最近花了些时间为Emacs实现了一个包,eureka,用于在Emacs中使用大模型来进行代码编写,阅读和修改等。不同于ellama和gptel等已有的这些更通用的包,eureka专注于编程方面,而且受aider里repomap启发,借助tree-sitter和lsp的能力,也实现了类似repomap的功能。
既然有了aider(以及aider.el),为什么还要开发一个新的包?原因有几点:第一点也是最主要的点在于,aider不给你确认是否采纳修改的机会,它会直接修改代码文件;第二点是因为aider是一个命令行工具,aider.el是通过comint来集成到Emacs中,用起来不够自然;第三点是aider中要手工添加文件到repo map中从而发送给llm,Emacs中借助lsp可以将部分工作自动化。
一、功能展示
先上俩gif展示一下基本功能。
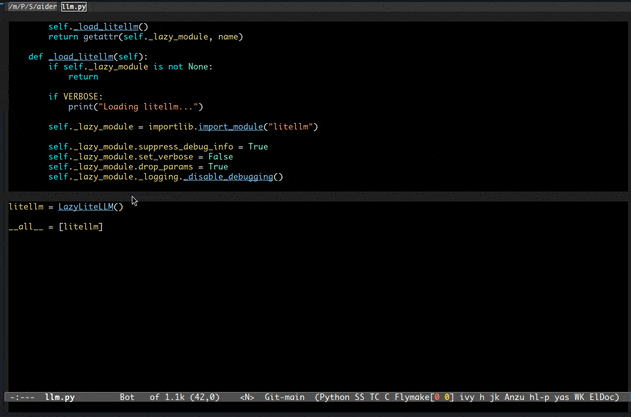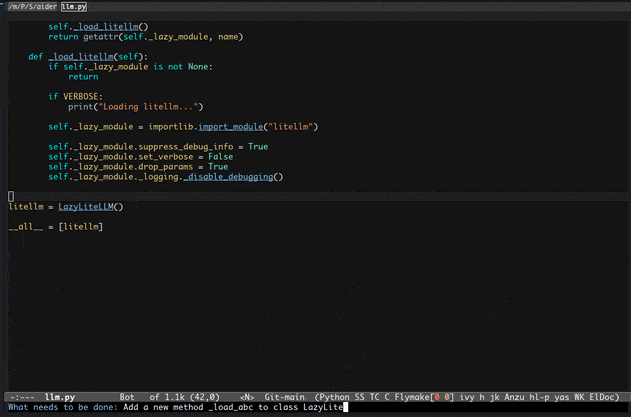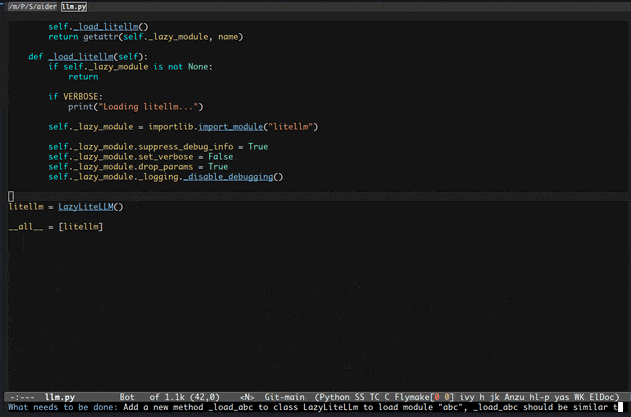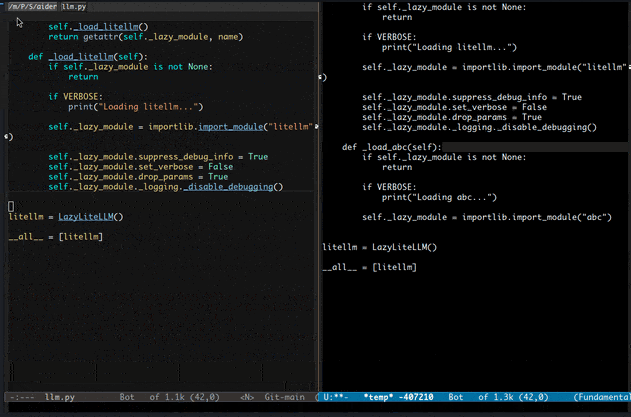
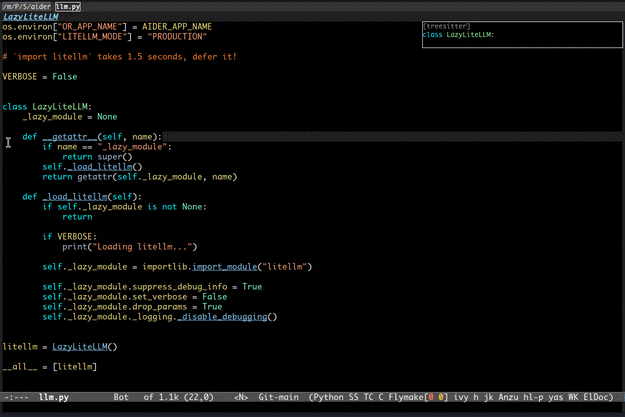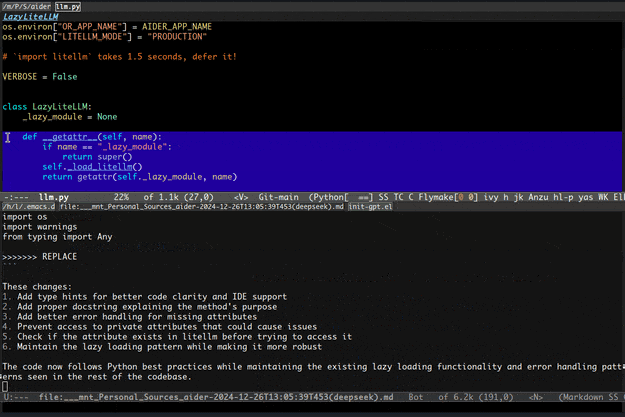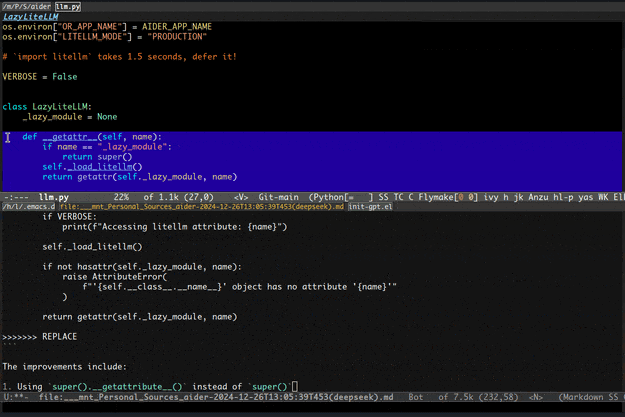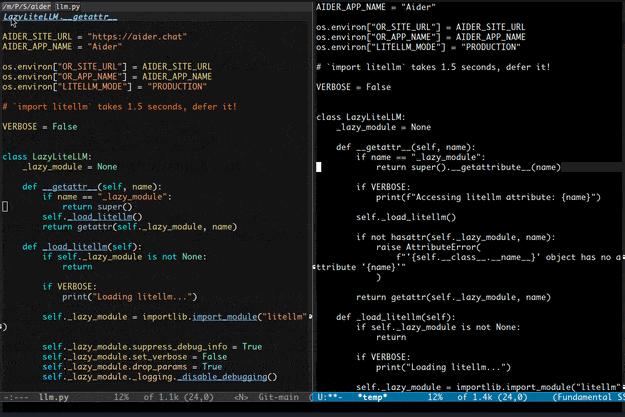
二、功能介绍
首先说明一下,eureka是基于llm这个包,并“借鉴”了ellama的代码(主要是ellama-stream)。感谢这两个项目的开发者。
2.1 project
类似lsp,eureka也有project的概念(使用Emacs内置的project包),也就是说,它只能在某个project中的文件里使用。对于修改单个文件的情形,ellama或者gptel或者其它类似的包都可以。
2.2 repo map的实现
在aider中,repo map是为了给llm提供关于代码的上下文信息,以帮助llm更好地理解代码库,确定如何对代码做修改、在哪儿修改等等(介绍见:这儿)。aider中的repo map包含代码仓库中某些文件的一个列表,以及每个文件的关键信息(像类定义,方法签名以及类成员变量等)。
