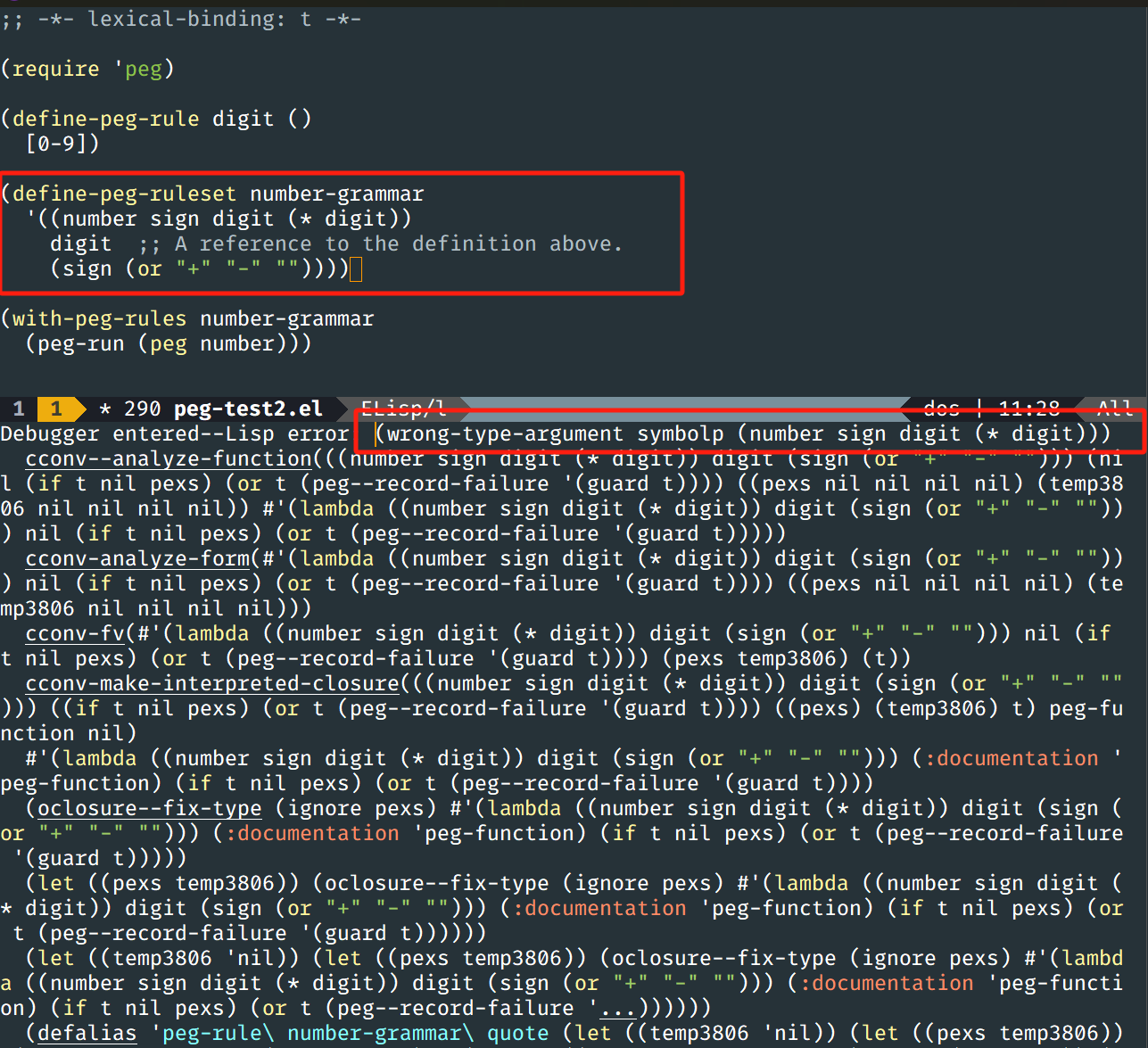
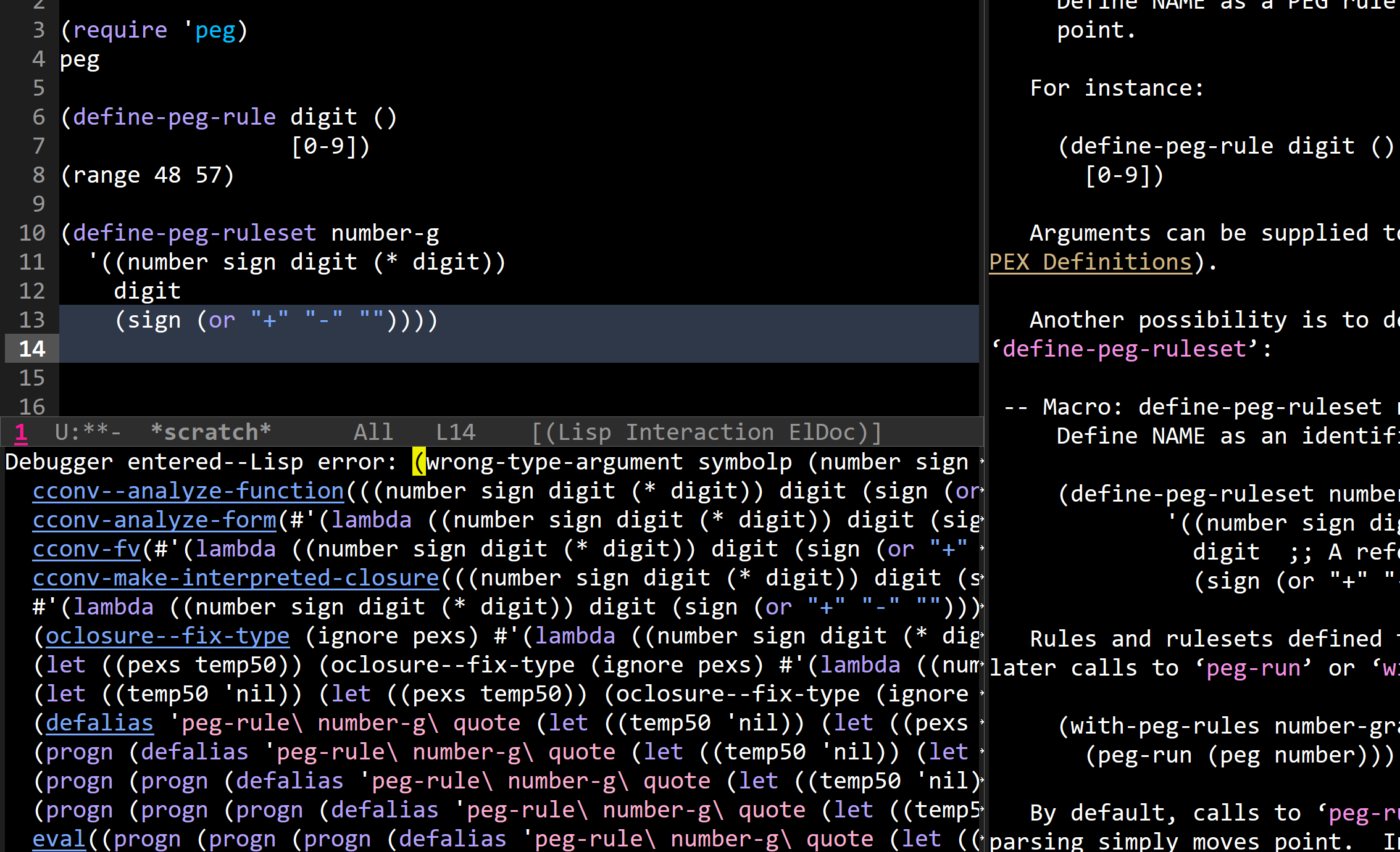
原原本本的运行报错:
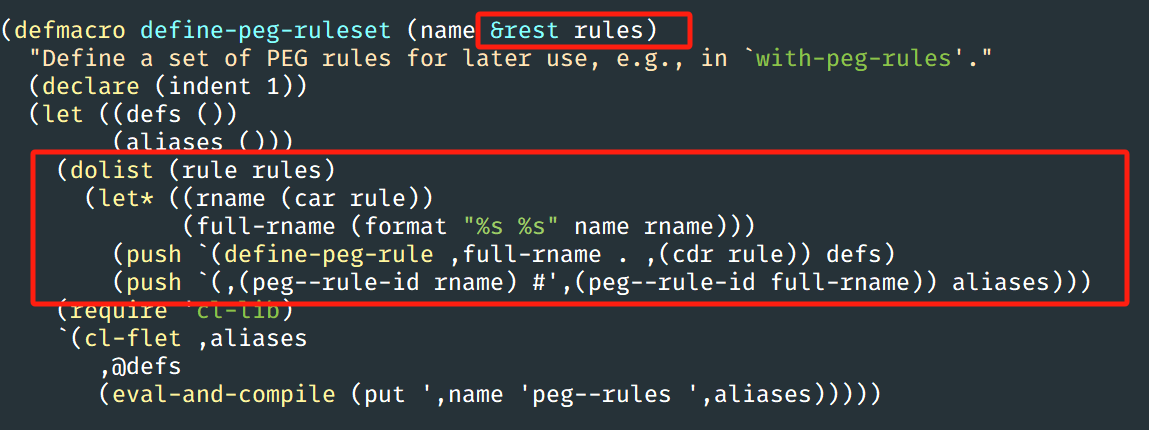
然后我就去看源码:
这个宏的 rules 参数明明就是变长的,而非一个列表,你官方的例子里面怎么写成了列表,可不就报错了嘛
'((number sign digit (* digit))
digit ;; A reference to the definition above.
