最近对中文输入和搜索相关的配置做了一些调整,配合使用 emacs-rime 和 rime, 基本达到了自己想要的效果:
-
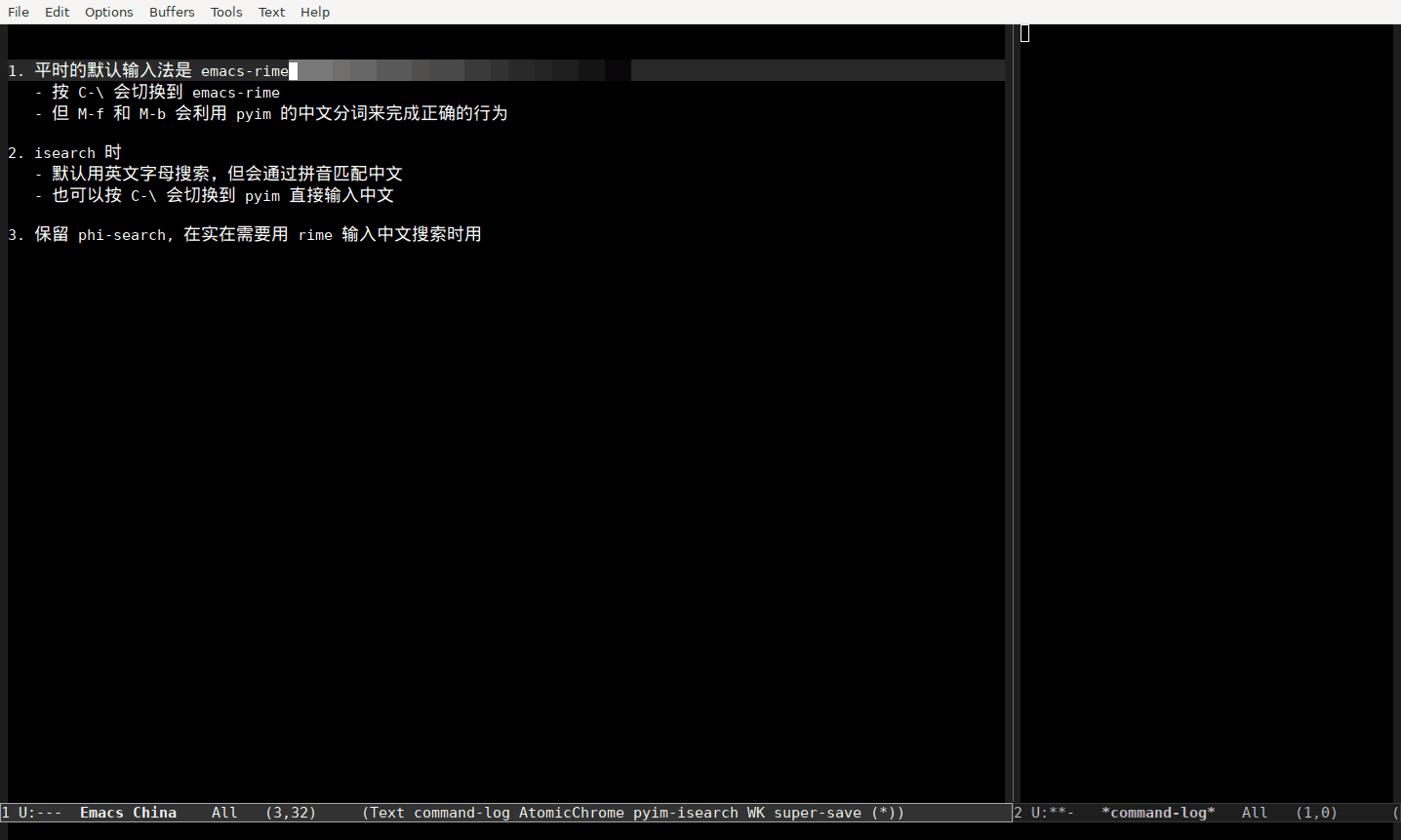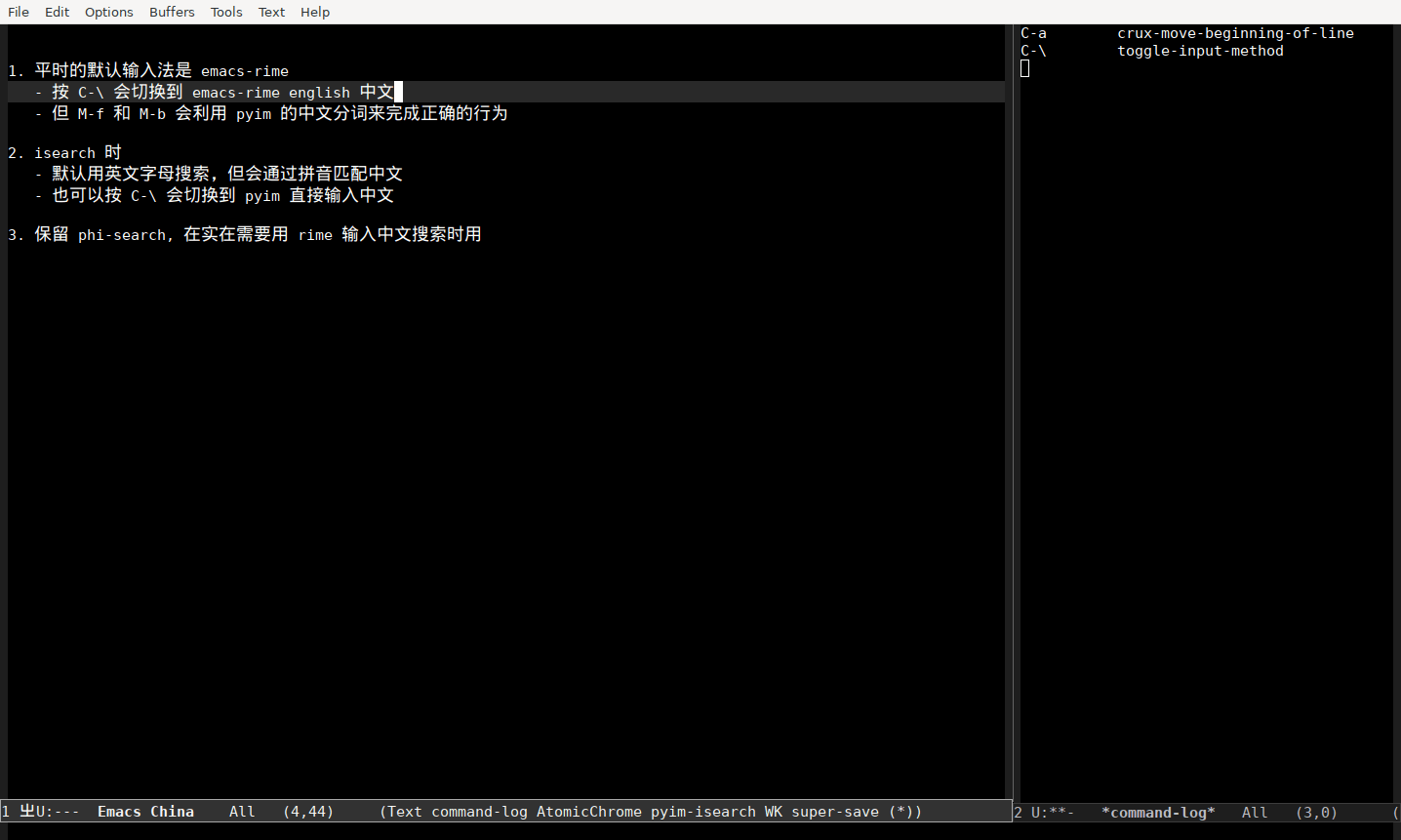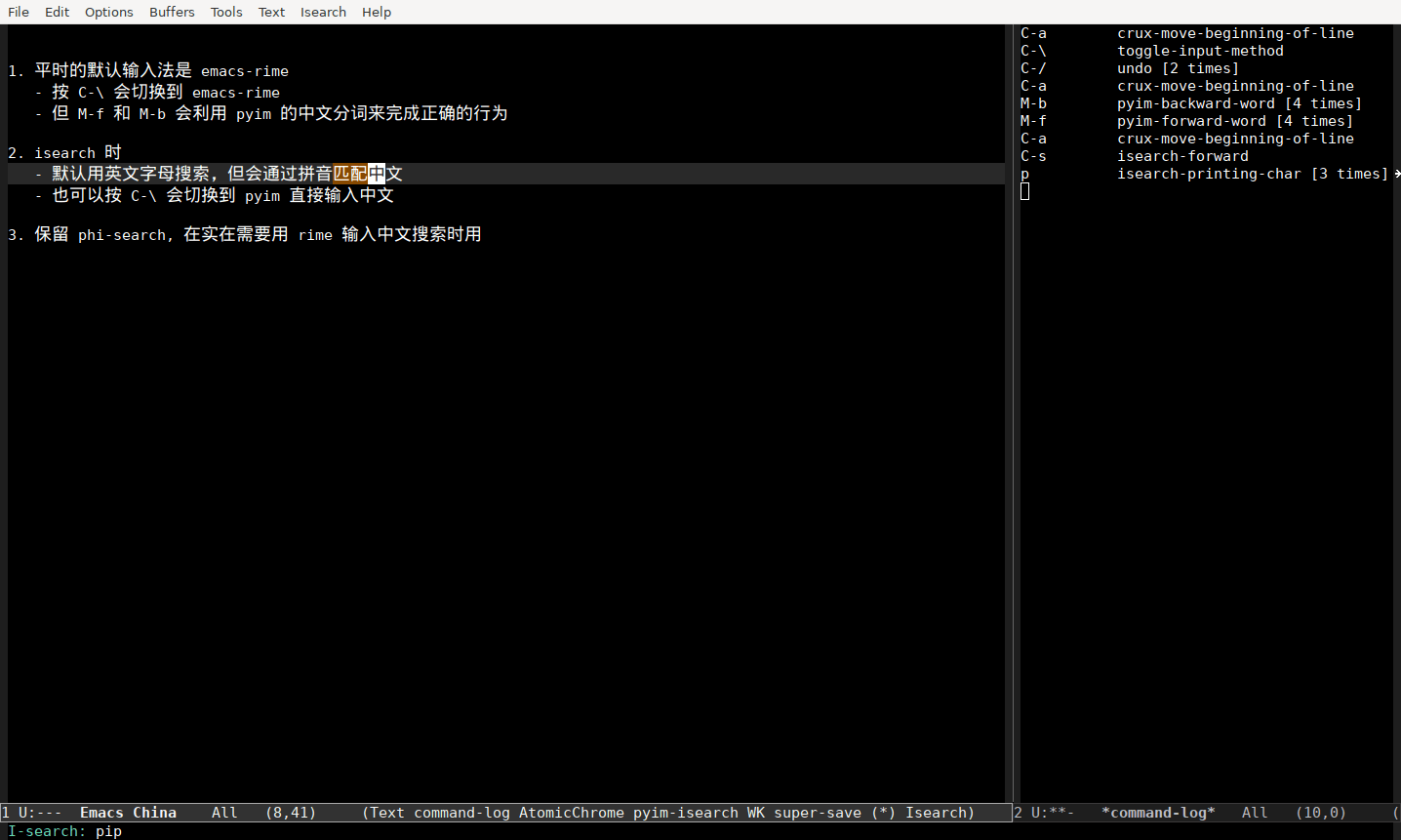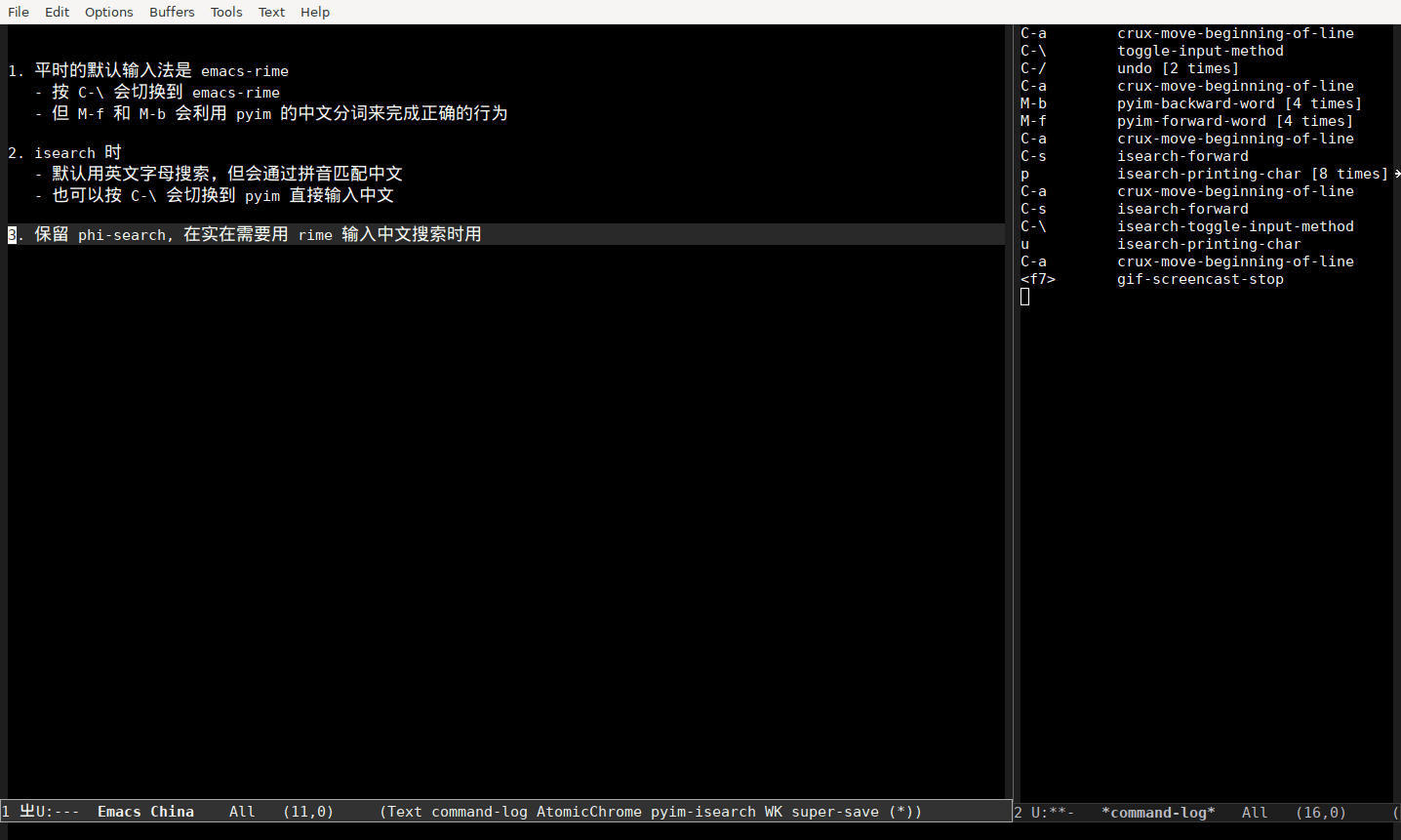
平时的默认输入法是 emacs-rime
- 按 C-\ 会切换到 emacs-rime
- 但 M-f 和 M-b 会利用 pyim 的中文分词来完成正确的行为
-
isearch 时
- 默认用英文字母搜索,但会通过拼音匹配中文
- 也可以按 C-\ 会切换到 pyim 直接输入中文
-
保留 phi-search, 在实在需要用 rime 输入中文搜索时用
-
switch buffer 时,也可以通过拼音字母进行匹配
展示 1、2 (4 与 2 同理)
问题:isearch 和 ivy 用拼音字母匹配时,有时会有些奇怪的行为,比如 pyim-cregexp-ivy 导致 counsel-M-x 等命令不正常 · Issue #461 · tumashu/pyim · GitHub (我目前是设置了快捷键来 toggle 拼音字母匹配)
引玉:
- 更简单的实现这些功能的方法
- 大家的「中文输入和搜索相关的配置」
实现过程
最初的想法是:
- 用 pyim 作为备用中文输入法,因为无需外部依赖
- 用 emacs-rime 作为主力中文输入法,因为 pyim 不支持我用的「自然码」(带形码的双拼方案),而且这样我在 emacs 内外的输入体验也比较一致(我在电脑上用 rime, 在手机上用 trime)
但实际使用的过程中,phi-search (emacs-rime 无法在 isearch 中使用,但可以在 phi-search 中使用)的缺点对我而言较为明显:
- 有时会出现无法退出的问题
- 搜索时不高亮显示当前行,即便开了 global-hl-line-mode
于是想到或许可以合用 pyim 与 emacs-rime:
- 平时默认的输入法是 emacs-rime
- C-s/r 调用 isearch 时,使用 pyim
- 保留 phi-search 作为备用,绑定到 s-s s/r
兼用 pyim 还有一些好处:
- isearch 和 switch-buffer 时,可以用拼音字母来做匹配,比如 qquv 既能匹配 qquv 也能匹配「秋水」、「泅水」之类的,因而也不用再引入 pinyin-search(比起拼音首字母匹配,我更愿意多输入一些字符来做更精确的匹配,可能是因为我用双拼,这样做的代价比全拼小得多)
- 可以利用 pyim 的中文分词功能,实现中文中正确的 forward-word 和 backward-word,因而也不用再引入 jieba (虽然分词效果可能不及 jieba)
