其实有两个问题:
1.在citre中作者展示了citre+company的补全我感觉很好看,但是我自己配不出来…我citre peek什么的都是ok的,我也知道company-mode可以自己组合前端后端,我在company-backends变量中将completion-at-point-functions提到最前面,这个是不是意味着开启company-mode时我补全最前使用的就是她这个后端呢?但是我如何将completion-at-point-functions和citre联系起来呢,citre是ctags的前端的话,他和company有什么联系呢?
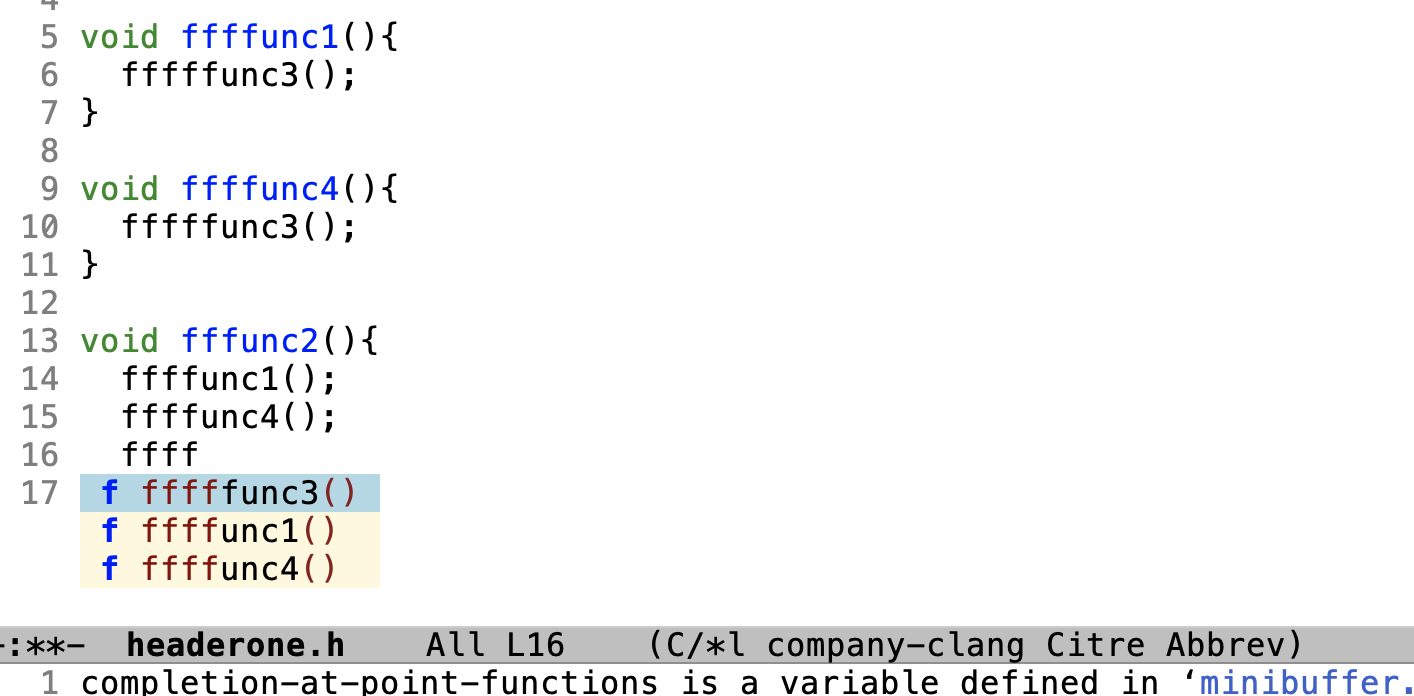
下面是我的补全截图:
求教
2.
completion-at-point-functions和
completion-at-point有什么区别呢
如果需要更多信息,麻烦指出来,谢谢😅
kinono
2
completion-at-point-functions (capf)是 Emacs 提供的补全机制。你直接 Call completion-at-point (C-M-i) 就可以使用它。
company 给 capf 做了个弹出式的 UI。所以这个关系是:Citre 提供了一个 capf 后端,company 提供了个 capf 的 UI。Emacs 自带的 completion-at-point 也是一个 capf 的 UI。Citre 并没有和 company 有什么直接的关系。
想用 Citre + company 的话,你需要
(setq company-backends '(company-capf ...其他备用的后端...))