(sign (or "+" "-" "")))
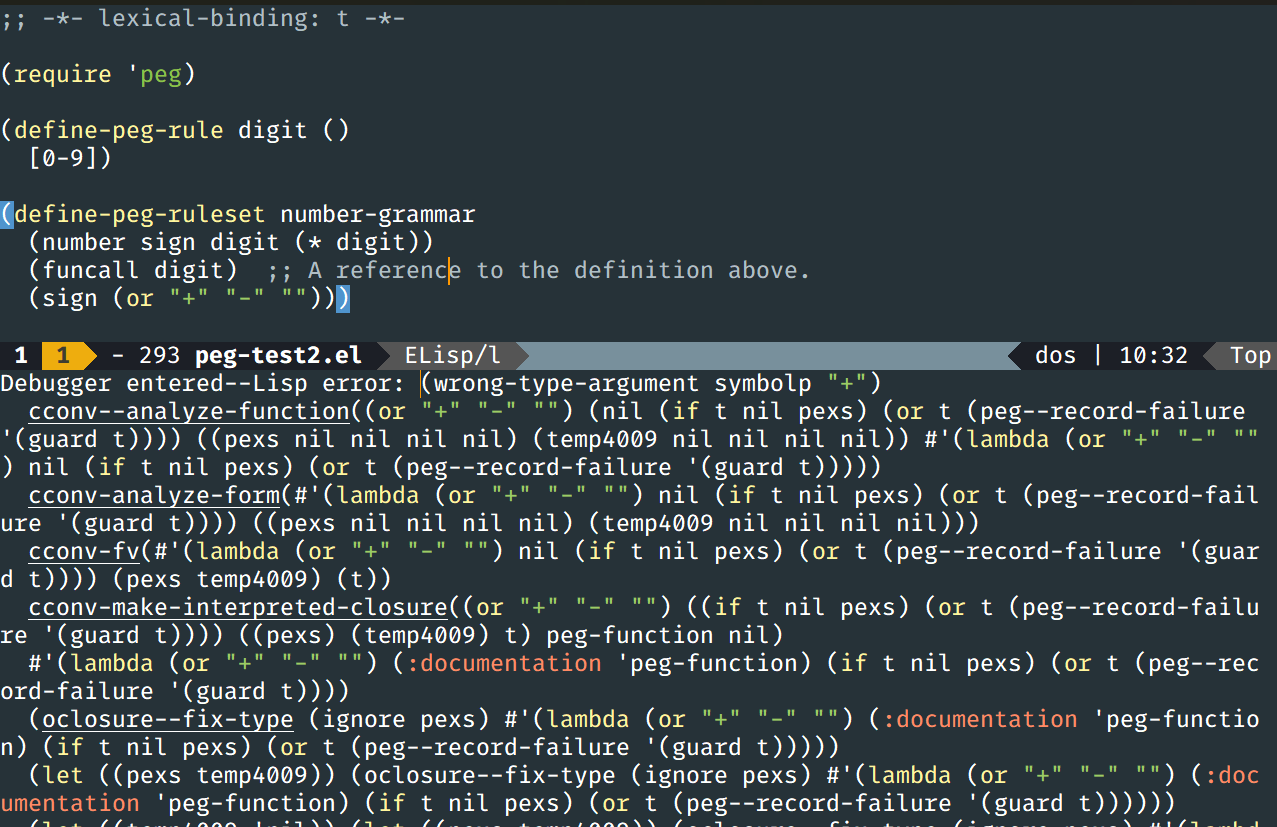
然后我尝试,改为可变参数的写法,仍然无法解决
还有就是关于 action 部分的内容,虽然没有低级错误,但是对于这种设计我觉得并不好,暴露堆栈的概念对于使用者来说并不友好,而且设计的语法格式很怪异,我花了好一会时间才理解它是怎么用的。
我以前一直以为官方的包质量是有保证的,至少经过了严格测试才发布出来的,然而… 大家怎么看?
