尝试了两个等宽字体,一个 sarasa ,一个 noto-cjk ,他们的中英文没有对齐的表现类似,不过字体本身应该是没有问题的,而且 describe-char 能够确定第一行和第二行是同一个字体:


Sarasa也不是在所有字号下面都能对齐,调整下字体大小试试?
调了 11 到 16 ,文本特征是一致的。
请在“我”和“啊”上分别M-x describe-char,并给出 完整 截图
a :
position: 16 of 16 (94%), column: 9
character: a (displayed as a) (codepoint 97, #o141, #x61)
charset: ascii (ASCII (ISO646 IRV))
code point in charset: 0x61
script: latin
syntax: w which means: word
category: .:Base, L:Left-to-right (strong), a:ASCII, l:Latin, r:Roman
to input: type "C-x 8 RET 61" or "C-x 8 RET LATIN SMALL LETTER A"
buffer code: #x61
file code: #x61 (encoded by coding system utf-8-unix)
display: by this font (glyph code)
ftcrhb:-GOOG-Noto Sans Mono CJK SC-normal-normal-normal-*-19-*-*-*-*-0-iso10646-1 (#xF6FD)
Character code properties: customize what to show
name: LATIN SMALL LETTER A
general-category: Ll (Letter, Lowercase)
decomposition: (97) ('a')
There are text properties here:
fontified t
wrap-prefix ""
我:
position: 5 of 16 (25%), column: 8
character: 我 (displayed as 我) (codepoint 25105, #o61021, #x6211)
charset: chinese-gbk (GBK Chinese simplified.)
code point in charset: 0xCED2
script: han
syntax: w which means: word
category: .:Base, C:2-byte han, L:Left-to-right (strong), c:Chinese, h:Korean, j:Japanese, |:line breakable
to input: type "C-x 8 RET 6211"
buffer code: #xE6 #x88 #x91
file code: #xE6 #x88 #x91 (encoded by coding system utf-8-unix)
display: by this font (glyph code)
ftcrhb:-GOOG-Noto Sans Mono CJK SC-normal-normal-normal-*-19-*-*-*-*-0-iso10646-1 (#x4858)
Character code properties: customize what to show
name: CJK IDEOGRAPH-6211
general-category: Lo (Letter, Other)
decomposition: (25105) ('我')
There are text properties here:
fontified t
wrap-prefix ""
noto cjk 自己的中英文字体同字号的时候本来就不能对齐呀,宽度就不是严格的1:2
你是怎么判断的? Sarasa 表现也是一样的,你要怎么说?
补充一下新装的 gvim :
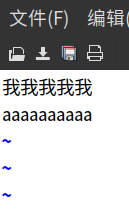
为了防止有人认为别的软件针对字体进行了调整,我又放上 vscode 的图,上边是 sans ,下边是 monospace :
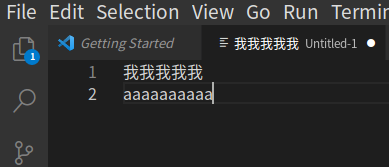
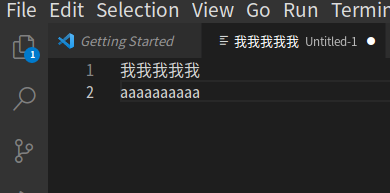
我尝试了又一下 firefox 和 gedit ,它们也不是对齐的,但特征和 emacs 不一致:

Emacs 中,第二行要宽一些,和这些 gtk 应用相反。不过我开始怀疑是 gtk 的问题。于是我通过 AUR 安装了 emacs-lucid ,发现文本和 emacs ( with gtk ) 一致,第二行宽一些。
我这里 sarasa 可以对齐,但不是所有的字号都行。
我调成了 18 号,确实可以对齐,但 10 到 17 都没有对齐。这也太别扭了吧。我不认为这样就是没问题了,不过暂时将就用着。。。
有空研究一下,我现在用的是 noto ,看看能不能打个 patch 啥的。