有时候需要对多个pdf文件进行文本搜索,选择文件后跳转到pdf指定页面。尝试过以下几个方案。
consult + ripgrep-all, 代码来自这里
;; helper function for ripgrep-all
(defun consult--ripgrep-all (&optional dir initial)
"Search with `rga' for files in DIR where the content matches a regexp.
The initial input is given by the INITIAL argument. See `consult-grep'
for more details."
(interactive "P")
(consult--grep "Ripgrep-all" #'consult--ripgrep-make-builder dir initial))
;;;###autoload
(defun consult-ripgrep-all ()
;; Bind to a key
(interactive)
(let ((consult-ripgrep-args "rga --null --line-buffered --color=never --max-columns=1000 --path-separator / --smart-case --no-heading --line-number ."))
(consult--ripgrep-all)))
搜索后的呈现形式还是挺清晰的,每个pdf文件分成一组,每个匹配一行,唯一的问题是按回车不支持跳转到pdf文件相应的页面。不知道怎么提取文件路径和页码信息利用embark实现pdf跳转。
consult-recoll
Recoll 需要预先索引给定的文件夹,我通常知道在哪个文件夹搜索,如果索引所有含有pdf文件的文件夹,筛选搜索结果的时候不太方便。
pdfgrep
这个支持pdf跳转到指定的页码,不过搜索结果的呈现形式不太好看,每个匹配一行,这一行里面前半部分是文件路径,后面是匹配的文本,但文件路径可以太长,后面的文本匹配部分容易看不清。但又不能隐藏文件名,因为需要配合文件名判断候选项。
blink-search
blink-search有一个rga的后端,不过大佬的插件感觉用起来有门槛,在doom-emacs光安装就花了些功夫。
(package! blink-search
:recipe (:host github
:repo "manateelazycat/blink-search"
:files ("*.py" "*.el" "core" "backend" “icons”)))
也有一些问题,搜索结果没有像consult那样分组,每一条匹配前半部分是文件路径,后半部分是匹配的文本,看起来不清晰,筛选也不太方便,consult按C+M+j可以直接跳到下一个分组。另外blink-search跳转到pdf好像有问题,如果候选项没有在第一屏显示,后面按C+n选中候选项,按回车好像无法跳转。
1 个赞
可以给blink-search报个issue,我有时间改进一下。
需要安装pdf-tools, 运行M-x my-pdfgrep-in-directory, 只用了completing-read,所以可以和helm/ivy/counsult等框架自由搭配,
(defvar my-pdfgrep-program "pdfgrep"
"Pdf grep program.")
(defvar my-pdfgrep-options "-H -n"
"Pdf grep program options.")
(defvar my-pdfgrep-ignore-case t
"Ignore case when grepping pdf.")
(defun my-pdfgrep-in-directory ()
"Grep pdf files in current or specific directory."
(interactive)
(let* ((root (read-directory-name "Directory: "))
(default-directory root)
(case-fold-search t)
(keyword (read-from-minibuffer "Keyword: " (thing-at-point 'symbol)))
(cmd (format "%s %s %s -r %s"
my-pdfgrep-program
my-pdfgrep-options
(if my-pdfgrep-ignore-case "-i" "")
keyword))
(lines (split-string (shell-command-to-string cmd) "[\r\n]+" t))
path
page
text
cands
selected)
(cond
((and lines (> (length lines) 0))
(dolist (line lines)
(when (string-match "^\\(.+\\.pdf\\):\\([0-9]+\\):\\(.*\\)$" line)
(setq path (match-string 1 line))
(setq page (match-string 2 line))
(setq text (match-string 3 line))
(push (cons (format "%s:%s: %s"
(file-name-base path)
page
(string-trim text))
(list path (string-to-number page) text))
cands)))
(setq cands (nreverse cands))
(when (setq selected (completing-read (format "Grep in %s:" root)
cands))
(setq selected (cdr (assoc selected cands)))
(find-file (nth 0 selected))
(unless (featurep 'pdf-tools) (require 'pdf-tools))
(pdf-view-goto-page (nth 1 selected))
(pdf-isearch-hl-matches nil (pdf-isearch-search-page keyword) t)))
(t
(message "Found nothing.")))))
