从去年开始 gptel 就在测试 tools,最近 0.98 终于正式推出了 tools 支持。不过有点惊讶的是论坛里好像没多少人玩这个,或者就是在等 MCP。其实直接用 elisp 写点 tools 也挺好玩的,而且 得益于 Emacs 强大的现有生态,tool 其实非常好写 。
下面列举两个比较简单的例子,也欢迎大家分享自己写的纯 elisp 的 tool。
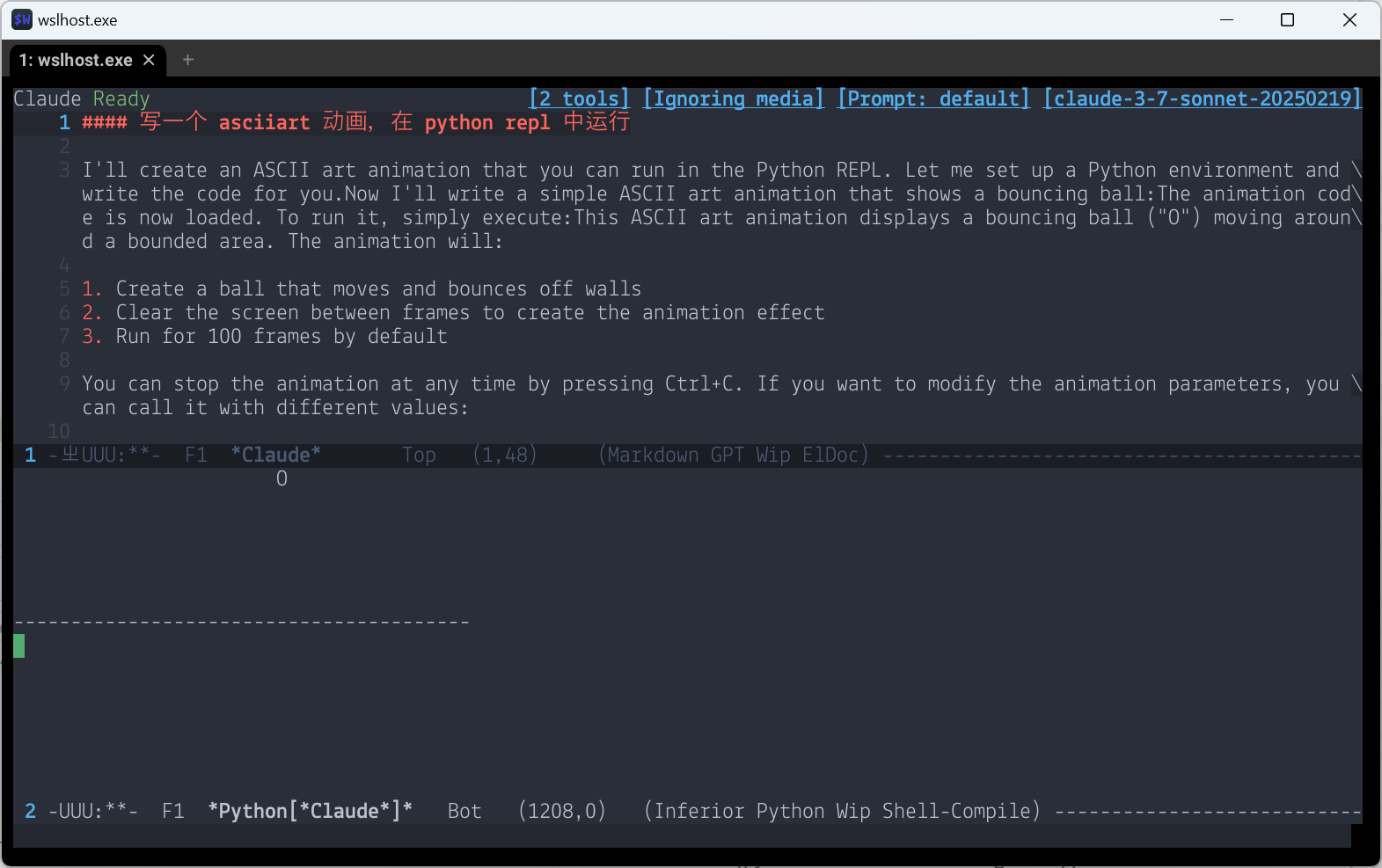
自动操纵 Python REPL
python.el 的 run-python 恰好可以创建一个 与 buffer 关联的 Python REPL。所以很轻松就能实现这样的效果:
(gptel-make-tool
:name "create_python_repl"
:function (lambda ()
(run-python nil t)
(pop-to-buffer (python-shell-get-buffer)))
:description "Create a new python repl for this session"
:args nil
:category "emacs")
(gptel-make-tool
:name "send_python_to_repl"
:function (lambda (code)
(python-shell-send-string code))
:args (list '(:name "code"
:type string
:description "python code to execute"))
:description "Send some python code to the python repl for this session and execute it"
:category "emacs")
这个玩法还可以进一步扩展,比如把结果也反馈回去,就可以让 LLM 自动调试/自动完善代码了。
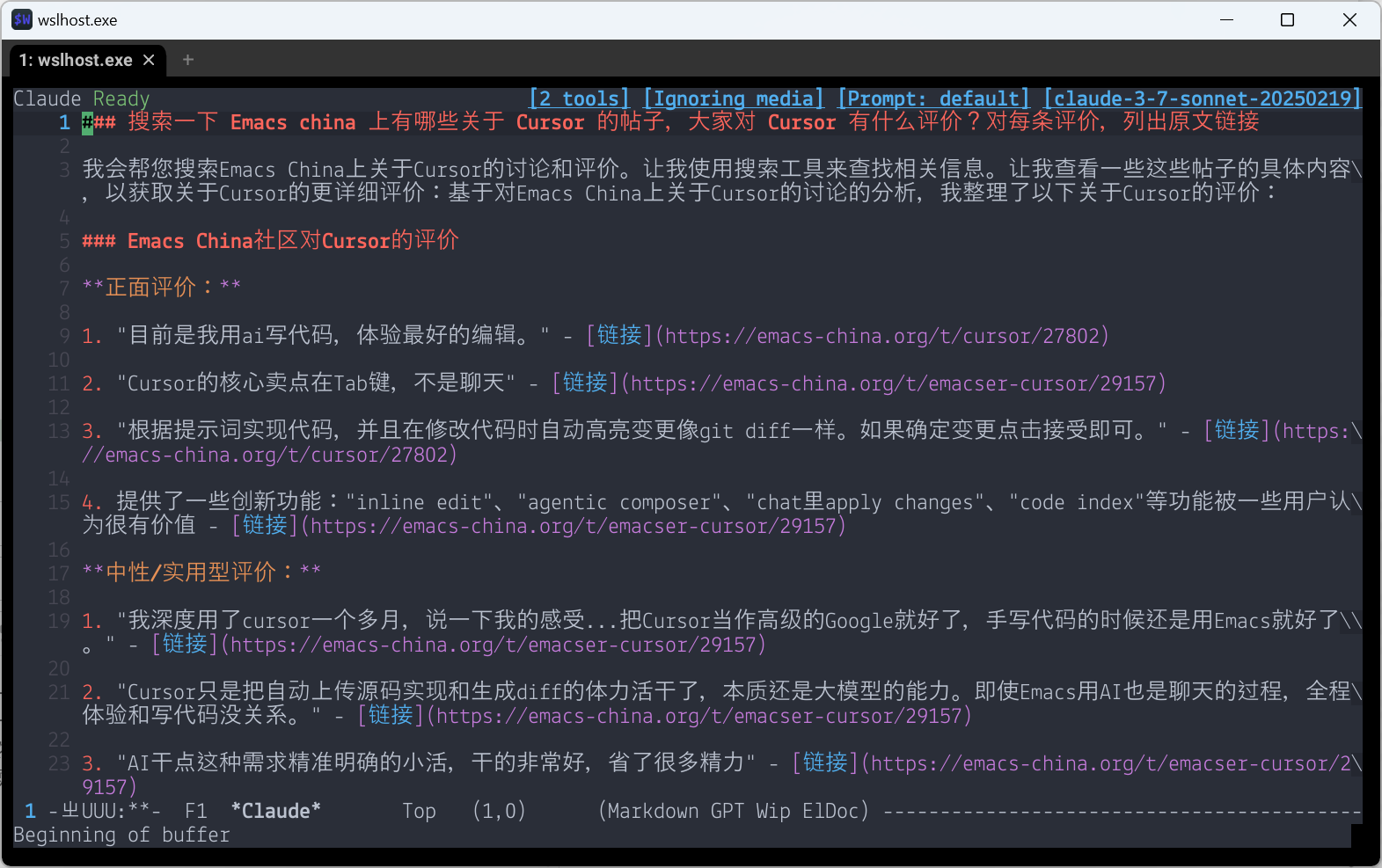
自动搜索和阅读网页
(并且是异步的,可以保留外链)
最近用过一些带联网的 LLM,但是都感觉笨笨的:
- 虽然可以搜索,但缓存了老页面,还没法手动强制刷新;
- 想手动提供参考信息,只能想办法让 AI 自己搜索到这个页面,而不能直接提供 URL 让 LLM 自己打开阅读。
