新问题 我想查找项目下所有的中文 通过正则 但是好像不能用
I try #-e [\u4e00-\u9fa5] or #-- -e [\u4e00-\u9fa5]
我又回来了 正则怎么支持 请问
现在默认 search-project 就是全局搜索 所有文件都搜
如何能过滤一下结果 比如 只搜索lua 搜索结果中排除xxx
文档和issues 都翻烂了没找到 伸手问下大佬们 感谢
新问题 我想查找项目下所有的中文 通过正则 但是好像不能用
I try #-e [\u4e00-\u9fa5] or #-- -e [\u4e00-\u9fa5]
我又回来了 正则怎么支持 请问
现在默认 search-project 就是全局搜索 所有文件都搜
如何能过滤一下结果 比如 只搜索lua 搜索结果中排除xxx
文档和issues 都翻烂了没找到 伸手问下大佬们 感谢
你是在全文搜索啊,那我不知道了,我以为你只是要搜文件。 那要看你用的什么工具?grep,rg?应该有–exclude的选项吧
后台应该是 rg 只是这个参数不知如何传递 直接输入会被识别成搜索内容
这个前置参数也只能排除文件吧,好像不是你想要的排除文本内容呢
没事 我还是在找找吧
我还是去提issues
我没用过doom,你可以去问问。
可以参考 consult 的 wiki
确实可以 感谢 大佬也给出了同样的解决方案
another question
I want to find all Chinese in the project by regular expression
I try #-e [\u4e00-\u9fa5] or #-- -e [\u4e00-\u9fa5]
我又回来了 正则怎么支持 请问
直接 #[\u4e00-\u9fa5]+ 不可以吗?
我这里可以啊
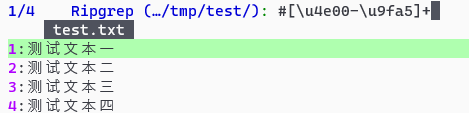
test.txt 内容是
测试文本一
测试文本二
测试文本三
测试文本四
test text
最后一行的英文没有显示在结果里。
文档里提到
! with error face, failure, process exited with a nonzero error code.
看看 *consult-async* buffer 里有没有错误信息。
或者再看一下文件编码是不是 utf-8。