大佬都是从头自己写函数
你说的 blink-search 跳转的问题已经修复了。
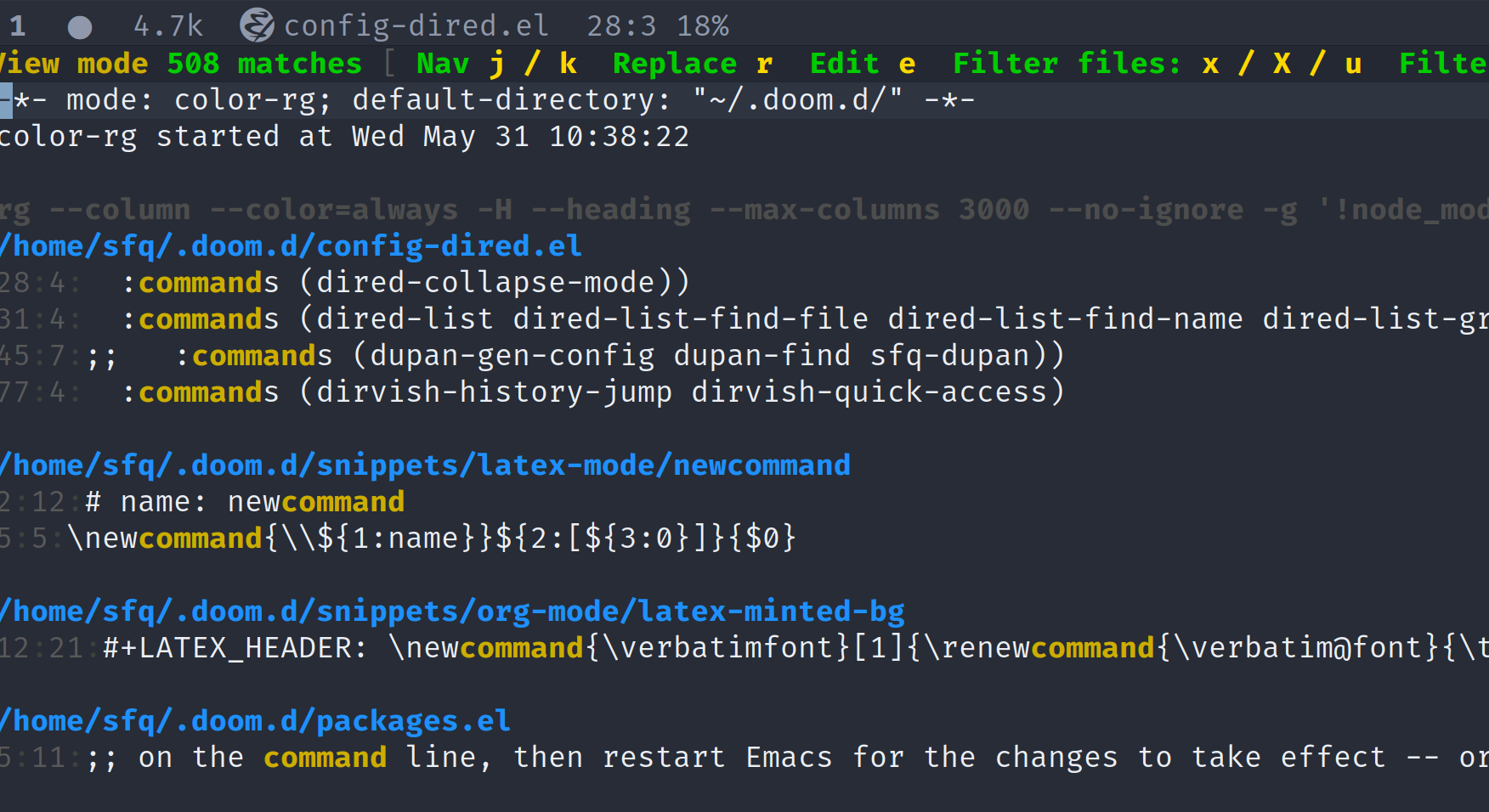
如果你要分组的话, 我觉得可以改造一下 color-rg.el 让其支持 rga, color-rg的交互模式应该是你期望的。
之前听过color-rg,不过以为侧重重构,尝试了一下,不知道加上rga是否合适。
另外说一下个人试用感受,“菜单栏”有一些快捷提示挺好的。文件之间的空行可能是刻意留的吧,不过我个人感觉有点浪费空间。另外,view mode的快捷键
h和
l的设定对于我(evil用户)来说不太自然,
j和
k对应上和下,没什么问题,
h和
l对应左和右,但
h绑定jump to next file,
l绑定jump to previous file,感觉还是有点不太自然,相当于左(