于是自己定义两个 tool 一个用来读页面,一个用来搜索。这里用 Tavily 搜索 API。读页面提取纯文本,就简单用 shr 搓一个,足够用,甚至还能保留外部链接!(这里就体现出了 Emacs 生态的强大优势)两个配合起来可以实现非常美妙的效果:LLM 可以自动搜索到最新的结果,然后自动打开页面仔细阅读,而不是像很多 LLM app 一样读一下摘要或者缓存的老结果就结束了。
;; 你需要定义一个 tavily-api-key 函数
(gptel-make-tool
:category "web"
:name "search"
:async t
:function (lambda (cb keyword)
(tavily-search-async cb keyword))
:description "Search the Internet"
:args (list '(:name "keyword"
:type string
:description "The keyword to search")))
(gptel-make-tool
:category "web"
:name "fetch_url_text"
:async t
:description "Fetch the plaintext contents from an HTML page specified by its URL"
:args (list '(:name "url"
:type string
:description "The url of the web page"))
:function (lambda (cb url)
(fetch-url-text-async cb url)))
(defun tavily-search-async (callback query &optional search-depth max-results)
"Perform a search using the Tavily API and return results as JSON string.
API-KEY is your Tavily API key.
QUERY is the search query string.
Optional SEARCH-DEPTH is either \"basic\" (default) or \"advanced\".
Optional MAX-RESULTS is the maximum number of results (default 5)."
(let* ((url "https://api.tavily.com/search")
(search-depth (or search-depth "basic"))
(max-results (or max-results 5))
