使用 Org roam 做笔记,平时使用 counsel 对笔记文件夹中的 Org 文本文件进行文本搜索,但有时需要参考一下其他文档比如 PDF,Office 文件,这时候就需要到专门集中存放PDF,Office 的文件夹中使用能够对它们内容进行搜索的工具搜索,然后查看自己所需的页面。
昨晚在Github发现一个项目,
rga: ripgrep, but also search in PDFs, E-Books, Office documents, zip, tar.gz, etc. - GitHub - phiresky/ripgrep-all: rga: ripgrep, but also search in PDFs, E-Books, Office documents, zip, tar.gz, etc.
它可以对一个文件夹中的压缩包,PDF,Office 文件等进行搜索。而我想如果能将该工具整合到懒猫的 blink-search中就好了。将平时存放 PDF 的文件夹设置为 Common Directory,使用 ripgrep-all 搜索关键字,返回文档名和 Page Number,需要预览页面时使用 EAF 打开该页面。
不知道有没有大神对此想法有兴趣,尝试实现一下,顺便惠泽一下大众。
个人不是程序员,刚才看了懒猫 blink-search 的后端的实现,发现看不懂。
虽然我会一点点 Python 和 Elisp,写过一点点插件,不想当伸手党,无奈才疏学浅,力有不逮。
3 个赞
我最开始想写的,但是现在都看纸质书,自己太懒了,不想写,rga确实有用。
我自己要看的书单账太多了,最近没时间大规模投入elisp编程上,抱歉。
发现 helm 有个 helm-ff-run-pdfgrep 可以一定程度满足我的需求。
安装好依赖命令 pdfgrep。
在 Emacs 中加入以下配置:
(setq helm-pdfgrep-default-read-command 'eaf-open)
(defun helm-pdfgrep-action-1 (_split pageno fname)
(let* ((buffer-id)
(pdf-file-name (substring-no-properties fname)))
(run-hook-with-args-until-success 'helm-pdfgrep-default-read-command pdf-file-name)
(setq buffer-id
(car
(->> (eaf--get-eaf-buffers)
(-map
(lambda (buffer) (with-current-buffer buffer
(when (string= (file-name-nondirectory pdf-file-name) (buffer-name))
eaf--buffer-id))))
(-filter (lambda (x) (not (equal x #'nil)))))))
(eaf-call-async "execute_function_with_args" buffer-id "jump_to_page_with_num" (format "%s" pageno))
))
在指定的文件夹下,运行 C-x c C-x C-f 运行 helm-find-files,输入 PDF 过滤出所有的 PDF 格式文件,M-a 选中所有的待选项目,M-i p 运行 helm-ff-run-pdfgrep 命令,输入需要在选中的 PDF 文件中搜索的关键字,如示意图中的 :“HMU”。
C-n,或者 C-p 选择需要预览的结果,然后使用 TAB 调用 helm-pdfgrep-action-1 进行预览。
现在的问题是 eaf 在第一次打开 PDF 时,无法按照我写的代码跳转到指定的页面,如图中所示我希望预览的是文件"HMU 更换.pdf"的第 5 页,然而第一打开 PDF 时,跳转到的是上一次打开该 PDF 所在的第 6 页,需要再按一次 TAB 键,让 helm-pdfgrep-action-1 中的 (eaf-call-async "execute_function_with_args" buffer-id "jump_to_page_with_num" (format "%s" pageno))
再运行一次,才会调到第 6 页。
也就是说第一次预览时 (eaf-call-async "execute_function_with_args" buffer-id "jump_to_page_with_num" (format "%s" pageno))
没有按照设想的运行进行跳转。
我猜是 EAF 还没完全打开 PDF,就运行该代码,所以无法跳转,所以如何实现在 EAF 打开 PDF 后再运行 (eaf-call-async "execute_function_with_args" buffer-id "jump_to_page_with_num" (format "%s" pageno))呢?
