SPQR
1
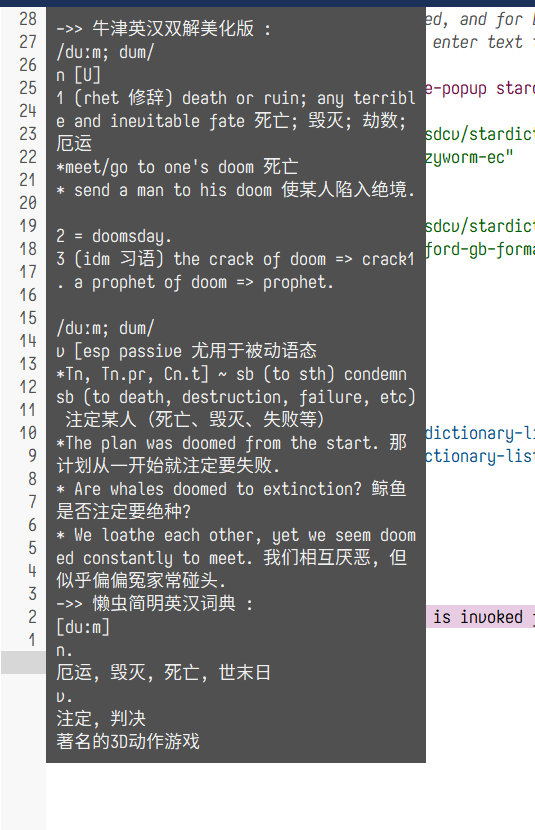
windows上sdcv有点小bug,比如不能正确识别环境变量LANG,导致词典列表是乱码等等。。于是打算找找有没有直接解析字典文件的emacs包,找了一下还真有。
所以就在这个script基础上增加了一些东西,让它体验和sdcv接近
Repo:https://github.com/pRot0ta1p/stardict.el
我自己用起来感觉还行  ,有个缺点就是添加词典的时候需要算hash-table,可能需要卡几秒,查词速度比sdcv要慢一些,不过不至于慢到影响使用的程度。。所以我抄了一下doom-emacs里面的
,有个缺点就是添加词典的时候需要算hash-table,可能需要卡几秒,查词速度比sdcv要慢一些,不过不至于慢到影响使用的程度。。所以我抄了一下doom-emacs里面的add-transient-hook!这个macro,让字典加载可以defer到第一次查词之前。
有一个优点就是因为查词的时候emacs直接打开字典文件搜索,所以只要让emacs以utf-8打开文件,就能避免乱码
8 个赞
试了一下,报错:Wrong type argument: integer-or-marker-p, nil
该从哪儿入手解决呢?
SPQR
3
我的锅 ,我把一个变量初值搞错了  ,你要不pull 一下最新版再试试?
,你要不pull 一下最新版再试试?
 还是不行啊
还是不行啊
要么出现 The word: [xxxx] is not found in xxxx词典,要么还是上面那句 
SPQR
5
我emacs -Q试了一下没法复现,能发一下backtrace和配置吗?
这个包真是我们这种工作电脑没管理员权限的用户的福音啊 
SPQR
9
1 个赞
SPQR
13
从github搬家到codeberg的时侯弄丢了。。。直接用原来的版本吧 EmacsWiki: stardict.el ,我当时的修改主要是加了用posframe显示查询结果的功能,自己写一个应该不难。
zebra
15
我把自己魔改的stardict放在我的配置里了 链接
现在可以在光标处取词或者prompt取词, 能够粗略处理 ing, ed, s 等屈折变化.
因为我是在emacs android上用的, 屏幕太小, 我没有用posframe, 而是直接切换到一个专门的buffer. 不过要改为posframe应该也好改.
1 个赞
zebra
17
加载了汉英词典之后应该可以(我还没试过),词典可以在星际译王作者的网站下载:链接
zebra
19
我试了一下确实不行, 抱歉! 疑似是 stardict-open-1 函数读取索引 (idx文件) 时未能正确地将编码转为汉字, 因为每个索引现在是这个样子: "\344\270\200\342\200\246\344\270\200\342\200\246" (6559 . 995). 字符串里应该是几个UTF-8汉字.
我自己不是 stardict.el 的作者, 对汉字编码转换不了解, 尝试在读取idx文件后在临时buffer里运行 (recode-region (point-min) (point-max) 'utf-8 'no-conversion) 但报错, 有空再看看. 要是坛里有大佬指点一下就太好了.
xiaoC
20
没关系,知道你不是作者。我有空也看看,如果有后面有进展,再一起分享