在eureka中,repo map中的文件有四种,添加方式也各不相同。一种是project级别的,通过手工方式添加;第二种是文件级别的,也是通过手工方式添加的;第三种也是文件级别的,但是是自动确定的;第四种是当前buffer中编辑的文件。对于前三种,发送给llm的都是上面说到的文件关键信息,第四种是当前文件的完整内容。下面详细说明一下第三种是如何利用lsp自动确定,以及前三种的关键信息是如何通过tree-sitter得到的。
2.2.1 通过tree-sitter得到文件关键信息
Emacs已经内置了tree-sitter的支持,只要有对应语言的parser,即便没有对应的ts-mode,只要定义好query pattern,也可以直接解析文件,查询需要的关键信息。下面是java和python的query pattern:
'((python . (("class_definition" (class_definition ":" @context.body @context.surrounding.start body: (_)) @context)
("function_definition" (function_definition ":" @context.body @context.surrounding.start body: (_)) @context)))
(java . (("class_declaration" (class_declaration body: (class_body :anchor "{" @context.surrounding.start _ "}" @context.surrounding.end :anchor) @context.body) @context)
("method_declaration" (method_declaration body: (block :anchor "{" @context.surrounding.start _ "}" @context.surrounding.end :anchor) @context.body) @context)
("field_declaration" (field_declaration declarator: (_) ";") @context))))
解析结果就可以得到需要的信息了。
2.2.2 通过lsp自动确定文件依赖
