提交了一版本,虽然只有一个功能,但也可以试用一下。很遗憾,由于Chromium headless 行为和 headful 情况下不一致。导致当前版本只能使用 headful 模式,展示 Chromium 的窗口。有些干扰。
跟风试用了一下 ChatGPT, 并且尝试写了一个通过 Emacs 连接 ChatGPT 的 demo. 主要逻辑是:
- 利用 Python pycookiecheat (获取本地浏览器的 cookie ) + playwright 就可以自动化登录到 ChatGPT 页面。
- 利用 Websocket-bridge 让 Emacs 和 Python 程序通信,把 Emacs 的输入传递给 playwright, 然后异步等待结果传送回 Emacs
现在网络上已经有了许多 ChatGPT 非官方 API, 之所以选择使用 playwright + pycookiecheat 优点有:
- 可以自动登录,pycookiecheat 可以直接获取浏览器的 cookie, 也就是你在自己熟悉的浏览器上登录过 ChatGPT, 那么 Emacs 就可以直接使用了。不需要显示的在配置文件里指定用户名密码或是 Token
- 由于数据都是直接从 playwright 页面中抓取的。可以更好的控制。
- 其实核心是,我比较熟悉这一套流程。
使用体验,
- 把 ChatGPT 当作一个搜索引擎还是不错的,不过对话尽可能细致才可能得到有用的结果,如果是抽象的问题,它可能会瞎说。
- 慢,是真的慢。所以它的页面是滚动式返回数据。如果等它的数据完全收到之后再返回给 Emacs, Emacs 会等好久。
目前就实现了一个命令:ws-chat-gpt-input 输入字符串,发送给 chatGPT
发送完请求之后,因为是异步的,不会卡住 Emacs, 但需要很久才能返回完整信息。你就可以做别的事情了,等呀等,十几秒之后:
又是一个挖坑贴。分享一下我的体验与开发 DEMO 的记录。但暂时还未有提交的代码。
寻求一下大家的想法。
- ChatGPT 的可能的使用场景?
- 以及如果想要在 Emacs 下访问 ChatGPT, 怎样的交互逻辑比较合适?
例如 ChatGPT 返回是真的慢,因此可以选择和页面一样,一点点的返回,一点点的展示。这样等着就不那么着急。但我觉得实际,没什么意义,全部结果都出完了,再看完整的信息反而比较合适。
另外,如果没法注册 ChatGPT 怎么办?其实是有万能的淘宝的。就是不知道有没有隐私泄漏问题。 