阅读了相关文档和源码(按 C-\ 切换输入法的逻辑略复杂)后,通过两个 add-hook 实现了想要的功能:
(add-hook 'isearch-mode-hook
(lambda ()
(progn
(setq rws-input-method-before-isearch current-input-method
rws-default-input-method-before-isearch default-input-method)
(deactivate-input-method)
(setq default-input-method "pyim")
(setq input-method-history '("pyim")))))
(add-hook 'isearch-mode-end-hook
(lambda ()
(progn
(activate-input-method rws-input-method-before-isearch)
(setq default-input-method rws-default-input-method-before-isearch)
(setq input-method-history (list default-input-method))))))
此外,我还给 pyim 添加了 ziranma scheme, 这样输入和搜索就都是用一套双拼方案了
完整配置 (WIP,比较杂乱)
(use-package rime :ensure t
:bind
(:map
rime-mode-map
("s-r" . #'rime-force-enable)
("s-R" . #'rime-inline-ascii))
:config
(setq default-input-method "rime"
rime-show-candidate 'posframe)
(defun rws-rime-predicate-after-most-ascii-char-p ()
"If the cursor is after a ascii character expect # [ \ ]"
(and (> (point) (save-excursion (back-to-indentation) (point)))
(let ((string (buffer-substring (point) (max (line-beginning-position) (- (point) 80)))))
(string-match-p "[a-zA-Z0-9\x21-\x22\x24-\x2f\x3a-\x40\x5e-\x60\x7b-\x7f]$" string))))
(defun rws-rime-predicate-space-after-most-cc-p ()
"If cursor is after a whitespace which follow a non-ascii (except `→') character."