我查看了 eaf-pdf-viewer 的源代码,发现了 (add-hook 'eaf-pdf-viewer-hook 'eaf-pdf-imenu-setup) 中 eaf-pdf-viewer-hook 这个 hook ,但是不知道如何修改我自己的配置。
eaf-pdf-viewer本身是可以记录上一次地阅读进度的,不会存在第一次打开无法跳转进度的问题。
看看eaf-pdf-viewer怎么打开上次进度的代码就可以解决你的问题。
你先尝试研究,不行我才告诉你怎么做,这样你可以有所成长。
我把 eaf-pdf-viewer.el 所有函数都看了,实在看不出来是哪里实现了恢复阅读进度的功能。
我找到了存放 PDF 阅读进度的 session.json 文件,里面的内容是:
"/Users/c/Library/Mobile Documents/iCloud~QReader~MarginStudy/Documents/Python/Design_Patterns_Explained_Simply.pdf": "199.87666666666664:2.2077452044878756:fit_to_width:False:0"。
按照我的理解 “199.87666666666664:2.2077452044878756:fit_to_width:False:0” 分别对应的是
scroll_offset, scale, read_mode, inverted_mode。
通过 self.buffer_widget.scroll_offset = float(scroll_offset) 来恢复进度。
eaf 恢复阅读进度并不是通过 (eaf-call-async "execute_function_with_args" buffer-id "jump_to_page_with_num" (format "%s" pageno)) 这样跳到特定页面的方法。
所以和我预期的行为不一致。因为 helm-ff-run-pdfgrep 的结果返回中包含一个 page number,所以还是希望通过跳转 page number,而不是通过 scroll_offset。
kongds
2022 年11 月 21 日 08:30
10
我也有类似的需求,所以简单基于blink-search 和 pdf-tools写了一个,待会提交一下PR试试。
不过因为我用的是pdf-tools,不是eaf-pdf-preview,所以可能还得补充一下eaf-pdf-preview这块的高亮和定位
2 个赞
@czqhurricane
首先更新 EAF Pdf Viewer 到 Add eaf-pdf-jump-to-page API. · emacs-eaf/eaf-pdf-viewer@ac10f2e · GitHub , 提供了一个 eaf-pdf-jump-to-page 的API, 自动打开文档并定位到某一页。