10 个赞
ksqsf
2
- 解释一段代码是什么意思 (特别是像汇编语言这种很有需要)
- 根据一段描述生成一段代码 etc
edit: 还有就是……替代 M-x doctor (
3 个赞
Python 打开了Emacs和外界协作的潘多拉魔盒呀, 大佬又给自己挖了一个巨坑。
我觉得 ChatGPT 有几个用处:
-
当一个人写代码的时候, 把不知道怎么修的代码给 ChatGPT, 问它怎么修复? 反正你也不知道怎么修, 也不用嫌弃它慢, 就把它当作一个黄鸭子, 让它自言自语, 说不定真的还启发你怎么修复bug
-
写项目材料需要收集技术材料的时候, 可以通过思维导图来问它, 思维导图的每一个节点就是问题标题, 它回答的内容就是文档素材, 都回答完成以后再转换成一个 Word 文档, 可以大量节省自己搜集素材格式化文风的工作, 这种就让它默默的干吧
-
大量文件名称需要重按照某个风格重命名的时候, 让它慢慢干好, 这种人工智能应该比键盘宏好用多了
2 个赞
Nasy
7
能保持长连吗?chatgpt 的一个有意思的地方就是上下文有关
ChatGPT 还有个用处:提高用户提问水平。
问题决定答案。能不能得到期望的答案,取决于有没有把问题描述清楚。如果能把这种观念根植人心,真是一件大好事。
也许未来的公司企业机关单位,招人不要求会写会算、现场手写反转二叉树,就看你是否懂得与 AI 交流。提得一手好问题,是未来的核心竞争力。
3 个赞
Nasy
10
不是说一个问题一个网页啦。
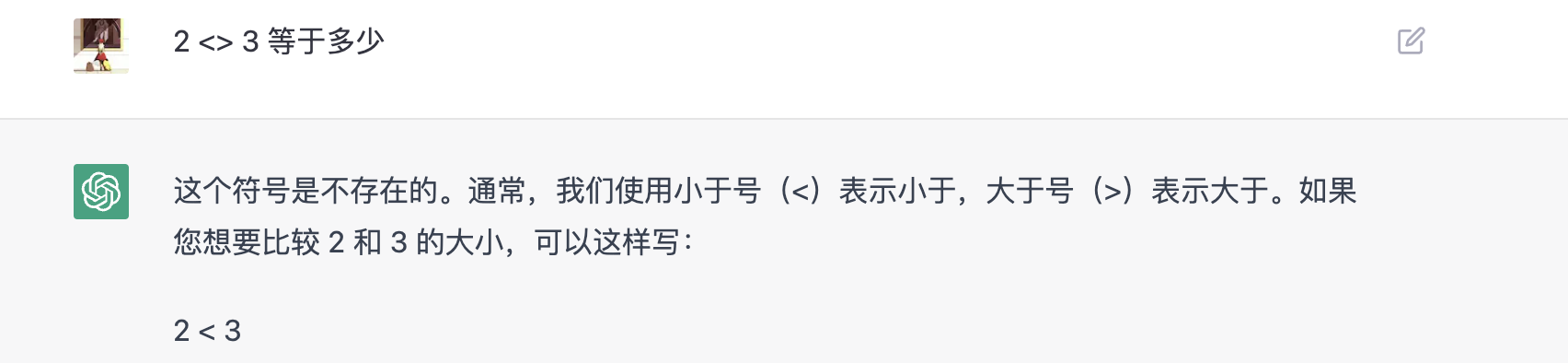
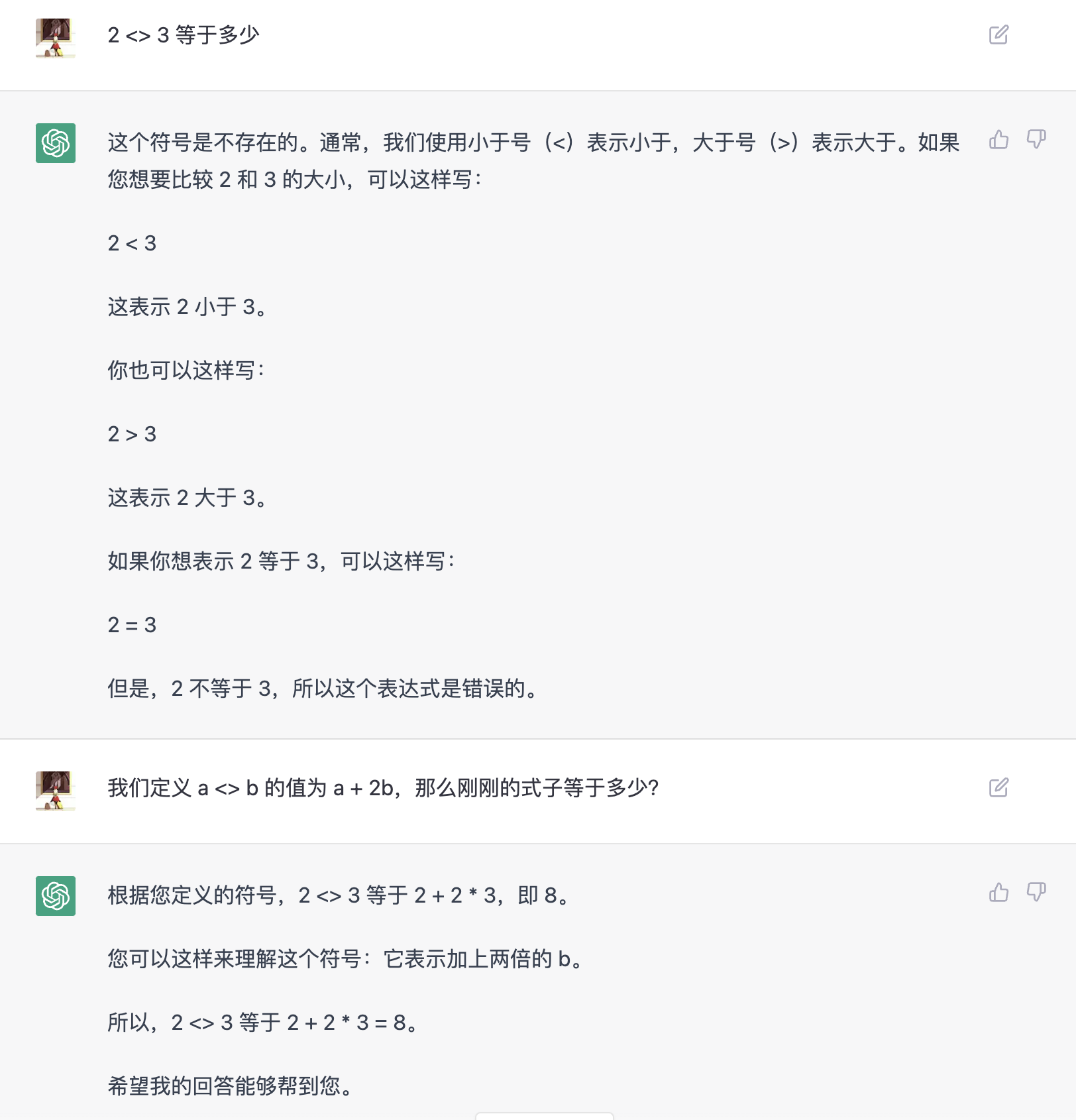
是说,比如可以在第一个对话里面告诉他 a <> b = a + 2b,然后,下一个对话直接说 3 <> 5 等于多少之类的。
如果一个问题一个网页,那对话就没办法连贯起来,就没多少意义了。
我是说的这个意思, 更准确描述一下,一个buffer里面的所有问题都共享一个网页。
我说的一个网页就是不同 buffer 的问题要用不同的网页, 这样就可以隔离不同的上下文。
buffer 和 网页 以及 上下文是一体的。
ginqi7
13
你的提问好高级。引导式提问。
这个方式是可以实现的,实现的逻辑比较简单。实际上就是开一个看不见的 ChatGPT 网页,然后Emacs 和这个网页进行通信。
如果若干个问题,都是同一个网页通信,就是同一个上下文。