仔细读一下 company-backends 的文档应该就可以理解了。
PS:看到楼主在 GitHub 的 issue 了  谢谢你请我喝咖啡!最近没时间开发 Citre,也没空修文档,但楼主有任何问题的话可以私信我。
谢谢你请我喝咖啡!最近没时间开发 Citre,也没空修文档,但楼主有任何问题的话可以私信我。
4 个赞
补一些citre作者对我的更深入的解释:
你的理解都是对的。
company-capf又是什么呢
是 company 的一个后端。
emacs如何知道我补全的时候使用citre后端呢
只要打开 citre-mode ,Citre 就会在 completion-at-point-functions 里注册 Citre 提供的后端函数,然后所有 capf 的前端就可以展示 Citre 提供的结果。
事实上,在整个过程中信息的流动是很简单的,就是 Citre 根据光标周围的信息询问 readtags,readtags 把 tag 交给 Citre,Citre 再把 tag 整理成补全结果交给 Emacs 展示。这里其实每个工序都可以写成一个函数,然后后面的函数依赖前面的函数,这样一直从最底下建造到 UI 层面上。这是非常基本、自然、有效的软件构建方式。
为什么会有这么多「前端后端」的说法呢,因为我们逐渐发现某些「后面的工序」是有通用性的,比如不管我的补全是来自 tags、LSP、还是什么其他的方式,我都希望用统一的 UI 来展示它们。用具体的例子来说:当用户 call completion-at-point 时,这个函数又会调用 completion-at-point-functions 中的函数来获取补全结果,然后绘制一个 UI 来显示它。那它怎么知道怎样 call completion-at-point-functions 中的函数呢?于是它就对这里的函数行为 制定一些规约 ,比方说(一个极简化的情形)「你这个函数必须是一个无参数的函数,当被调用时应当返回在当前光标位置下合适的补全结果,结果必须是一个字符串组成的列表」。这个「满足一定规约的函数」就是一个 capf 后端。
事实上这个就叫做「依赖倒置」。按正常的工序顺序来构建软件的话,应该是后面工序的函数依赖前面工序的函数。重点是理解「依赖」意味着什么:A 依赖于 B 意味着 B 的行为变化时,A 可能要跟着变化才能继续工作;但写 Citre 的补全部分的时候,是前面的工序(获取补全)依赖后面的工序(capf),因为:假如有一天 Citre 坏掉了,capf 并不会坏;但是假如 Emace 调整了 capf 后端的规约,Citre 就要跟着改。
如果上网找「依赖倒置」的资料的话,应该大多数都是 OOP 的,但其实用最基本的函数就可以做到。函数是非常神奇的,函数可以模拟 class,也可以模拟数据;在支持高阶函数语言中我们不需要绝大多数所谓的「设计模式」。这里当然要安利你看一下 SICP,多看看 SICP 对这些事都会有感觉。
那么我现在可以给你解释 company-capf 是什么了。首先它是一个 company 的后端(and again,是一个函数。在这里可以找到一个 company 后端的示例( company-citre )),也就是它符合 company 的规约:company 会给它一些约定好的参数,它会把约定好的结果返回给 company;其次它的结果来自 capf 后端,这意味着它会按照 capf 的规约来调用 capf 后端,然后把获取到的结果整理成 company 接受的形式。如果再以「工序」的视角来看,它是在 capf 后端之后,在 company 的 UI 之前的一道工序,只不过这里涉及两道「依赖倒置」,所以会让你觉得非常迷惑。
2 个赞