再更新 blink-search 到 Support EAF pdf viewer. · manateelazycat/blink-search@130f804 · GitHub
接着设置 (setq blink-search-grep-pdf-backend 'eaf-pdf-viewer)
就可以直接 blink-search 搜索后用 EAF Pdf Viewer 跳到对应的页数。
大佬出手就是不一样,我憋了半天,模仿来模仿去,写不好。新加的函数 eaf-pdf-jump-to-page 可以和 helm-ff-run-pdfgrep 完美配合,这里留下记录,供他人需要。
(setq helm-pdfgrep-default-read-command 'eaf-pdf-jump-to-page)
(defun helm-pdfgrep-action-1 (_split pageno fname)
(let* ((pdf-file-name (substring-no-properties fname)))
(run-hook-with-args-until-success 'helm-pdfgrep-default-read-command pdf-file-name pageno)))
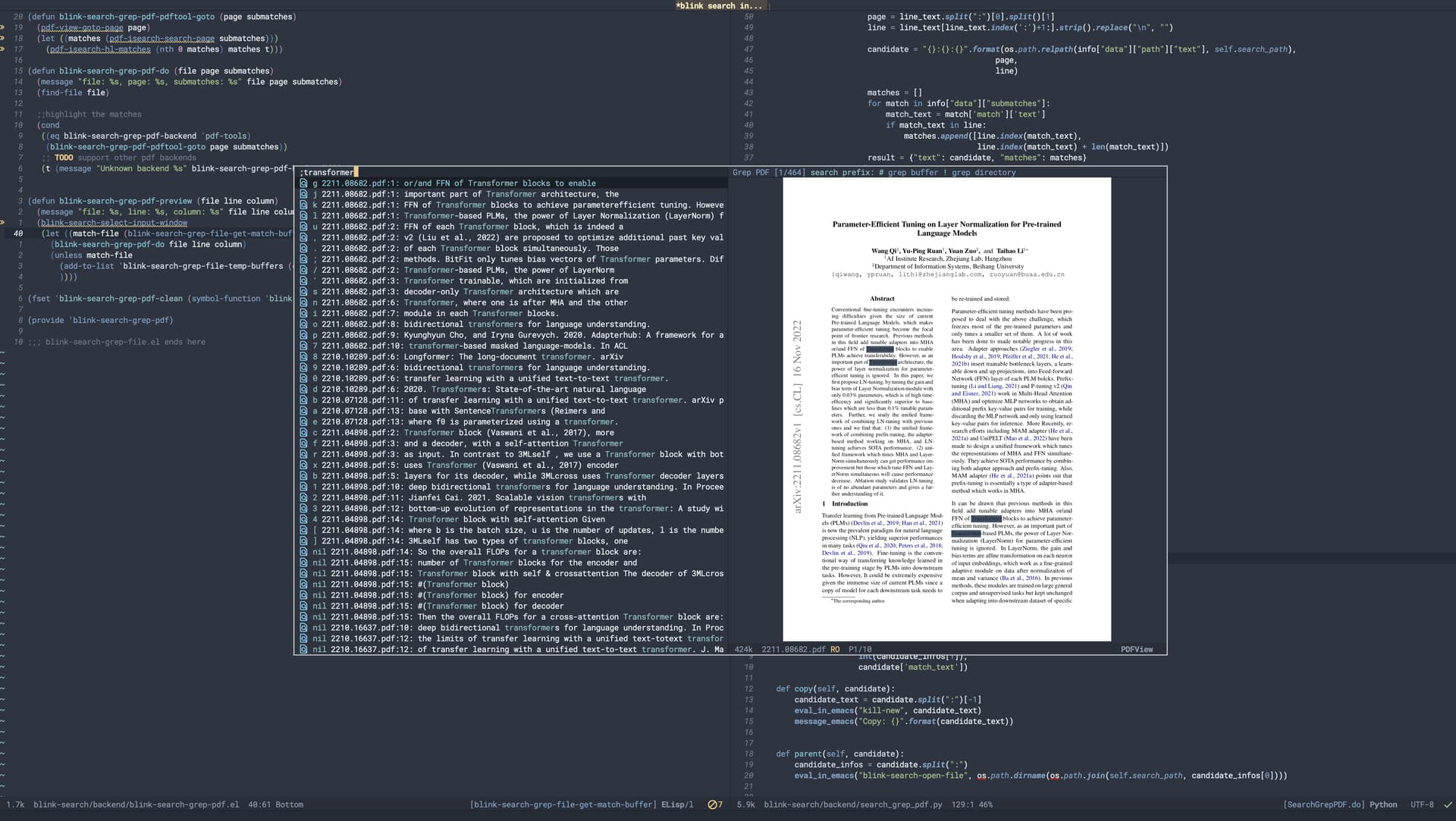
(defun blink-search-grep-pdf-do (file page submatches)
;;highlight the matches
(cond
((and (eq blink-search-grep-pdf-backend 'pdf-tools) (featurep 'pdf-tools))
(blink-search-grep-pdf-pdftool-goto file page submatches))
((and (eq blink-search-grep-pdf-backend 'eaf-pdf-viewer) (featurep 'eaf-pdf-viewer))
(eaf-pdf-jump-to-page file page))
;; TODO support other pdf backends
(t (message "Unknown backend %s" blink-search-grep-pdf-backend))))
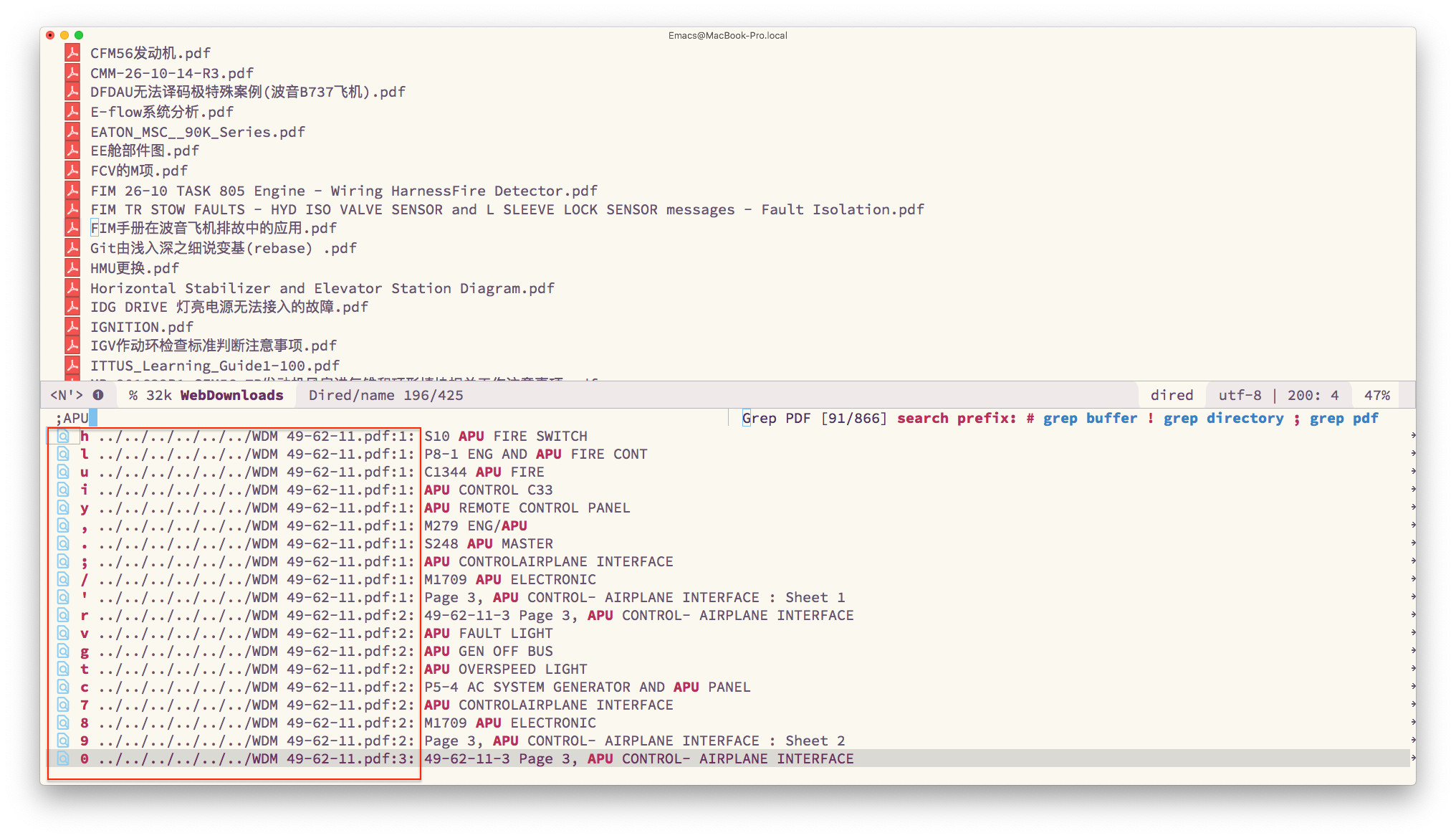