如果你需要切换新的上下文,就需要新开一个网页与它通信。
ginqi7
14
原以为,playwright + chromium 在 headless 模式下和headful 模式下行为是一样的。因此在 headful 模式下开发调试,正式提交时,试图使用headless 模式。结果,居然出错了。他们两者的行为居然不一致。先暂时忍受,启动chromium 窗口好了。
这时候可以用 deno-bridge 和 Puppeteer, Puppeteer 是完全用你系统安装的Chrome来登录页面的, 同时保持窗口不显示。
ginqi7
16
最初考虑使用Python 主要是我熟悉一个pycookiecheat 的包,可以方便的从日常使用的浏览器里捞cookies 就可以不用重复登录了。
刚刚搜索了一下,好像js 也有一个类似的:GitHub - bertrandom/chrome-cookies-secure: Extract encrypted Google Chrome cookies for a url on a Mac or Linux, 之前不知道为什么没有搜索到。
puppeteer 似乎还有一种获取Cookies 的方法,可以指定 userDataDir 只要和用户使用的日常浏览器是同一个用户目录,就可以共享Cookies 了。后续有时间可以试试。
浏览器领域的还是用 TypeScript 好, 特别是 deno 现在可以直接用 npm 包了, TypeScript 对于网页插件支持更好一点。
Python主要用于系统底层库和一些数学算法方面, 生态会更好一点。
ginqi7
18
日常使用 ChatGPT 来作为搜索引擎看起来没有太大问题。特别是写代码时,想要某个明确的功能,或者查看某个明确的方法。
目前遇到的问题有:如果第一次提问使用的是中文,那么后续英文提问,还是会返回中文答案。看起来中英文提问开启不同的窗口会比较合适。
2 个赞
有些场合可能比搜索引擎更好用。但搜索引擎还是无可取代。
透过搜索引擎你可以追溯到信息的源头。ChatGPT 给你的则是它重新组织的信息。
ginqi7
20
是的,搜索引擎给出的源头可以辅助你判断回答的正确性,而chatGPT 忽悠起人来,真是一本正经。一测试才发现不是那么回事。看起来,网上的那个Google+ChatGPT 的插件可能会比较靠谱。搜索的时候把google 结果和chatGPT 的回答都列出来。
2 个赞