h)对应下(next file),右(
l)对应上(previous file)。当然这都是个人使用习惯问题。
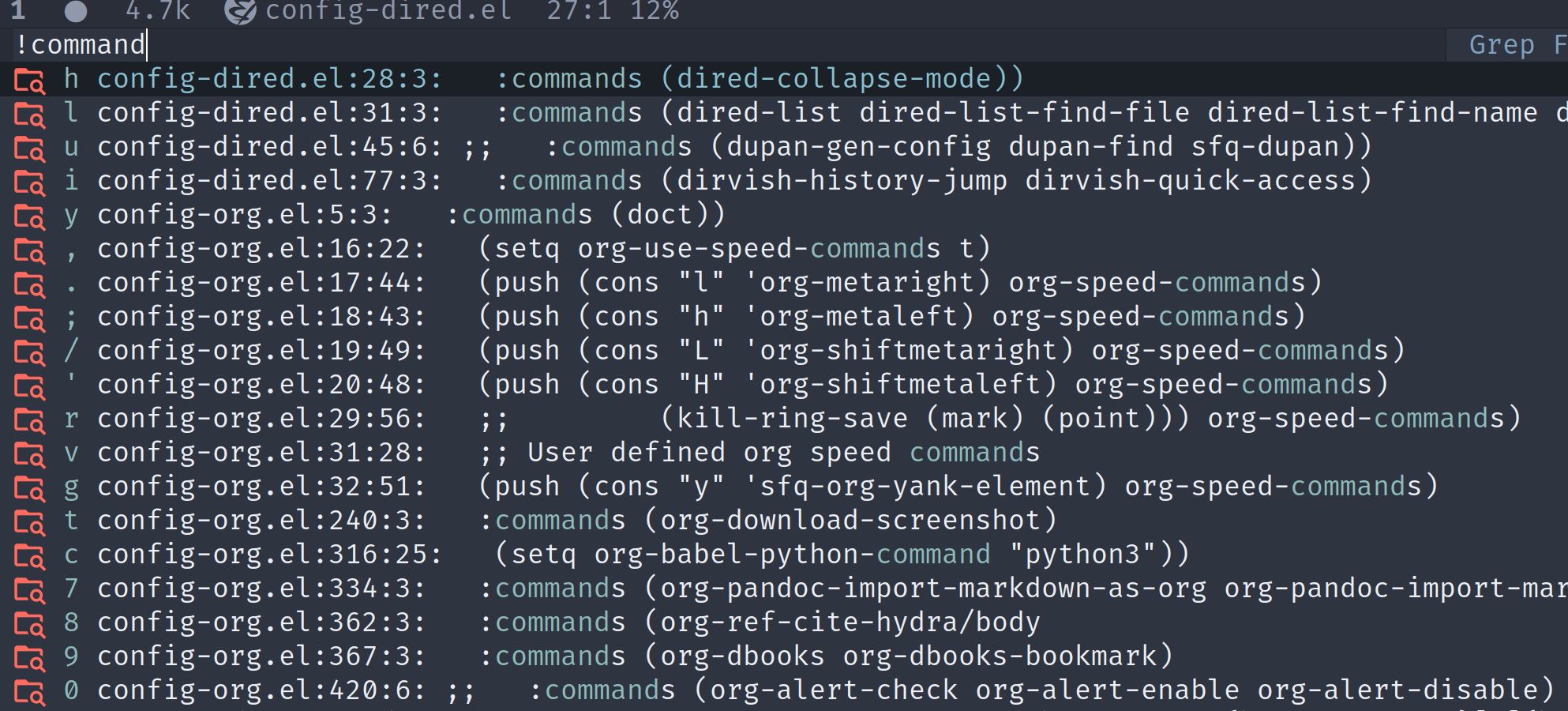
blink-search 的grep结果如下,目前显示还清晰,不过如果文件名比较长,或者文件夹层数较深,匹配的文本就显示不全。
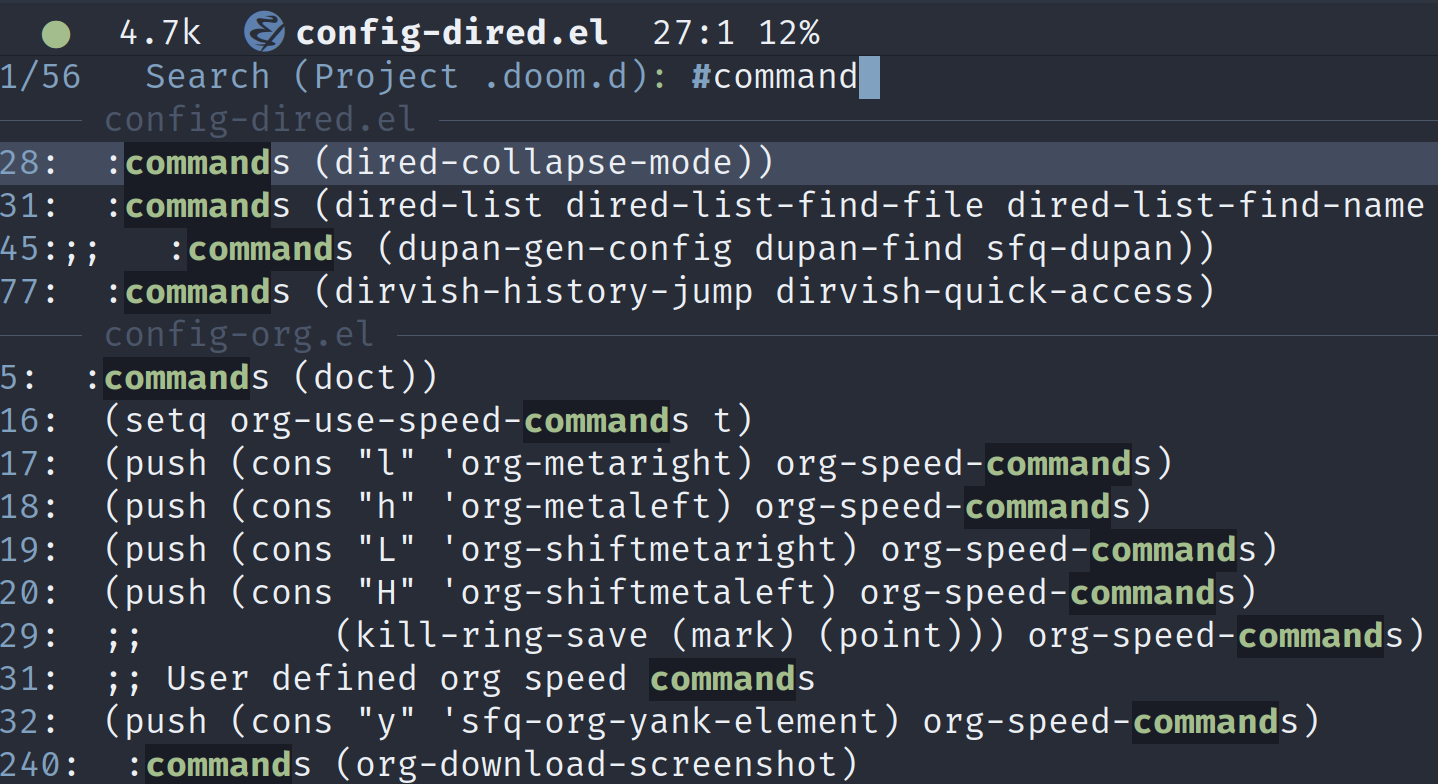
这是consult grep的结果,是分组显示的,还是挺清晰的。
color-rg 的默认按键你可以改。
blink-search 是用于替换 helm 的设计, 它的主要作用是快速融合不同的搜索后端, 它的设计不适合再进行文件分组, 那样会把这个搜索框架搞的过于复杂。
你要的效果应该是 color-rg 加上对 rga 后端支持, 同时 rga 启用时, 重构的功能要禁用。
book
2023 年7 月 23 日 23:08
11
color-rg是否可以设置如ripgrep中-A, --after-context 显示匹配内容后的 行和-B, --before-context 显示匹配内容前的 行?
mafty
2023 年7 月 25 日 09:33
12
还有一个比较偷懒的办法是把所有 pdf 拼成一个文件:
gs -dNOPAUSE -sDEVICE=pdfwrite -sOUTPUTFILE=combine.pdf -dBATCH *.pdf
后面就像平常一样开 zathura 或者 pdf-occur 了。
(来自开卷考试的经验)
system
2025 年7 月 24 日 09:33
13
此话题已在最后回复的 730 天后被自动关闭。不再允许新回复。