在eureka中,操作都是从当前文件发起的,自动确定文件依赖也是针对当前文件的(当然这只是目前的实现,理论上并不局限于当前文件)。所谓文件依赖,就是有哪些文件用到了当前文件中定义的关键信息,以及当前文件用到了哪些其他文件中定义的关键信息。这两种信息分别是通过lsp的incoming calls和outgoing calls请求得到的。
在eureka中,默认提供了基于lspce的实现,但并没有绑定lspce,通过`eureka-file-deps-function’可以设置自定义的获取依赖的函数。
2.3 eureka目前提供的命令
2.3.1 eureka-project-code-edit
通用的代码编辑命令,根据需求输入给llm的指令。llm返回的代码修改会通过ediff来展示,可以只合并需要的修改。
2.3.2 eureka-project-code-improve
针对选定区域或者当前buffer的代码,让llm提供优化改进,llm返回的代码修改会通过ediff来展示,可以只合并需要的修改。
2.3.3 eureka-project-code-review
针对选定区域或者当前buffer的代码,让llm进行review,在单独的buffer中展示llm的代码审查结果。
2.3.4 eureka-project-code-explain
解释选定区域的代码或者当前buffer代码。
三、其他说明
目前还存在的一些问题:
-
只用deepseek测试过题外话:deekseek最近刚升级到V3,token输出明显快了很多,根据官方说法,速度是V2版本的3倍。关于代码生成能力,aider的评测结果显示deepseek v3超过claude sonnet 3.5。关于deepseek,最关键的是便宜啊便宜。今天做个自来水,推荐大家使用。
-
目前只支持对python/java代码文件生成skeleton不过这个容易扩展,只要写tree-sitter的query就可以。
-
肯定会存在的一些未知的bug
-
本人对llm的一知半解
总体来说,eureka在一些简单场景下可用了,但还需要继续使用完善。后面一段时间可能还是先摸着aider过河吧。感谢aider!
用豆包生成了一个logo,对没啥审美的我来说,总比我自己画的要好吧。对于开发软件来说,以后有没有代码基础可能没那么重要,有没有逻辑、有没有创造性更为重要。coder们涅槃重生的时代。

最后,上代码。Enjoy!
https://github.com/zbelial/eureka.el
最后的最后,2024马上过去了,希望大家2025年会更好。