blink-search-grep-pdf-do 函数接受的第一个参数 file 路径过长时会变成:"~/Library/Mobile Documents/iCloud~QReader~MarginStudy/Documents/WebDownloads/../../../../../../WDM 80-11-11.pdf" 这种中间的部分路径变成省略号,导致 eaf-pdf-viewer 无法打开相应的文件。真实的路径是 /Users/c/Library/Mobile Documents/iCloud~QReader~MarginStudy/Documents/WebDownloads/WDM 80-11-11.pdf 。不知道为何如此?
截图中红框所示过长的路径变成省略号了?
需要设置 blink-search-grep-pdf-search-paths 解决。
kongds
2022 年11 月 21 日 16:00
16
没设置的话应该会用当前所在的路径去搜索,路径显示的话应该会用parse_rg_line去获得相对路径,不过不知道为啥会出现这种情况
还有个疑问要为 blink-search-grep-pdf-search-paths 设置多个路径怎么设置?
def init_dir(self, search_dir):
self.search_paths = get_emacs_var("blink-search-grep-pdf-search-paths")
self.search_paths = self.search_paths if self.search_paths else search_dir
if type(self.search_paths) is str:
self.search_paths = [self.search_paths]
self.search_paths 怎么从 blink-search-grep-pdf-search-paths 字符串变成列表?
能不能给个实例。
(setq blink-search-grep-pdf-search-paths "/Users/c/Library/Mobile Documents/iCloud~QReader~MarginStudy/Documents/WebDownloads")
kongds
2022 年11 月 21 日 16:05
18
(setq blink-search-grep-pdf-search-paths '("/Users/royokong/arxiv_papers" "/Users/royokong/papers"))
直接用elisp的列表就行了
1 个赞
是的,好像用 Emacs 的各种行业都有。我都记不清当初为啥用 Emacs 了😂。虽然我不是用 Emacs 写代码吃饭,但是论坛逛的很上头啊,经常能看到好玩的新东西。
论坛里面个个都是人才,说话又好听,超喜欢在里面的。
6 个赞