4 个赞
wwwwww,之前也折腾过,几乎没有文档只能看注释。
蚌埠住了  我想想到底是什么问题,顺便可以报个 bug。
我想想到底是什么问题,顺便可以报个 bug。
我最近在尝试用这个库写 CSS parser 然后写个 CSS minify tool 出来,正好水一篇介绍用法的文章。
3 个赞
在源码开头的文档里面找到了正确的用法:
(define-peg-ruleset myrules
(sign () (or "+" "-" ""))
(digit () [0-9])
(nat () digit (* digit))
(int () sign digit (* digit))
(float () int "." nat))
不知道是官方文档是没有及时更新还是什么原因。
5 个赞
大佬直接看源码开头的注释,里面有一些例子,可以运行。
2 个赞
再纠正一个文档没有表述清楚的地方
‘(any)’
Matches any single character, as the regexp ".".
文档说 (any) 这个表达式类似正则里面的 ‘.’,表示匹配任意字符。众所周知,elisp的正则里的 ‘.’ 是不能匹配换行符的,而 PEG 中的 (any) 是包括换行符的。
1 个赞
感觉小问题不少…
define-peg-rule 的缩进有问题,应该写 (declare (indent 2)) 而不是 1,暂时只能这么干:
(setf (get 'define-peg-rule 'lisp-indent-function) 2)
2 个赞
哈哈,这个问题我也发现了,我是这么干的:
(put 'define-peg-rule 'lisp-indent-function 'defun)
和你的 setf 效果一样的
3 个赞
大佬,你研究出来带参数的规则,是如何调用的了吗,我试了好久也没搞明白
Kinney
10
终于成功了 文档要是能给个完整的例子,也不用这么折腾,,
(define-peg-ruleset myrules
(sign () (or "+" "-" ""))
(digit () [0-9])
(nat () digit (* digit))
(int () sign digit (* digit))
(float () int "." nat)
(not-char (peg) (and (not (funcall peg)) (any)))
(not-char+ (char) (+ (not-char char))))
;; 从当前位置匹配所有非 "[" 位置的字符。
(with-peg-rules (myrules)
(peg-run (peg (not-char+ (peg "[")))))
最后两个规则:not-char 用来匹配非参数的单个字符;not-char+ 用来匹配非参数的多个字符;其中 not-char+ 复用了 not-char 的规则。
3 个赞
SPQR
12
缩进不如用SMIE,内置很多major-mode都在用,比较稳定,PEG感觉像是给font-lock用的
Kinney
14
简单说就是:按照预先定义的规则来匹配和操作文本,类似正则表达式。官方文档说它:
PEGs are more expressive than regexps and potentially easier to use.
解析表达式文法(Parsing Expression Grammars,PEG)是一种用于描述语法规则的形式化工具,其核心作用是定义语言的结构并指导解析器如何将输入文本转换为结构化的语法树 。与传统的正则表达式和上下文无关文法(CFG)相比,PEG在表达能力、语法简洁性和实现效率上具有独特优势。
我觉得它最大的价值在语法怪异的 action 部分,就是对部分匹配到文本提供了灵活操作的机制。具体有什么用处还有待发掘,毕竟这是一个偏底层的包。可能需要再此基础上做进一步的封装才更好用。
www、中午睡觉去了。
由于某个规则要调用函数,它接受的也只能是函数,所以要包一层 peg 才行。除了你上面的用 with-peg-rules ,分别定义 define-peg-rule 然后套起来用也行:
(define-peg-rule minifycss--comment ()
"/*" (* (not "*/") (any)) "*/")
(define-peg-rule two (x)
(funcall x) (funcall x))
(with-temp-buffer
(insert "/* *//**/")
(goto-char (point-min))
(peg-run (peg (two (peg minifycss--comment)))))
;;=> t
(with-temp-buffer
(insert "/* *//**")
(goto-char (point-min))
(peg-run (peg (two (peg minifycss--comment)))))
;;=> nil
peg-parse 看上去似乎不用这些 peg 来包装,然而:
(with-temp-buffer
(insert "/* *//**/")
(goto-char (point-min))
(peg-parse (two minifycss--comment)))
;; => t
(with-temp-buffer
(insert "/**/") ;; single comment!