(and (> (point) (save-excursion (back-to-indentation) (point)))
(let ((string (buffer-substring (point) (max (line-beginning-position) (- (point) 80)))))
(and (not (string-match-p "→ +$" string))
(string-match-p "\\cc +$" string)))))
(defun rws-rime-predicate-punctuation-space-after-ascii-p ()
"If input a punctuation after a ascii charactor with whitespace."
(and (rime-predicate-current-input-punctuation-p)
(rime-predicate-space-after-ascii-p)))
(setq rime-disable-predicates
'(rime-predicate-prog-in-code-p
rws-rime-predicate-punctuation-space-after-ascii-p
rime-predicate-punctuation-line-begin-p
rime-predicate-current-uppercase-letter-p
rws-rime-predicate-space-after-most-cc-p
rws-rime-predicate-after-most-ascii-char-p))
(use-package phi-search :ensure t
:bind
(("s-s s" . #'phi-search)
("s-s r" . #'phi-search-backward))))
(use-package pyim :ensure t
:config
(use-package pyim-basedict :ensure t
:config
(pyim-basedict-enable))
(use-package pyim-cregexp-utils
:config
(setq ivy-re-builders-alist '((t . pyim-cregexp-ivy))))
(use-package pyim-cstring-utils
:bind
(("M-f" . #'pyim-forward-word)
("M-b" . #'pyim-backward-word)))
(use-package posframe :ensure t)
(pyim-scheme-add
'(ziranma
:document "自然码双拼(不含形码)方案"
:class shuangpin
:first-chars "abcdefghijklmnopqrstuvwxyz"
:rest-chars "abcdefghijklmnopqrstuvwxyz"
:prefer-triggers nil
:cregexp-support-p t
:keymaps
(("a" "a" "a")
("b" "b" "ou")
("c" "c" "iao")
("d" "d" "uang" "iang")
("e" "e" "e")
("f" "f" "en")
("g" "g" "eng")
("h" "h" "ang")
("i" "ch" "i")
("j" "j" "an")
("k" "k" "ao")
("l" "l" "ai")
("m" "m" "ian")
("n" "n" "in")
("o" "o" "uo" "o")
("p" "p" "un")
("q" "q" "iu")
("r" "r" "uan")
("s" "s" "iong" "ong")
("t" "t" "ue" "ve")
("u" "sh" "u")
("v" "zh" "v" "ui")
("w" "w" "ia" "ua")
("x" "x" "ie")
("y" "y" "ing" "uai")
("z" "z" "ei")
("aa" "a")
("an" "an")
("aj" "an")
("ai" "ai")
("al" "ai")
("ao" "ao")
("ak" "ao")
("ah" "ang")
("ee" "e")
("ei" "ei")
("ez" "ei")
("en" "en")
("ef" "en")
("er" "er")
("eg" "eng")
("oo" "o")
("ou" "ou")
("ob" "ou"))))
(setq pyim-default-scheme 'ziranma
pyim-page-tooltip 'posframe
pyim-page-length 9
pyim-fuzzy-pinyin-alist nil)
(pyim-isearch-mode t)
(add-hook 'isearch-mode-hook
(lambda ()
(progn
(setq rws-input-method-before-isearch current-input-method
rws-default-input-method-before-isearch default-input-method)
(deactivate-input-method)
(setq default-input-method "pyim")
(setq input-method-history '("pyim")))))
(add-hook 'isearch-mode-end-hook
(lambda ()
(progn
(activate-input-method rws-input-method-before-isearch)
(setq default-input-method rws-default-input-method-before-isearch)
(setq input-method-history (list default-input-method))))))