(request-data
`(("api_key" . ,(tavily-api-key))
("query" . ,query)
("search_depth" . ,search-depth)
("max_results" . ,max-results))))
(plz 'post url
:headers '(("Content-Type" . "application/json"))
:body (json-encode request-data)
:as 'string
:then (lambda (result) (funcall callback result)))))
(defun fetch-url-text-async (callback url)
"Fetch text content from URL."
(require 'plz)
(require 'shr)
(plz 'get url
:as 'string
:then (lambda (html)
(with-temp-buffer
(insert html)
(shr-render-region (point-min) (point-max))
(shr-link-to-markdown)
(funcall callback (buffer-substring-no-properties (point-min) (point-max)))))))
(defun shr-link-to-markdown ()
"Replace all shr-link in the current buffer to markdown format"
(goto-char (point-min))
(while (setq prop (text-property-search-forward 'shr-url))
(let* ((start (prop-match-beginning prop))
(end (prop-match-end prop))
(text (buffer-substring-no-properties start end))
(link (prop-match-value prop)))
(delete-region start end)
(goto-char start)
(insert (format "[%s](%s)" text link)))))
用 gptel 可以先用总结能力强的模型搜索资料并总结,然后换一个写作能力强的模型来创作,这在其他与模型绑定的 app 中似乎是无法做到的(或者要自己手动复制粘贴)。