(goto-char (point-min))
(peg-parse (two minifycss--comment)))
;;=> t
以下 peg-parse 似乎能够正常工作,但这似乎就没有 peg-parse 的便利性了:
(with-temp-buffer
(insert "/* *//**/")
(goto-char (point-min))
(peg-parse (peg (two (peg minifycss--comment)))))
;;=> t
(with-temp-buffer
(insert "/* *///")
(goto-char (point-min))
(peg-parse (peg (two (peg minifycss--comment)))))
;;=> ERROR
感觉这种用法和 peg-parse 用起来似乎比较容易犯错… 也许这是一个 bug,因为注释是这么写的:
;;;; Rule argument and indirect calls:
;;
;; Rules can take arguments and those arguments can themselves be PEGs.
;; For example:
;;
;; (define-peg-rule 2-or-more (peg)
;; (funcall peg)
;; (funcall peg)
;; (* (funcall peg)))
;;
;; ... (peg-parse
;; ...
;; (2-or-more (peg foo))
;; ...
;; (2-or-more (peg bar))
;; ...)
感觉也许需要一点研究然后再报个 bug 
Kinney
16
看源码, peg-parse 的用法应该是这样的:
(with-temp-buffer
(insert "test:/* *//**/")
(goto-char (point-min))
(peg-parse (any-name prefix (two (peg minifycss--comment)))
(prefix "test:")))
参数仍然是多个 PEX 表达式,最终是取第一个表达式的第一个symbol: any-name 作为函数的名字组装规则。只能说是比 (peg-run (peg … )) 的写法稍微简洁了一些,但是不多 。
peg-parse 也不支持匹配成功或失败时的回调函数,而且搜索失败就会报错,不知道为啥要这样设计?有时候即使搜索成功也会有 warning。
原来如此,但我感觉这不管是在文档还是注释中都不怎么直观,我想想怎么说去 
Kinney
18
这块注释里面的例子确实是错的,让人误以为是
;;; 错误的例子
(with-temp-buffer
(insert "/* *//**/")
(goto-char (point-min))
(peg-parse (two minifycss--comment)))
这种写法。
3 个赞
Kinney
19
我又仔细研究了一下源码, peg-parse 宏是想兼容 with-peg-rules 和 peg-run 两种用法,根据参数形式不同来确定使用哪种。
with-peg-rules 的参数形式:每个列表的第一个参数是变量名,后面是多个 pexs,变量可以引用;我称它为 rules 形式peg-run 的参数形式是:多个 pexs,这种就是 pexs 形式
如果第一个参数都是 cons,没法区别这两种。当第一个参数不是cons时,就是使用 pexs 格式,否则是 rules 格式。
下面的第二个例子,第一个参数写成空字符串就可以使用啦。
;; peg-parse 参数为 rules 形式
(with-temp-buffer
(insert "avioeuiewrhvi/* *//**/vhioehvioe")
(goto-char (point-min))
(peg-parse (text (+ (not two-comments) (any)) two-comments)
(two-comments (two (peg minifycss--comment)))))
;; peg-parse 参数为 pexs 形式,第一个参数不能为 cons
(with-temp-buffer
(insert "/* *//**/")
(goto-char (point-min))
(peg-parse "" (two (peg minifycss--comment))))
2 个赞
嗯,这就说的通了,如果第一个元素是 list 形式就表示想要使用 (with (xx1 xx2) (peg-run xx1)) 之类的,如果第一个元素是符号就表示用 (and 把 PEX 列表连起来:
(peg-parse p1 p2 p3)
;; expands
(peg-run (peg p1 p2 p3 ...))
但是这些信息应该在文档里面给出来  ,果然我还是应该再发个邮件
,果然我还是应该再发个邮件
2 个赞